-
راهنمای تازه واردین
آشنایی با شرایط و قوانین مرجع
-

-
نوشتههای وبلاگ
-
-

-
موضوع ها
-
-
اطلاعیههای مرجع
-
-
برخی از فایلهای مرکز دانلود
-

ریال ۶٬۵۰۰٬۰۰۰
-

ریال ۴٬۵۰۰٬۰۰۰
-

رایگان
-

رایگان
-

رایگان
-
-

-
آمارهای وبلاگ
-
مجموع وبلاگها7
-
مجموع نوشتهها83
-
-
برترین مشارکت کنندگان
کسی تا کنون امتیازی در این هفته دریافت نکرده است.
-
برخی از حامیان و مجوزهای فعالیتی








-
انتخابهای ما
-

همه چیز در مورد مجوز و شرایط استفاده از کتابخانهٔ Qt
کامبیز اسدزاده ارسال شده توسط نوشته وبلاگ در ابزارها،
یکی از مهمترین و پرمخاطبترین سوألاتی که در مورد فریمورک کیوت پرسیده میشود، شرایط استفاده و مجوزهای مربوط به آن است؛ از آنجایی که این کتابخانه تحت پشتیبانی یک شرکت تجاری است، برخی از شرایط و قوائدی وضع شده است که در استفاده از آن باید دقت لازم را داشت. در این مقاله من قصد دارم به توضیحات و شفافسازی کامل در این خصوص بپردازم که امیدوارم از آن بهرهمند شوید.-
- 0 پاسخ
انتخاب شده توسط
کامبیز اسدزاده, -
-

چرا ساتوشی ناکاموتو ++C را برای ساخت بیتکوین انتخاب کرد و نظر سازندهٔ سیپلاسپلاس در این باره چیست؟
کامبیز اسدزاده ارسال شده توسط نوشته وبلاگ در فناوری،
فناوری مورد استفاده در بیت کوین نیز در نوع خود بی نظیر است. ناکاموتو استفاده از الگوریتم های ++C را برای طراحی این فناوری مالی انتخاب کرد، اما چرا؟-
-
- 0 پاسخ
انتخاب شده توسط
کامبیز اسدزاده, -
-

کدام سبک طراحی در کیوت، Qt Widgets یا Qt Quick؟
کامبیز اسدزاده ارسال شده توسط یک موضوع در کتابخانه کیوت (Qt)،
امروز نیاز دیدم یک توضیح در رابطه با تفاوتهای عمدهٔ فناوری ساخت و توسعهٔ رابطکاربری در نرمافزارهای تحت فریمورک کیوت ارائه کنم. در این مقاله من به دو سبک متفاوت با کارآیی و اهمیت آنها میپردازم و شما میتوانید بر اساس نیازمندی و برداشت خود از آن، یکی از فناوریهای لازم را انتخاب و ظاهر برنامهٔ خودتان را با آن آراسته کنید!-
- 0 پاسخ
انتخاب شده توسط
کامبیز اسدزاده, -
-

ترکیب کدهای ++C با وردپرس بدون شکستن کد آن
کامبیز اسدزاده ارسال شده توسط نوشته وبلاگ در برنامه نویسی،
سادهترین راه برای افزودن کد سفارشی به سایتهایی که بر پایهٔ وردپرس ساخته شدهاند، بدون شکستن کد آن چیست؟-
-
- 0 پاسخ
انتخاب شده توسط
کامبیز اسدزاده, -
-

نهاییسازی استاندارد ۲۳ (استاندارد ۲۶ در راه است)
کامبیز اسدزاده ارسال شده توسط نوشته وبلاگ در فناوری،
در این مقاله قصد داریم در رابطه با استاندارد ۲۶ و نهاییسازیهای ۲۳ یک جمعبندی داشته باشیم که بسیار در شناخت و بهروز رسانی سریع از پیشرفت این زبان را به ما نشان میدهد.-
- 0 پاسخ
انتخاب شده توسط
کامبیز اسدزاده, -
-

نهاییسازی ویژگیهای استاندارد ۲۳ و خلاصهای از جلسهٔ استانداردسازی WG21
کامبیز اسدزاده ارسال شده توسط نوشته وبلاگ در فناوری،
خلاصهای از جلسهٔ ماه جولای با هدف نهایی شدن استاندارد ۲۳ که نشان میهد پیشرفت بزرگی به عنوان ویژگیهای جدید استاندارد ۲۳ وجود دارد ارائه شده است.-
-
- 0 پاسخ
انتخاب شده توسط
کامبیز اسدزاده, -
-

جایزهٔ زبان برنامهنویسی سال TIOBE به ++C تعلق یافت!
کامبیز اسدزاده ارسال شده توسط نوشته وبلاگ در ابزارها،
در سالی که گذشت (۲۰۲۲)، سیپلاسپلاس محبوبترین زبان برنامهنویسی با رشد شاخص محبوبیت ۴.۶۲٪ انتخاب شد!-
-
- 0 پاسخ
انتخاب شده توسط
کامبیز اسدزاده, -
-

خلاصهای از ملزومات و نقشهٔ راه ساخت و ساز محصول نرمافزاری
کامبیز اسدزاده ارسال شده توسط نوشته وبلاگ در علم و دانش،
سلام و درود،
این اواخر راجع به مشورت و راهنماییها خیلی ساده به قضیه نگاه میشه، همه فکر کردن کشکه و فقط با دونستن JS یا QML میشه محصول ساخت. البته این مثال JS و QML یک مثال هست و این مسئله در همهٔ ابزارها و حول محور حوزهٔ کامپیوتر و نرمافزار به چشم میخوره، هرچند روی داستان ساده هست اما حتی پشت این کارهای ساده کلی زمان باید صرف بشه. همین گرفتن یک دادهٔ ساده از سمت سرور و تجزیه کردنش سمت JS نیاز به یک دانش خوب در مورد معماری Apiداره، نیاز به آگاهی از استانداردهای Http داره، نیاز به تخصص کافی در ریز به ریز مسائل داره، نیاز به آگاهی لازم در مورد شبکه و نحوهٔ مدیریتش داره، نیاز به درک خوب راجع به کلاسهای شبکه و نحوهٔ مدیریت بستهها داره و صدها جور مسئلهٔ دیگه.
یا راهنمایی نکنیم یا میکنیم همه چیز رو ساده نشون ندیم!
به خصوص برای کسایی که سالها یه چیز دیگه خوندن و الآن قراره وارد این حوزه بشن.
قشنگ واقعیت رو باید به نمایش گذاشت، و اگرنه به اشتراک گذاری چهارتا UI خفن که بگین با QML هم میشه کاری نداره، سه سوته میشه اینها رو طراحی کرد.-
-
- 2 پاسخ
انتخاب شده توسط
کامبیز اسدزاده, -
-

آیا زبان برنامهنویسی ++C قابل جایگزین شدن است؟
کامبیز اسدزاده ارسال شده توسط نوشته وبلاگ در فناوری،
یک سوأل بسیار مهم و پر مخاطب در بارهٔ زبانبرنامهنویسی سیپلاسپلاس در سالهای اخیر این است که «آیا جایگزینی برای این زبان وجود دارد و یا قابل جایگزین است»؟
در بسیاری از پاسخها نشان از گزینههایی مانند Go، Rust و D دیده میشود که بهتر است نسبت به نظرات متخصصهای برنامهنویسی به این موضوع پرداخته شود، ابتدا باید در نظر گرفت که هر ابزاری میتواند جایگزینی داشته باشد اما شرایط و نحوهٔ استفادهٔ آن در رابطه با نیاز متفاوت است.-
-
- 1 پاسخ
انتخاب شده توسط
کامبیز اسدزاده, -
-

رونمایی از اولین درگاه پرداختِ ارزی توسط بایننس
کامبیز اسدزاده ارسال شده توسط نوشته وبلاگ در فناوری،
ما ایرانیها به خصوص توسعهدهندهها در حوزهٔ فناوری همیشه با مشکلاتی دست و پنجه نرم میکنیم، قطعاً میتوان در این باره توضیحات بسیار جامعی ارائه کرد، اما یکی از این مسائل بحث محدودیتهای شدید در پرداخت به شیوهٔ ارزی و بینالمللی است و به همین خاطر به سختی میشود به مشتریان خارج از کشور خدمات ارائه و هزینهای در قبال آن دریافت کرد بنابراین، معمولاً دسترسی به ارائهٔ خدمات در خارج از کشور امکانپذیر نیست.
با تفکرِ به این که، روزی خواهد رسید درگاههای پرداختیِ فعلی به شیوههای کاملاً مردمی بدون در نظر گرفتن موقعیت، قومیت و سیاستهای خارجی در اختیار همگان قرار خواهند گرفت و این یعنی آزادی در دنیای تجارت، به گونهای که با اهداف و شعار این بستر و ارزهای دیجیتالی همخوانی داشته و به نظر میرسد پیشبینیها در رابطه با شکل و قالب پولهای نسل جدید واقعاً به این سمت سوق پیدا کند.-
- 2 پاسخ
انتخاب شده توسط
کامبیز اسدزاده, -
-
-
جهت درخواست مشاورهٔ تخصصی و استارتاپی (منتورینگ) پیام دهید.
-
موضوع ها
-
آموزش نصب و راه اندازی کتابخانه در ++C
توسط کامبیز اسدزاده، در برنامه نویسی در C و ++C
- کتابخانه
- سیپلاسپلاس
- (و 6 مورد دیگر)
- 0 پاسخ
- 26,504 بازدید
-
سیپلاسپلاس مدرن معرفی زبان ++C و مزیت آن نسبت به دیگر زبانهای برنامهنویسی
توسط کامبیز اسدزاده، در برنامه نویسی در C و ++C
- 0 پاسخ
- 20,532 بازدید
-
سیستم مدیریت محتوا ساخت و توسعهٔ وبسایت توسط ++C
توسط کامبیز اسدزاده، در برنامه نویسی در C و ++C
- سیپلاسپلاس
- وبسایت
- (و 3 مورد دیگر)
- 13 پاسخ
- 19,377 بازدید
-
معرفی و راهاندازی OpenCL
توسط کامبیز اسدزاده، در کتابخانهی OpenCL
- نصب
- اوپن سی اِل
- (و 2 مورد دیگر)
- 0 پاسخ
- 12,494 بازدید
-
اخبار به روز رسانیها و انتشار محیط توسعهٔ Qt Creator
توسط کامبیز اسدزاده، در کتابخانه کیوت (Qt)
- qt creator
- محیط توسعه
- (و 1 مورد دیگر)
- 9 پاسخ
- 12,363 بازدید
-
سیپلاسپلاس مدرن چرا و چگونه باید ++C را یاد بگیریم؟
توسط کامبیز اسدزاده، در برنامه نویسی در C و ++C
- سیپلاسپلاس
- مدرن
- (و 4 مورد دیگر)
- 0 پاسخ
- 12,040 بازدید
-
سیپلاسپلاس مدرن قابلیتهای ممتاز و پیشرفتهٔ ++C در استانداردهای جدید
توسط کامبیز اسدزاده، در کتابخانههای استاندارد STL
- 4 پاسخ
- 11,714 بازدید
-
- 0 پاسخ
- 7,952 بازدید
-
- 19 پاسخ
- 7,599 بازدید
-
- 0 پاسخ
- 6,573 بازدید
-
-
فایل
-
موضوع ها
-
سوال: خطای first dependency dropped در اجرای پروژه سیپلاسپلاس
توسط سید معین حسینی، در نصب و اسقرار
- در انتظار بهترین پاسخ
- 0 رای
- 3 پاسخ
-
سیپلاسپلاس مدرن قابلیتهای ممتاز و پیشرفتهٔ ++C در استانداردهای جدید
توسط کامبیز اسدزاده، در کتابخانههای استاندارد STL
- 4 پاسخ
- 11,714 بازدید
-
- 0 رای
- 4 پاسخ
-
کتابخانهٔ Boost: یک راهکار قدرتمند برای توسعهٔ برنامههای سیپلاسپلاس
توسط کامبیز اسدزاده، در کتابخانه بوست (Boost)
- 0 پاسخ
- 2,741 بازدید
-
رابطکاربری کدام سبک طراحی در کیوت، Qt Widgets یا Qt Quick؟
توسط کامبیز اسدزاده، در کتابخانه کیوت (Qt)
- qt quick
- qt widgets
- (و 7 مورد دیگر)
- 0 پاسخ
- 4,270 بازدید
-
- 0 رای
- 1 پاسخ
-
- 10 پاسخ
- 3,206 بازدید
-
- 1 پاسخ
- 1,860 بازدید
-
سوال: بهترین پایگاه داده برای سی پلاس پلاس چیه؟
توسط Hamed Ashournezhad، در سوالات عامیانه در رابطه با ++C مدرن
- در انتظار بهترین پاسخ
- برنامهنویسی
- برنامه سیپلاسپلاس
- (و 2 مورد دیگر)
- 0 رای
- 1 پاسخ
-
سوال: خطا در اجرای qt creator8 و assistant در کیوت 6.4
توسط chikar، در عمومی و دسکتاپ
- در انتظار بهترین پاسخ
- 0 رای
- 4 پاسخ
-











آیاواستریم
نوشتههای ویژه
-
فرق بین کامپایل استاتیک و داینامیک
توسط کامبیز اسدزاده
فرق بین کامپایل استاتیک و داینامیک قبل از اینکه فرق بین ایستا (استاتیک) - Static و پویا (داینامیک) - Dynamic را بدانیم لازم است در رابطه با چرخهٔ زندگی نوشتن یک برنامه و اجرای آن آشنا شویم. هر برنامه برای اولین بار توسط یک محیط توسعه (Editor) یا IDE توسط برنامهنویسان انتخاب و به صورت فایل متنی قابل ویرایش میباشد. سپس فایل متنی که شامل کدهای نوشته شده توسط برنامهنویس تحت زبان برنامهنویسی مانند C، C++ و غیره... میباشد توسط کامپایلر به کد شیء ای تبدیل میشود که ماشین بتواند آن را درک کرد- 0 دیدگاه
- 5,535 مشاهده
-
پشت پردهٔ تحریمهای اپل و وضعیت کنونی اپلیکیشنهای ایرانی
توسط کامبیز اسدزاده
مدتی است در مورد مسدود شدن اپلیکیشنهای ایرانی برای iOS از طرف شرکت اپل خبرهایی به گوش میرسد که در سایتها و پایگاههای خبری از سمت نویسندگان و افراد غیرفنی تجزیه تحلیل و روشهای دور زدن آنها ارائه میشود. واقعیت بر دلیل نوشتن این مقاله این است که این فرصت و مشکلات کنونی آبی گلآلود برای سودجویانی شده است که کاربران از آن بیخبرند! هر روز یک توسعهدهنده یک سایت جدید راهاندازی میکند و با ادعای ارائه بستری نامحدود اقدام به تبلیغات میکند. بنده نیز به عنوان توسعهدهنده وظیفهٔ خودم میدانم که- 0 دیدگاه
- 3,591 مشاهده
-
چشمانداز فنی برای کیوت ۶
توسط کامبیز اسدزاده
این چشمانداز احتمالاً برای دوستداران کتابخانهٔ قدرتمند Qt و طرفدارانش جذاب باشد! بنابراین من سعی کردهام تا نتایج پست رسمی کیوت را در رابطه با چشمانداز فنی برای آیندهٔ کیوت نسخهٔ ۶ است در اختیار شما قرار دهم. تقریباً ۷ سال پیش کیوت نسخهٔ ۵.۰ منتشر شد! از آن زمان بسیاری از چیزها در دنیای اطراف ما تغییر پیدا کرده است. و اکنون وقت آن رسیده است که چشمانداز جدیدی را از نسخهٔ جدیدتر تعریف کنیم. بنابراین در این پست ما به معرفی مهمترین مواردی که به کیوت ۶ مرتبط است را میپردازیم. به نق- 6 دیدگاه
- 4,768 مشاهده
-
آیندهٔ توسعهٔ وب تحت فناوری WebAssembly
توسط کامبیز اسدزاده
با توجه به محبوبیت صنعت وِب، سالهاست زبانهای برنامهنویسی در این زمینه پیشرفتها و کاربردهای چشمگیری را داشتهاند، از جمله جاوااسکریپت (JS) به عنوان یک زبان قابل اجرا در داخل مرورگر شناخته میشود. هرچند بسیار محبوب و کاربردی است، اما این زبان قطعاً مشکلات خودش را دارد که برخی از آنها عدم انعطافپذیر بودن، سرعت پایین اجرا و همچنین انواع غیر ایمن آن است که این باعث میشود برای محاسبات و کارهای پیچیده جوابگو نباشد. هرچند گزینههایی مانند CoffeeScript و TypeScript وجود دارند و نسبتا- 2 دیدگاه
- 4,189 مشاهده
-
از تلفن همراه تا سکوی گیت هاب!
توسط Max Base
سلام. عدم دسترسی به یک سیستم مناسب و با خبر نبودن از حساب کاربری گیت هاب خود یکی از مشکلاتی بود که در این چند ساله برنامه نویسان با آن روبرو بودند. چک کردن حساب ایمیل در تلفن همراه می توانست تا حدودی به این موضوع کمک کند. اما یک اپلیکیشن اختصاصی برای این مورد می تواند این امر را به بهترین شکل پوشش دهد. بعد از کارهایی که برروی اپلیکیشن رسمی شرکت گیت هاب برای پلتفرم iOS انجام شد و خوشبختانه بدون هیچ مشکلی در بزرگ رویداد و کنفرانس شرکت و مایکروسافت - GitHub Universe 2019 در تاریخ Nov- 1 دیدگاه
- 2,246 مشاهده
وبلاگهای سایت ما
-

ارائه مکانیزمهای کلیدی سی++ امروزی که برای حفظ سازگاری در طول دههها طراحی شدهاند
نویسنده: بیارنه استراستروپ
منتشرشده در: ۴ فوریه ۲۰۲۵خلاصه:
بیش از ۴۵ سال از زمان پیدایش سی++ میگذرد. همانطور که برنامهریزی شده بود، این زبان برای پاسخگویی به چالشها تکامل یافته است، اما بسیاری از توسعهدهندگان همچنان از سی++ بهگونهای استفاده میکنند که گویی هنوز در هزاره گذشته هستیم. این رویکرد از نظر سهولت بیان ایدهها، عملکرد، قابلیت اطمینان و قابلیت نگهداری بهینه نیست. در این مقاله، مفاهیم کلیدی برای ساخت نرمافزارهای سی++ با عملکرد بالا، ایمن از نظر نوع داده، و انعطافپذیر ارائه میشود: مدیریت منابع، مدیریت طول عمر، مدیریت خطاها، مدولاریتی، و برنامهنویسی جنریک. در پایان، روشهایی برای اطمینان از بهروز بودن کد ارائه میشود تا از تکنیکهای قدیمی، ناامن و دشوار برای نگهداری اجتناب گردد: راهنماها و پروفایلها.
۱. مقدمه
سی++ زبانی با تاریخچهای طولانی است. این موضوع باعث شده که بسیاری از توسعهدهندگان، مدرسان و دانشگاهیان پیشرفتهای چندین دههای آن را نادیده بگیرند و سی++ را طوری توصیف کنند که گویی هنوز در هزاره دوم هستیم؛ زمانی که تلفنها باید به دیوار متصل میشدند و بیشتر کدها کوتاه، سطح پایین و کند بودند.
اگر سیستمعامل شما سازگاری را در طول دههها حفظ کرده باشد، میتوانید برنامههای سی++ نوشتهشده در سال ۱۹۸۵ را امروز روی یک رایانه مدرن اجرا کنید. پایداری – یعنی سازگاری با نسخههای قدیمیتر سی++ – بهویژه برای سازمانهایی که سیستمهای نرمافزاری را برای دههها نگهداری میکنند، بسیار مهم است. با این حال، در تقریباً تمام موارد، سی++ امروزی (C++30) میتواند ایدههای موجود در کدهای قدیمی را بسیار سادهتر بیان کند، با تضمینهای ایمنی نوع داده بهتر، و آنها را سریعتر و با مصرف حافظه کمتر اجرا کند.
این مقاله مکانیزمهای کلیدی سی++ امروزی را که برای این منظور طراحی شدهاند، ارائه میدهد. در بخش ششم، تکنیکهایی برای اطمینان از استفاده مدرن از سی++ شرح داده میشود.
مثال ساده:
برنامهای را در نظر بگیرید که هر خط یکتا را از ورودی به خروجی مینویسد:import std;// دسترسی به تمام کتابخانه استاندارد using namespace std; int main() // چاپ خطوط یکتا از ورودی { unordered_map<string,int> m; // جدول هش for (string line; getline(cin,line); ) if (m[line]++ == 0) cout << line << '\n'; }علاقهمندان ممکن است این را بهعنوان برنامه AWK با ساختار (!a[$0]++) بشناسند. این برنامه از unordered_map، نسخه کتابخانه استاندارد سی++ از جدول هش، استفاده میکند تا خطوط یکتا را نگه دارد و فقط زمانی که خطی برای اولین بار دیده میشود، آن را چاپ کند.
حلقه for برای محدود کردن محدوده متغیر حلقه (line) به خود حلقه استفاده شده است.
در مقایسه با سبکهای قدیمیتر سی++، نکته قابلتوجه غیبت موارد زیر است:
- تخصیص/آزادسازی صریح حافظه
- اندازهها
- مدیریت خطا
- تبدیلهای نوع (کستها)
- اشارهگرها
- اندیسگذاری ناامن
- استفاده از پیشپردازنده (بهویژه بدون #include).
با این حال، این برنامه در مقایسه با سبکهای قدیمیتر کاملاً کارآمد است و حتی از آنچه اکثر برنامهنویسان در زمان معقول میتوانند بنویسند، کارآمدتر است. اگر به عملکرد بیشتری نیاز باشد، میتوان آن را بهینه کرد. یکی از جنبههای مهم سی++ این است که کد با رابط کاربری مناسب میتواند برای نیازهای خاص بهینهسازی شود و حتی از سختافزارهای تخصصی استفاده کند، بدون اینکه به سایر کدها آسیبی برسد یا نیازی به تغییر کامپایلرها باشد.
مثال دیگر:
نسخهای از برنامه که خطوط یکتا را برای استفاده بعدی جمعآوری میکند:import std; using namespace std; // دسترسی به تمام کتابخانه استاندارد vector<string> collect_lines(istream& is) // جمعآوری خطوط یکتا از ورودی { unordered_set s; // جدول هش for (string line; getline(is,line); ) s.insert(line); return vector{from_range, s}; // کپی عناصر مجموعه به یک بردار } auto lines = collect_lines(cin);چون نیازی به شمارش نبود، از set بهجای map استفاده شده است. بهجای set، یک vector برگردانده شده چون vector پرکاربردترین ظرف (container) است. نیازی به مشخص کردن نوع عناصر vector نبود، زیرا کامپایلر آن را از نوع عناصر set استنباط کرد.
پارامتر from_range به کامپایلر و خواننده انسانی نشان میدهد که از یک محدوده (range) استفاده شده است، نه روشهای دیگر برای مقداردهی اولیه vector. نویسنده ترجیح میداد از vector{m} استفاده کند که منطقاً سادهتر است، اما کمیته استاندارد تصمیم گرفت که استفاده از from_range برای بسیاری از کاربران مفیدتر است.
برنامهنویسان با تجربه متوجه خواهند شد که این نسخه از collect_lines() کاراکترهای خواندهشده را کپی میکند. این میتواند مشکل عملکردی ایجاد کند، بنابراین در بخش ۳.۲ نشان داده میشود که چگونه میتوان collect_lines() را بهینه کرد تا از این کپیها جلوگیری شود.
هدف این مثالهای کوچک چیست؟
نمایش سی++ امروزی پیش از ورود به جزئیات فنی و امیدوارانه، خارج کردن برخی افراد از پیشفرضهای قدیمی و نادرست چند دههای.
۲. آرمانهای سی++
هدفهای من برای سی++ را میتوان بهصورت زیر خلاصه کرد:
- بیان مستقیم ایدهها
- ایمنی نوع داده در زمان کامپایل
- ایمنی منابع (یعنی بدون نشت منابع)
- دسترسی مستقیم به سختافزار
- عملکرد (یعنی کارایی بالا)
- گسترشپذیری مقرونبهصرفه (یعنی انتزاع با هزینه صفر)
- قابلیت نگهداری (یعنی کد قابلفهم)
- استقلال از پلتفرم (یعنی قابلیت حمل)
- پایداری (یعنی سازگاری با نسخههای قبلی)
این اهداف از روزهای اولیه سی++ تغییر نکردهاند، اما سی++ برای تکامل طراحی شده بود، و سی++ امروزی میتواند این ویژگیها را در کد بسیار بهتر از نسخههای قبلی ارائه دهد.
کد سی++ که این آرمانها را در بر میگیرد، صرفاً با استفاده از تمام ویژگیهای جدید بهدست نمیآید. برخی ویژگیها و تکنیکهای کلیدی قدیمی هستند:
- کلاسها با سازندهها و تخریبکنندهها
- استثناها
- قالبها (Templates)
- std::vector
- ...
ویژگیهای کلیدی جدیدتر عبارتند از:
- ماژولها (بخش ۴)
- مفاهیم (Concepts) برای مشخص کردن رابطهای جنریک (بخش ۵.۱)
- عبارات لامبدا برای تولید اشیاء تابعی (بخش ۵.۱)
- محدودهها (Ranges) (بخش ۵.۱)
- constexpr و consteval برای محاسبات در زمان کامپایل (بخش ۵.۲)
- پشتیبانی از همزمانی و الگوریتمهای موازی
- کوروتینها (که سالها غایب بودند، با وجود اینکه در نسخههای اولیه سی++ ضروری تلقی میشدند)
- std::shared_ptr
- ...
آنچه اهمیت دارد، استفاده از ویژگیهای زبان و کتابخانه بهصورت یک کل منسجم و متناسب با مسئلهای است که باید حل شود.
ارزش یک زبان برنامهنویسی در گستردگی و کیفیت کاربردهای آن است. برای سی++، شواهد در گستردگی شگفتانگیز حوزههای کاربردی آن است: نرمافزارهای پایه، گرافیک، کاربردهای علمی، فیلمها، بازیها، خودروها، پیادهسازی زبانها (نه فقط سی++)، کنترل پرواز، موتورهای جستجو، مرورگرها، طراحی و تولید نیمهرساناها، کاوشگرهای فضایی، امور مالی، هوش مصنوعی و بسیار دیگر. با توجه به میلیاردها خط کد سی++، نمیتوان زبان را بهصورت ناسازگار تغییر داد. اما میتوان روش استفاده از سی++ را تغییر داد.
در ادامه این مقاله، بر موارد زیر تمرکز میکنم:
- مدیریت منابع (شامل کنترل طول عمر و مدیریت خطاها)
- ماژولها (شامل حذف پیشپردازنده)
- برنامهنویسی جنریک (شامل مفاهیم)
- راهنماها و اجرا (چگونه میتوانیم تضمین کنیم که کد ما واقعاً «سی++ قرن بیست و یکم» است؟)
البته این تمام چیزی که سی++ ارائه میدهد نیست، و کدهای خوب زیادی به روشهایی نوشته میشوند که در اینجا ذکر نشدهاند. برای مثال، برنامهنویسی شیءگرا را کنار گذاشتم چون بسیاری از توسعهدهندگان میدانند چگونه آن را بهخوبی در سی++ انجام دهند. همچنین، کدهای با عملکرد بسیار بالا و کدهایی که مستقیماً سختافزار را دستکاری میکنند، نیاز به توجه و تکنیکهای خاصی دارند. پشتیبانی گسترده سی++ از همزمانی حداقل به مقالهای جداگانه نیاز دارد. با این حال، کلید اکثر نرمافزارهای خوب، رابطهای ایمن از نظر نوع داده است که اطلاعات کافی برای بهینهسازی و بررسی ویژگیها در زمان اجرا را فراهم میکنند، ویژگیهایی که نمیتوان در زمان کامپایل تضمین کرد.
۳. مدیریت منابع
منبع، هر چیزی است که باید آن را بهدست آوریم و بعداً بهصورت صریح یا ضمنی آزاد کنیم. برای مثال: حافظه، قفلها، دستههای فایل، سوکتها، دستههای نخها، تراکنشها و شیدرها. برای جلوگیری از نشت منابع، باید از آزادسازی دستی/صریح اجتناب کنیم. انسانها – حتی برنامهنویسان – بهطور بدنامی در بهیاد آوردن بازگرداندن آنچه قرض گرفتهاند، ضعیف هستند.
تکنیک پایه سی++ برای مدیریت منابع، ریشهدادن آن در یک دسته (handle) است که تضمین میکند منبع هنگام خروج از محدوده دسته آزاد میشود. برای اطمینان، نمیتوانیم به عملیات صریح مانند delete، free()، unlock() و غیره در کد برنامه وابسته باشیم. چنین عملیاتی باید در دستههای منابع قرار گیرند. به مثال زیر توجه کنید:
template<typename T> class Vector { // بردار از عناصر نوع T public: Vector(initializer_list<T>); // سازنده: تخصیص حافظه؛ مقداردهی اولیه عناصر ~Vector(); // تخریبکننده: نابودی عناصر؛ آزادسازی حافظه // ... private: T* elem; // اشارهگر به عناصر int sz; // تعداد عناصر };در اینجا، Vector یک دسته منبع است. سطح انتزاع را از اشارهگر نزدیک به ماشین بهعلاوه تعداد عناصر، به یک نوع مناسب با مقداردهی اولیه تضمینشده (سازنده) و پاکسازی (تخریبکننده) ارتقا میدهد. بردار استاندارد کتابخانه که این Vector برای نشان دادن آن در نظر گرفته شده، همچنین مقایسهها، تخصیصها، روشهای بیشتر برای مقداردهی اولیه، تغییر اندازه، پشتیبانی از تکرار و غیره را فراهم میکند. این به برنامهنویس یک بردار میدهد که از نظر فنی زبانی، مانند یک نوع داخلی مانند عدد صحیح رفتار میکند، با وجود اینکه یک دسته منبع (کتابخانه استاندارد) است و معناشناسی کاملاً متفاوتی دارد. میتوانیم از آن به این صورت استفاده کنیم:
void fct() { Vector<double> constants {1, 1.618, 3.14, 2.99e8}; Vector<string> designers {"Strachey", "Richards", "Ritchie"}; // ... Vector<pair<string,jthread>> vp { {"producer",prod}, {"consumer",cons}}; }در اینجا، constants با چهار مقدار ریاضی و فیزیکی، designers با سه طراح زبان برنامهنویسی شناختهشده، و vp با یک جفت تولیدکننده-مصرفکننده مقداردهی اولیه میشوند. همه توسط سازندههای مناسب مقداردهی شده و هنگام خروج از محدوده توسط تخریبکنندههای مناسب آزاد میشوند. مقداردهی اولیه و آزادسازی توسط جفتهای سازنده-تخریبکننده بهصورت بازگشتی انجام میشود. برای مثال، ساخت و تخریب vp ساده نیست زیرا شامل یک Vector، یک pair، رشتهها (دستههای کاراکترها)، و jthreadها (دستههای نخهای سیستمعامل) است. با این حال، همه اینها بهصورت ضمنی مدیریت میشوند.
این استفاده از جفتهای سازنده-تخریبکننده (که اغلب بهعنوان RAII – «تخصیص منبع یعنی مقداردهی اولیه» شناخته میشود) نهتنها آزادسازی منابع را تضمین میکند، بلکه نگهداری منابع را نیز به حداقل میرساند، که در مقایسه با بسیاری از تکنیکهای دیگر، مانند مدیریت حافظه مبتنی بر جمعآوری زباله، مزیت عملکردی قابلتوجهی ارائه میدهد.
۳.۱. کنترل طول عمر
کنترل طول عمر اشیاء نمایانگر منابع برای مدیریت ساده و کارآمد منابع ضروری است. سی++ چهار نقطه کنترل را بهصورت عملیات روی یک کلاس (اینجا به نام X) ارائه میدهد:
- ساخت: پیش از اولین استفاده فراخوانی میشود: ایجاد ثابت کلاس (در صورت وجود). نام: سازنده، X(optional_arguments)
- تخریب: پس از آخرین استفاده فراخوانی میشود: آزادسازی هر منبع (در صورت وجود). نام: تخریبکننده، ~X()
- کپی: ساخت یک شیء جدید با همان مقدار شیء دیگر؛ a=b به این معناست که a==b (برای انواع منظم). نامها: سازنده کپی، X(const X&) و تخصیص کپی، X::operator=(const X&)
- انتقال: انتقال منابع از یک شیء به شیء دیگر، اغلب بین محدودهها. نامها: سازنده انتقال، X(X&&) و تخصیص انتقال، X::operator=(X&&)
برای مثال، میتوانیم Vector خود را به این صورت گسترش دهیم:
template<typename T> class Vector { // بردار از عناصر نوع T public: Vector(); // سازنده پیشفرض: ساخت یک بردار خالی Vector(initializer_list<T>); // سازنده: تخصیص حافظه؛ مقداردهی اولیه عناصر Vector(const Vector& a); // سازنده کپی: کپی a به *this Vector& operator=(const Vector& a); // تخصیص کپی: کپی a به *this Vector(Vector&& a); // سازنده انتقال: انتقال a به *this Vector& operator=(Vector&& a); // تخصیص انتقال: انتقال a به *this ~Vector(); // تخریبکننده: نابودی عناصر؛ آزادسازی حافظه // ... };عملگرهای تخصیص باید هر منبعی که شیء مقصد مالک آن است را آزاد کنند. عملیات انتقال باید تمام منابع را به مقصد منتقل کنند و اطمینان دهند که دیگر در منبع وجود ندارند.
۳.۲. حذف کپیهای اضافی
با توجه به این چارچوب، بیایید دوباره به مثال collect_lines از بخش ۱ نگاه کنیم. ابتدا میتوانیم آن را کمی سادهتر کنیم:
vector<string> collect_lines(istream& is) // جمعآوری خطوط یکتا از ورودی { unordered_set s {from_range,istream_iterator<string>{is}}; // مقداردهی اولیه s از is return vector{from_range,s}; } auto lines = collect_lines(cin);بخش istream_iterator<string>{is} به ما اجازه میدهد ورودی از is را بهعنوان یک محدوده از عناصر در نظر بگیریم، بهجای اینکه عملیات ورودی را بهصورت صریح روی جریان اعمال کنیم.
در اینجا، بردار بهجای کپی، از collect_lines() منتقل میشود. بدترین حالت هزینه سازنده انتقال یک بردار، کپی ۶ کلمه است: سه کلمه برای کپی نمایندگی و سه کلمه برای صفر کردن نمایندگی اصلی. این حتی اگر بردار یک میلیون عنصر داشته باشد، صدق میکند.
حتی این هزینه کوچک در بسیاری از موارد حذف میشود. از حدود سال ۱۹۸۳، کامپایلرها میدانند که مقدار برگشتی (اینجا، vector{from_range,s}) را در مقصد (اینجا، lines) بسازند. این بهعنوان «حذف کپی» شناخته میشود.
با این حال، رشتهها همچنان از مجموعه به بردار کپی میشوند. این میتواند پرهزینه باشد. در اصل، کامپایلر میتوانست استنباط کند که ما پس از ساخت بردار دیگر از s استفاده نمیکنیم و فقط عناصر رشته را منتقل کند، اما کامپایلرهای امروزی به این اندازه هوشمند نیستند، بنابراین باید صراحتاً درخواست انتقال کنیم:
vector<string> collect_lines(istream& is) // جمعآوری خطوط یکتا از ورودی { unordered_set s {from_range,istream_iterator<string>{is}}; // مقداردهی اولیه s از is return vector{from_range,std::move(s)}; // انتقال عناصر }این هنوز یک کپی اضافی باقی میگذارد: کپی کاراکترها از بافر ورودی به عناصر رشته مجموعه. اگر این مشکلساز باشد، میتوان آن را نیز حذف کرد. با این حال، انجام این کار شامل تکنیکهای سطح پایین معمولی است که خارج از محدوده این مقاله است. چنین کدی پیچیدهتر است، اما همانطور که همیشه، کد سی++ با رابطهای مشخصشده بهخوبی قابلبهینهسازی است. همچنین، لطفاً بهیاد داشته باشید: بدون اندازهگیری نیاز به بهینهسازی، هرگز بهینهسازی نکنید.
۳.۳. منابع و خطاها
یکی از اهداف کلیدی سی++ ایمنی منابع است: هیچ منبعی نباید نشت کند. این به این معناست که باید از نشت منابع در شرایط خطا جلوگیری کنیم. قوانین پایه عبارتند از:
- هیچ منبعی نباید نشت کند.
- هیچ منبعی نباید در حالت نامعتبر رها شود.
بنابراین، وقتی خطایی که نمیتوان بهصورت محلی مدیریت کرد شناسایی میشود، پیش از خروج از تابع باید:
- هر شیء دسترسیشده را در حالت معتبر قرار دهیم.
- هر شیء که تابع مسئول آن است را آزاد کنیم.
- مدیریت مشکلات مربوط به منابع را به تابع بالاتر در زنجیره فراخوانی واگذار کنیم.
این به این معناست که «اشارهگرهای خام» نمیتوانند بهطور قابلاعتماد بهعنوان دستههای منابع استفاده شوند. به نوع Gadget توجه کنید که ممکن است منابعی مانند حافظه، قفلها و دستههای فایل را نگه دارد:
void f(int n, int x) { Gadget g {n}; Gadget* pg = new Gadget{n}; // استفاده صریح از new: نکنید! // ... if (x<100) throw std::runtime_error{"Weird!"}; // نشت *pg؛ اما نه g if (x<200) return; // نشت *pg؛ اما نه g // ... }استفاده صریح از new برای قرار دادن Gadget روی هیپ، مشکلی ایجاد میکند همان لحظهای که نتیجه آن در یک «اشارهگر خام» بهجای یک دسته منبع با تخریبکننده مناسب ذخیره میشود. اشیاء محلی سادهتر و معمولاً سریعتر از استفاده صریح از new هستند.
برای یک سیستم قابلاعتماد، نیاز به یک سیاست مشخص برای مدیریت خطاها داریم. بهترین روش کلی، تمایز بین خطاهایی است که میتوانند بهصورت محلی توسط فراخواننده فوری مدیریت شوند و خطاهایی که فقط در بالاترین سطح زنجیره فراخوانی قابلمدیریت هستند:
- از کدهای خطا و آزمایشها برای خطاهایی که رایج هستند و میتوانند بهصورت محلی مدیریت شوند استفاده کنید.
- از استثناها برای خطاهای نادر («استثنایی») که نمیتوانند بهصورت محلی مدیریت شوند استفاده کنید.
جایگزین، «جهان کد خطا» پرهزینه است که در آن هر فراخواننده در زنجیره فراخوانی باید بهیاد بیاورد که آزمایش کند.
عدم بررسی یک استثنا منجر به خاتمه میشود، نه نتایج اشتباه.
در برخی کاربردهای مهم، خاتمه فوری بیقیدوشرط گزینهای نیست. در این صورت، باید هر کد خطای بازگشتی را آزمایش کنیم و هر استثنا را در جایی (مثلاً در main()) بگیریم و پاسخ مناسب را انجام دهیم.بهطور شگفتانگیزی برای بسیاری، استثناها حتی برای سیستمهای کوچک میتوانند ارزانتر و سریعتر از استفاده مداوم از کدهای خطا باشند.
مدیریت خطا مبتنی بر استثناها با اشارهگرهایی که بهعنوان دستههای منابع استفاده میشوند، کار نمیکند. برای مدیریت خطای ساده، قابلاعتماد و قابلنگهداری، باید به استثناها و RAII و همچنین کدهای خطا برای خطاهایی که باید بهصورت محلی مدیریت شوند، تکیه کنیم. به مثال زیر توجه کنید:
void fct(jthread& prod, jthread& cons, string name) { ifstream in { name }; if (!in) { /* ... */ } // احتمال شکست مورد انتظار // ... vector<double> constants {1, 1.618, 3.14, 2.99e8}; vector<string> designers {"Strachey", "Richards", "Ritchie"}; auto dmr = "Dennis M. " + designers[2]; // ... pair<string,jthread&> pipeline[] { {"producer", prod}, {"consumer", cons}}; // ... }اگر نتوانیم به استثناها تکیه کنیم، برای این مثال کوچک (اما غیرواقعی نیست) به چند آزمایش نیاز داریم؟ این مثال شامل تخصیص حافظه، ساخت تودرتو، یک عملگر بیشبارگذاریشده، و بهدست آوردن یک منبع سیستمی است.
متأسفانه، استثناها بهطور جهانی مورد قدردانی و استفاده قرار نگرفتهاند. علاوه بر استفاده بیشازحد از «اشارهگرهای خام»، مشکلی بوده که بسیاری از توسعهدهندگان اصرار دارند از یک تکنیک واحد برای گزارش تمام خطاها استفاده کنند، یعنی یا همه با پرتاب یا همه با بازگرداندن کد خطا. این با نیازهای کدهای واقعی همخوانی ندارد.
۴. مدولاریتی
پیشپردازندهای که سی++ از سی به ارث برده، تقریباً بهطور جهانی استفاده میشود، اما مانع بزرگی برای توسعه ابزارها و عملکرد کامپایلر است. در سی++ امروزی، ماکروهایی که برای بیان ثابتها، توابع و انواع استفاده میشدند، با ثابتهای با نوع و محدوده مناسب، توابع ارزیابیشده در زمان کامپایل، و قالبها جایگزین شدهاند. با این حال، پیشپردازنده برای بیان شکل ضعیفی از مدولاریتی ضروری بوده است. رابطهای کتابخانهها و سایر کدهای کامپایلشده جداگانه بهصورت فایلهایی حاوی متن منبع سی++ و #include نمایش داده میشوند.
۴.۱. فایلهای سرآیند (Header Files)
یک دستور #include متن منبع را از یک «فایل سرآیند» به واحد ترجمه فعلی کپی میکند. متأسفانه، این به این معناست که:
#include "a.h" #include "b.h"ممکن است معنای متفاوتی نسبت به:
#include "b.h" #include "a.h"داشته باشد. این منبع باگهای ظریفی است.
یک #include انتقالی است. یعنی اگر a.h شامل #include "c.h" باشد، متن c.h نیز بخشی از هر فایل منبعی که از #include "a.h" استفاده میکند، میشود. این نیز منبع باگهای ظریفی است. از آنجا که یک فایل سرآیند اغلب در دهها یا صدها فایل منبع #include میشود، این به معنای تکرار زیاد در کامپایل است.
۴.۲. ماژولها
این مشکلات استفاده از فایلهای سرآیند برای تقلید مدولاریتی از پیش از تولد سی++ شناختهشده بود، اما تعریف یک جایگزین و معرفی آن به میلیاردها خط کد کار سادهای نیست. با این حال، سی++ اکنون ماژولهایی ارائه میدهد که مدولاریتی واقعی را فراهم میکنند. وارد کردن ماژولها مستقل از ترتیب است، بنابراین:
import a; import b;همان معنای:
import b; import a;را دارد. استقلال متقابل ماژولها به معنای بهبود بهداشت کد است و باگهای وابستگی ظریف را غیرممکن میکند.
اینجا یک مثال بسیار ساده از تعریف یک ماژول است:
چون وارد کردن ماژول انتقالی نیست، کاربران map_printer به جزئیات پیادهسازی موردنیاز برای print_map دسترسی ندارند.
یک ماژول فقط یکبار نیاز به کامپایل دارد، صرفنظر از اینکه چند بار وارد میشود. این به معنای بهبود بسیار قابلتوجه در زمان کامپایل است. یک کاربر گزارش داده است:
#include <libgalil/DmcDevice.h> // 457440 خط پس از پیشپردازش int main() { // 151268 خط غیرخالی Libgalil::DmcDevice("192.168.55.10"); // 1546 میلیثانیه برای کامپایل }این یعنی ۱.۵ ثانیه برای کامپایل تقریباً نیم میلیون خط کد. این سریع است! اما کامپایلر کار بیشازحد انجام میدهد.
import libgalil; // 5 خط پس از پیشپردازش int main() { // 4 خط غیرخالی Libgalil::DmcDevice("192.168.55.10"); // 62 میلیثانیه برای کامپایل }این یک سرعت ۲۵ برابری است. نمیتوان انتظار داشت که در همه موارد اینگونه باشد، اما برتری ۷ تا ۱۰ برابری وارد کردن نسبت به #include رایج است. اگر آن کتابخانه را در ۲۵ فایل منبع #include کنید، هزینه آن ۱.۵ ثانیه ۲۵ بار خواهد بود، در حالی که وارد کردن در مجموع ۱.۵ ثانیه طول میکشد.
کتابخانه استاندارد کامل به یک ماژول تبدیل شده است. به برنامه سنتی «سلام، دنیا!» نگاه کنید:
#include <iostream> int main() { std::cout << "Hello, World!\n"; }روی لپتاپ من، این در ۰.۸۷ ثانیه کامپایل شد. جایگزین کردن #include<iostream.h> با import std; زمان کامپایل را به ۰.۰۸ ثانیه کاهش داد، با وجود اینکه حداقل ۱۰ برابر اطلاعات بیشتری در دسترس قرار گرفت.
بازسازی مقدار قابلتوجهی از کد آسان یا ارزان نیست، اما در مورد ماژولها، مزایا از نظر کیفیت کد قابلتوجه و از نظر زمان کامپایل عظیم است.
چرا در این مورد خاص – و فقط در این مورد – زحمت توضیح «روش قدیمی بد» را به خودم میدهم؟ چون #includeها همهگیر هستند، تقریباً از زمان تولد سی، و بسیاری از توسعهدهندگان تصور سی++ بدون آن را دشوار میدانند.
۵. برنامهنویسی جنریک
برنامهنویسی جنریک یکی از پایههای کلیدی سی++ امروزی است. این از پیش از تغییر نام «سی با کلاسها» به «سی++» وجود داشته، اما تنها بهتازگی (C++20) پشتیبانی زبان به آرمانها نزدیک شده است.
برنامهنویسی جنریک، یعنی برنامهنویسی با انواع و توابعی که توسط انواع پارامتریزه شدهاند، ارائه میدهد:
- کد کوتاهتر و خواناتر
- بیان مستقیمتر ایدهها
- انتزاع با هزینه صفر
- ایمنی نوع داده
قالبها، پشتیبانی زبان سی++ برای برنامهنویسی جنریک، در کتابخانه استاندارد همهگیر هستند:
- ظروف و الگوریتمها
- پشتیبانی از همزمانی: نخها، قفلها، ...
- مدیریت حافظه: تخصیصدهندهها، دستههای منابع (مثل vector و list)، اشارهگرهای مدیریت منابع، ...
- ورودی/خروجی
- رشتهها و عبارات منظم
- و خیلی چیزهای دیگر
میتوانیم کدی بنویسیم که برای تمام انواع آرگومان مناسب کار کند. برای مثال، اینجا یک تابع مرتبسازی است که تمام انواعی که تعریف استاندارد ISO سی++ از یک محدوده قابلمرتبسازی را دارند، میپذیرد:
void sort(Sortable_range auto& r); vector<string> vs; // ... پر کردن vs ... sort(vs); array<int,128> ai; // ... پر کردن ai ... sort(ai);کامپایلر اطلاعات کافی برای تأیید این دارد که انواع vs و ai آنچه Sortable_range نیاز دارد را دارند؛ یعنی یک محدوده با دسترسی تصادفی از مقادیر انواعی که میتوانند برای مرتبسازی مقایسه و جابهجا شوند. اگر آرگومانها مناسب نباشند، خطا توسط کامپایلر در نقطه استفاده شناسایی میشود. برای مثال:
list<int> lsti; // ... پر کردن lsti ... sort(lsti); // خطا: یک لیست دسترسی تصادفی ارائه نمیدهدطبق استاندارد سی++، یک لیست محدوده قابلمرتبسازی نیست زیرا دسترسی تصادفی ارائه نمیدهد.
۵.۱. مفاهیم (Concepts)
یک مفهوم (concept) یک پیشنیاز در زمان کامپایل است. یعنی تابعی که توسط کامپایلر اجرا میشود و یک مقدار بولی تولید میکند. بیشتر برای بیان الزامات پارامترهای یک قالب استفاده میشود. یک مفهوم اغلب از مفاهیم دیگر ساخته میشود. برای مثال، اینجا Sortable_range موردنیاز تابع sort بالا آمده است:
template<typename R> concept Sortable_range = random_access_range<R> // دارای begin()/end()، ++، []، +، ... && sortable<iterator_t<R>>; // میتواند عناصر را مقایسه و جابهجا کنداین میگوید که یک نوع R یک Sortable_range است اگر یک random_access_range باشد و دارای نوع تکرارساز قابلمرتبسازی باشد. random_access_range و sortable مفاهیمی هستند که در کتابخانه استاندارد تعریف شدهاند. یک مفهوم میتواند یک یا چند آرگومان بگیرد و میتواند از ویژگیهای اساسی زبان ساخته شود. برای مشخص کردن یک ویژگی نوع مستقیماً به زبان (بهجای استفاده از مفاهیم دیگر)، از «الگوهای استفاده» استفاده میکنیم. برای مثال:template<typename T, typename U = T> concept equality_comparable = requires(T a, U b) { {a==b} -> Boolean; {a!=b} -> Boolean; {b==a} -> Boolean; {b!=a} -> Boolean; };سازههای داخل {...} باید معتبر باشند و چیزی را برگردانند که با مفهوم مشخصشده پس از -> مطابقت داشته باشد. بنابراین، اینجا الگوهای استفاده فهرستشده (مثل a==b) باید چیزی برگردانند که بتوان بهعنوان یک bool استفاده کرد. معمولاً، همانطور که در مثال sort دیده شد، بررسی اینکه یک نوع با یک مفهوم مطابقت دارد بهصورت ضمنی انجام میشود، اما میتوانیم صراحتاً با static_assert این کار را انجام دهیم:
static_assert(equality_comparable<int,double>); // موفق static_assert(equality_comparable<int>); // موفق (U بهطور پیشفرض int است) static_assert(equality_comparable<int,string>); // ناموفقمفهوم equality_comparable در کتابخانه استاندارد تعریف شده است. نیازی به تعریف آن توسط خودمان نیست، اما مثال خوبی است.
ما میخواهیم کدی بنویسیم که برای تمام انواع آرگومان مناسب کار کند. با این حال، بسیاری (شاید بیشتر) الگوریتمها بیش از یک نوع آرگومان قالب میگیرند. این به این معناست که باید روابط بین این آرگومانهای قالب را بیان کنیم. برای مثال:
template<input_range R, indirect_unary_predicate<iterator_t<R> Pred> Iterator_t<R> find_if(R&& r, Pred p);این میگوید که find_if یک محدوده ورودی r و یک پیشنیاز p میگیرد که میتواند روی نتیجه یک غیرمستقیمسازی از طریق تکرارساز r اعمال شود. برای مثال:vector<string> numbers; // رشتههایی که اعداد را نشان میدهند؛ مثلاً "13" و "123.45" // ... پر کردن numbers ... auto q = find_if(numbers, [](const string& s) { return stoi(s)<42; });پارامتر دوم فراخوانی find_if یک عبارت لامبدا است. این یک شیء تابعی تولید میکند که هنگام فراخوانی در پیادهسازی find_if برای یک آرگومان s، عبارت stoi(s)<42 را اجرا میکند. عبارات لامبدا (که معمولاً فقط «لامبدا» نامیده میشوند) در سی++ امروزی بسیار مفید و محبوب شدهاند.
ما همیشه مفاهیم را داشتهایم. هر کتابخانه جنریک موفق نوعی از مفاهیم را دارد: در ذهن طراح، در مستندات، یا در نظرات. چنین مفاهیمی اغلب مفاهیم اساسی یک حوزه کاربردی را نشان میدهند. برای مثال:
- انواع داخلی سی/سی++: حسابی و اعشاری
- کتابخانه استاندارد سی++: تکرارسازها، دنبالهها، و ظروف
- ریاضیات: موناد، گروه، حلقه، و میدان
- گرافها: یالها و رأسها، گراف، DAG، ...
استاندارد C++20 ایده مفاهیم را معرفی نکرد؛ فقط زبان مستقیمی برای مفاهیم اضافه کرد. یک مفهوم یک پیشنیاز در زمان کامپایل است. استفاده از مفاهیم آسانتر از عدم استفاده از آنهاست. با این حال، مانند هر سازه جدید، باید یاد بگیریم که چگونه از آنها بهطور مؤثر استفاده کنیم.
۵.۲. ارزیابی در زمان کامپایل
یک مفهوم نمونهای از یک تابع در زمان کامپایل است. در سی++ امروزی، هر تابع بهاندازه کافی ساده میتواند در زمان کامپایل ارزیابی شود:
- constexpr: میتواند در زمان کامپایل ارزیابی شود
- consteval: باید در زمان کامپایل ارزیابی شود
- concept: در زمان کامپایل ارزیابی میشود، میتواند انواع را بهعنوان آرگومان بگیرد
این برای انواع داخلی و تعریفشده توسط کاربر صدق میکند. برای مثال:
constexpr auto jul = weekday(December/24/2024); // سهشنبهبرای اینکه توابع consteval و constexpr و مفاهیم بتوانند در زمان کامپایل ارزیابی شوند، نمیتوانند:
- اثرات جانبی داشته باشند
- به دادههای غیرمحلی دسترسی داشته باشند
- رفتار نامعین (UB) داشته باشند
با این حال، آنها میتوانند از امکانات گسترده، از جمله بخش زیادی از کتابخانه استاندارد، استفاده کنند.
بنابراین، چنین توابعی نسخه سی++ از ایده یک تابع خالص هستند و یک کامپایلر سی++ امروزی شامل یک مفسر تقریباً کامل سی++ است. ارزیابی در زمان کامپایل همچنین برای عملکرد یک مزیت بزرگ است.
۶. راهنماها و اجرا
سبکهای امروزی مزایای عمدهای به همراه دارند. با این حال، ارتقای کد دشوار و اغلب پرهزینه است. چگونه میتوانیم کد موجود را مدرن کنیم؟ اجتناب از تکنیکهای غیربهینه دشوار است. عادتهای قدیمی بهسختی از بین میروند. آشنایی اغلب با سادگی اشتباه گرفته میشود. اطلاعات گیجکننده و قدیمی زیادی در وب و مواد آموزشی منتشر میشود. همچنین، کدهای قدیمی اغلب رابطهای به سبک قدیمی ارائه میدهند، که استفاده از سبکهای قدیمیتر را تشویق میکند. ما به کمک نیاز داریم تا به سمت سبکهای بهتری از کد هدایت شویم.
پایداری/سازگاری یک ویژگی اصلی است. همچنین، با توجه به میلیاردها خط کد سی++، تنها پذیرش تدریجی ویژگیها و تکنیکهای جدید امکانپذیر است. بنابراین، نمیتوانیم زبان را تغییر دهیم، اما میتوانیم روش استفاده از آن را تغییر دهیم. مردم (بهطور معقولی) سی++ سادهتری میخواهند، اما همچنین ویژگیهای جدید، و اصرار دارند که کد موجودشان باید به کار خود ادامه دهد.
برای کمک به توسعهدهندگان برای تمرکز بر استفاده مؤثر از سی++ امروزی و اجتناب از «گوشههای تاریک» قدیمی زبان، مجموعههایی از راهنماها توسعه یافتهاند. در اینجا من بر راهنماهای هسته سی++ تمرکز میکنم که به نظرم جاهطلبانهترین هستند.
یک مجموعه راهنما باید فلسفه منسجمی از زبان نسبت به یک کاربرد خاص را نشان دهد. هدف اصلی من استفاده ایمن از نظر نوع داده و منابع از سی++ استاندارد ISO است. یعنی:
- هر شیء فقط طبق تعریف خود استفاده میشود
- هیچ منبعی نشت نمیکند
این شامل آنچه مردم بهعنوان ایمنی حافظه میشناسند و خیلی بیشتر است. این هدف جدیدی برای سی++ نیست. بدیهی است که نمیتوان آن را برای هر استفاده از سی++ بهدست آورد، اما اکنون سالها تجربه نشان داده که برای کد مدرن امکانپذیر است، هرچند تاکنون اجرا ناقص بوده است.
یک مجموعه راهنما نقاط قوت و ضعفی دارد:
- اکنون در دسترس است (مثلاً راهنماهای هسته سی++)
- قوانین فردی میتوانند اجرا شوند یا نشوند
- اجرا ناقص است
با تکیه بر راهنماها، به اجرا نیاز داریم:
- یک پروفایل مجموعهای منسجم از قوانین راهنما است که اجرا میشود
- در WG21 و جاهای دیگر در حال کار است
- هنوز در دسترس نیستند، جز نسخههای آزمایشی و جزئی
هنگام فکر کردن به سی++، مهم است بهیاد داشته باشیم که سی++ فقط یک زبان نیست، بلکه بخشی از یک اکوسیستم شامل پیادهسازیها، کتابخانهها، ابزارها، آموزش و غیره است. بهویژه، توسعهدهندگانی که از سی++ استفاده میکنند به امکاناتی فراتر از آنچه در سی در دسترس است وابستهاند.
۶.۱. راهنماها
زیرمجموعهسازی ساده سی++ کار نمیکند: ما به ویژگیهای سطح پایین، پیچیده، نزدیک به سختافزار، مستعد خطا و فقط برای متخصصان نیاز داریم تا امکانات سطح بالاتر را بهطور کارآمد پیادهسازی کنیم و ویژگیهای سطح پایین را در صورت نیاز فعال کنیم. راهنماهای هسته سی++ از استراتژیای به نام «زیرمجموعهای از ابر مجموعه» استفاده میکنند:
- ابتدا: زبان را با چند انتزاع کتابخانهای گسترش دهید: از بخشهایی از کتابخانه استاندارد استفاده کنید و یک کتابخانه کوچک (کتابخانه پشتیبانی راهنماها، GSL) اضافه کنید تا استفاده از راهنماها راحت و کارآمد باشد.
- سپس: زیرمجموعهسازی: استفاده از ویژگیهای سطح پایین، غیرکارآمد و مستعد خطا را ممنوع کنید.
آنچه بهدست میآید «سی++ تقویتشده» است: چیزی ساده، ایمن، انعطافپذیر و سریع؛ نه یک زیرمجموعه فقیر یا چیزی که به بررسیهای گسترده در زمان اجرا وابسته باشد. همچنین زبانی با ویژگیهای جدید و/یا ناسازگار ایجاد نمیکنیم. نتیجه ۱۰۰٪ سی++ استاندارد ISO است. ویژگیهای پیچیده، خطرناک و سطح پایین همچنان میتوانند در صورت نیاز فعال و استفاده شوند.
حوزههای کاربردی مختلف نیازهای متفاوتی دارند و بنابراین به مجموعههای راهنمای متفاوتی نیاز دارند، اما در ابتدا تمرکز روی «هسته یا راهنماهای هسته سی++» است. قوانینی که امیدواریم همه در نهایت از آنها بهرهمند شوند:
- بدون متغیرهای مقداردهینشده
- بدون نقض محدوده یا nullptr
- بدون نشت منابع
- بدون اشارهگرهای آویزان
- بدون نقض نوع
- بدون نامعتبرسازی
دو کتاب سی++ را با پیروی از این راهنماها شرح میدهند، مگر در مواردی که خطاها را نشان میدهند: «تور سی++» برای برنامهنویسان با تجربه و «برنامهنویسی: اصول و تمرین با استفاده از سی++» برای مبتدیان. دو کتاب دیگر جنبههای راهنماهای هسته سی++ را بررسی میکنند.
۶.۲. قانون نمونه: از اندیسگذاری اشارهگرها استفاده نکنید
یک اشارهگر اطلاعات مرتبط موردنیاز برای بررسی محدوده را ندارد. با این حال، بررسی محدوده برای ایمنی حافظه و همچنین ایمنی نوع داده ضروری است، زیرا نمیتوانیم به کد برنامه اجازه دهیم اشیائی را بخواند یا بازنویسی کند که فراتر از محدوده اشیاء اشارهشده هستند. در عوض، باید از انتزاعی استفاده کنیم که اطلاعات کافی برای بررسی محدوده داشته باشد، مانند یک آرایه، یک بردار، یا یک span.
سبک رایجی را در نظر بگیرید: یک اشارهگر بهعلاوه یک عدد صحیح که ظاهراً تعداد عناصر اشارهشده را نشان میدهد:
void f(int* p, int n) { for (int i = 0; i<n; i++) do_something_with(p[n]); } int a[100]; // ... f(a,100); // مشکلی ندارد؟ (بستگی به معنای n در تابع فراخوانیشده دارد) f(a,1000); // احتمالاً فاجعهاین یک مثال بسیار ساده با استفاده از یک آرایه برای نشان دادن اندازه است. از آنجا که اندازه موجود است، بررسی در نقطه فراخوانی ممکن است (هرچند بهندرت انجام میشود) و معمولاً یک جفت (اشارهگر، عدد صحیح) از طریق یک زنجیره فراخوانی طولانیتر منتقل میشود که تأیید را دشوار یا غیرممکن میکند.
راهحل این مشکل، اتصال محکم اندازه به اشارهگر است (مانند Vector؛ بخش ۳.۱). این همان کاری است که یک span انجام میدهد:
void f(span<int> a) // یک span شامل یک اشارهگر و تعداد عناصر اشارهشده است { for (int& x: s) // حالا میتوانیم از یک range-for استفاده کنیم do_something_with(x); } int a[100]; // ... f(a); // نوع و تعداد عناصر استنباط میشود f({a,1000}); // درخواست مشکل، اما بهصورت نحوی مشخصشده و بهراحتی قابلبررسیاستفاده از span نمونه خوبی از اصل «ساده کردن چیزهای ساده» است. کد با استفاده از آن سادهتر از «سبک قدیمی» است: کوتاهتر، ایمنتر، و اغلب سریعتر.
نوع span در کتابخانه پشتیبانی راهنماها بهعنوان یک نوع بررسیشده محدوده معرفی شد. متأسفانه، وقتی به کتابخانه استاندارد اضافه شد، تضمین بررسی محدوده حذف شد. بدیهی است که یک پروفایل (بخش ۶.۴) که این قانون را اجرا میکند، باید بررسی محدوده را انجام دهد. هر پیادهسازی عمده سی++ راههایی برای اطمینان از این دارد (مثلاً سختسازی کتابخانه استاندارد GCC، ایمنی فضایی گوگل، و تحلیلگر استاتیک ویژوال استودیو مایکروسافت). متأسفانه، هنوز راه استاندارد و قابلحمل برای درخواست آن وجود ندارد.
۶.۳. قانون نمونه: از اشارهگر نامعتبر استفاده نکنید
برخی ظروف، بهویژه بردار، میتوانند عناصر خود را جابهجا کنند. اگر کسی خارج از ظرف اشارهگری به یک عنصر بهدست آورد و پس از جابهجایی از آن استفاده کند، فاجعه ممکن است رخ دهد. به مثال زیر توجه کنید:
void f(vector<int>& vi) { vi.push_back(9); // ممکن است عناصر vi را جابهجا کند } void g() { vector<int> vi { 1,2 }; auto p = vi.begin(); // اشاره به اولین عنصر vi f(vi); *p = 7; // خطا: p نامعتبر است }با قوانین مناسب برای استفاده از سی++ (بخش ۶.۱)، تحلیل استاتیک محلی میتواند از نامعتبرسازی جلوگیری کند. در واقع، پیادهسازیهای بررسیهای طول عمر راهنماهای هسته از سال ۲۰۱۹ این کار را انجام دادهاند. پیشگیری از نامعتبرسازی و استفاده از اشارهگرهای آویزان بهطور کلی کاملاً استاتیک (در زمان کامپایل) است. هیچ بررسی در زمان اجرا درگیر نیست.
اینجا جای شرح مفصل چگونگی انجام این تحلیل نیست. با این حال، طرح کلی مدل این است:
- قوانین برای هر موجودی که مستقیماً به یک شیء اشاره میکند، مانند اشارهگرها، اشارهگرهای مدیریت منابع، ارجاعها، و ظروف اشارهگرها اعمال میشود. مثالها شامل int*، int&، vector<int*>، unique_ptr<int>، jthread که یک int* را نگه میدارد، و یک لامبدا که یک int را با ارجاع گرفته است.
- استفاده پس از delete (بدیهی است) ممنوع است و به RAII (بخش ۳) تکیه کنید.
- اجازه ندهید یک اشارهگر از محدوده آنچه به آن اشاره میکند فرار کند. این به این معناست که یک اشارهگر فقط در صورتی میتواند از یک تابع برگردانده شود که به چیزی استاتیک اشاره کند، به چیزی در حافظه آزاد (هیپ یا حافظه پویا) اشاره کند، یا بهعنوان آرگومان وارد شده باشد.
- فرض کنید تابعی (مثل vector::push_back()) که آرگومانهای غیرثابت میگیرد، نامعتبر میکند. اگر اشارهگری به یکی از عناصر آن گرفته شده باشد، فراخوانی آن را ممنوع میکنیم. توابعی که فقط آرگومانهای ثابت میگیرند نمیتوانند نامعتبر کنند، و برای جلوگیری از مثبتهای کاذب گسترده و حفظ تحلیل محلی، میتوانیم اظهارات تابع را با [[profiles::non_invalidating]] حاشیهنویسی کنیم. این حاشیهنویسی میتواند هنگام دیدن تعریف تابع اعتبارسنجی شود. بنابراین، این یک حاشیهنویسی ایمن است، نه یک حاشیهنویسی «به من اعتماد کن».
طبیعتاً، جزئیات زیادی برای رسیدگی وجود دارد، اما آنها در پیادهسازیهای آزمایشی و همچنین پیادهسازیهای در حال عرضه آزمایش شدهاند.
۶.۴. اجرا: پروفایلها
راهنماها خوب و مفید هستند، اما دنبال کردن آنها بهصورت مداوم در یک پایگاه کد بزرگ عملاً غیرممکن است. بنابراین، اجرا ضروری است. اجرای قوانینی که از مقداردهینشدن، خطاهای محدوده، ارجاعزدایی nullptr، و استفاده از اشارهگرهای آویزان جلوگیری میکنند، اکنون در دسترس است و نشان داده شده که در پایگاههای کد بزرگ مقرونبهصرفه است.
با این حال، قوانین بنیادی کلیدی باید استاندارد باشند – بخشی از تعریف سی++ – با یک راه استاندارد برای درخواست آنها در کد برای امکان همکاری بین کدهای توسعهیافته توسط سازمانهای مختلف و اجرا روی چندین پلتفرم و آموزش.
ما مجموعهای منسجم از قوانین راهنما که تضمینی را فراهم میکنند، یک «پروفایل» مینامیم. طبق برنامهریزی فعلی برای استاندارد، مجموعه اولیه پروفایلها (بر اساس پروفایلهای راهنماهای هسته که سالهاست استفاده میشوند) عبارتند از:
- نوع: هر شیء مقداردهیشده؛ بدون کستها؛ بدون یونیونها
- طول عمر: بدون دسترسی از طریق اشارهگرهای آویزان؛ بررسی ارجاعزدایی اشارهگر برای nullptr؛ بدون new/delete صریح
- محدودهها: تمام اندیسگذاریها بررسی محدوده میشوند؛ بدون حساب اشارهگر
- حسابی: بدون سرریز یا زیرریز؛ بدون تبدیلهای تغییر مقدار امضاشده/بدون امضا
این اساساً «هسته هسته» توصیفشده در بخش ۶.۱ است. با زمان و آزمایش، پروفایلهای بیشتری دنبال خواهند شد. برای مثال:
- الگوریتمها: تمام محدودهها، بدون ارجاعزدایی تکرارسازهای end()
- همزمانی: حذف قفلهای مرده و رقابتهای داده (سخت برای انجام)
- RAII: هر منبع متعلق به یک دسته (نه فقط منابع مدیریتشده با new/delete)
همه پروفایلها استاندارد ISO نخواهند بود. انتظار دارم پروفایلهایی برای حوزههای کاربردی خاص تعریف شوند، مثلاً برای انیمیشن، نرمافزار پرواز، و محاسبات علمی.
اجرا عمدتاً استاتیک (در زمان کامپایل) است، اما چند بررسی مهم باید در زمان اجرا باشد (مثل اندیسگذاری و ارجاعزدایی اشارهگر).
یک پروفایل باید بهصورت صریح برای یک واحد ترجمه درخواست شود. برای مثال:
[[profile::enforce(type)]] // بدون کستها یا اشیاء مقداردهینشده در این واحد ترجمهدر صورت لزوم، یک پروفایل میتواند برای یک دستور (از جمله دستورات مرکب) که لازم است، سرکوب شود. برای مثال:
[profile::suppress(lifetime))] this->succ = this->succ->succ;نیاز به سرکوب تأیید تضمینها عمدتاً برای پیادهسازی انتزاعهای موردنیاز برای ارائه تضمینها (مثل span، vector، و string_view)، تضمین بررسی محدوده، و دسترسی مستقیم به سختافزار است. چون سی++ نیاز به دستکاری مستقیم سختافزار دارد، نمیتوانیم پیادهسازی انتزاعهای اساسی را به زبان دیگری واگذار کنیم. همچنین – به دلیل گستردگی کاربردها و پیادهسازیهای مستقل متعدد – نمیتوانیم پیادهسازی تمام انتزاعهای بنیادی (مثل تمام انتزاعهای شامل ساختارهای پیوندی) را به کامپایلر واگذار کنیم.
۷. آینده
من تمایلی به پیشبینی درباره آینده ندارم، بخشی به این دلیل که این ذاتاً خطرناک است، و بهویژه چون تعریف سی++ توسط کمیته استاندارد ISO عظیم که بر اساس اجماع عمل میکند، کنترل میشود. آخرین باری که بررسی کردم، فهرست اعضا ۵۲۷ ورودی داشت. این نشاندهنده اشتیاق، علاقه گسترده، و ارائه تخصص گسترده است، اما برای طراحی زبان برنامهنویسی ایدهآل نیست و قوانین ISO نمیتوانند بهطور چشمگیر تغییر کنند. در میان موضوعات دیگر، کارهایی در حال انجام است در مورد:
- یک مدل عمومی برای محاسبات ناهمگام
- بازتاب استاتیک
- SIMD
- یک سیستم قرارداد
- تطبیق الگو به سبک برنامهنویسی تابعی
- یک سیستم واحد عمومی (مثل سیستم SI)
نسخههای آزمایشی همه اینها در دسترس هستند.
یک نگرانی جدی این است که چگونه ایدههای متنوع را به یک کل منسجم ادغام کنیم. طراحی زبان شامل تصمیمگیری در فضایی است که همه عوامل مرتبط نمیتوانند شناخته شوند، و نتایج پذیرفتهشده نمیتوانند برای دههها بهطور قابلتوجهی تغییر کنند. این با اکثر توسعه محصولات نرمافزاری و اکثر پیگیریهای دانشگاهی علوم کامپیوتر متفاوت است. این واقعیت که تقریباً همه تلاشهای طراحی زبان در طول دههها شکست خوردهاند، جدیت این مشکل را نشان میدهد.
۸. خلاصه
سی++ برای تکامل طراحی شده بود. وقتی شروع کردم، نهتنها منابع لازم برای طراحی و پیادهسازی زبان ایدهآلم را نداشتم، بلکه درک کردم که به بازخورد از استفاده نیاز دارم تا آرمانهایم را به واقعیتی عملی تبدیل کنم. و تکامل یافت، در حالی که به اهداف اساسی خود وفادار ماند. سی++ امروزی (C++23) تقریب بسیار بهتری به آرمانها نسبت به هر نسخه قبلی است، از جمله پشتیبانی از کیفیت کد بهتر، ایمنی نوع داده، قدرت بیان، عملکرد، و برای گستره بسیار وسیعتری از حوزههای کاربردی.
با این حال، رویکرد تکاملی مشکلاتی جدی ایجاد کرد. بسیاری از مردم با دیدگاهی قدیمی از چیستی سی++ گیر کردهاند. امروز، هنوز ارجاعات بیپایانی به زبان افسانهای C/C++ میبینیم، که معمولاً به این معناست که سی++ بهعنوان یک افزونه جزئی از سی دیده میشود که تمام بدترین جنبههای سی را همراه با سوءاستفادههای وحشتناک از ویژگیهای پیچیده سی++ در بر میگیرد. منابع دیگر سی++ را بهعنوان تلاشی ناموفق برای طراحی جاوا توصیف میکنند. همچنین، پشتیبانی ابزارها در زمینههایی مانند مدیریت بستهها و سیستمهای ساخت به دلیل تمرکز جامعه بر سبکهای قدیمیتر استفاده عقب مانده است.
مدل سی++ را میتوان بهصورت زیر خلاصه کرد:
- سیستم نوع استاتیک
- پشتیبانی برابر برای انواع داخلی و تعریفشده توسط کاربر
- معناشناسی مقدار و ارجاع
- مدیریت منابع سیستماتیک و عمومی (RAII)
- برنامهنویسی شیءگرا کارآمد
- برنامهنویسی جنریک انعطافپذیر و کارآمد
- برنامهنویسی در زمان کامپایل
- استفاده مستقیم از منابع ماشین و سیستمعامل
- پشتیبانی از همزمانی از طریق کتابخانهها (پشتیبانیشده توسط ویژگیهای داخلی)
زبان سی++ و کتابخانه استاندارد بیان عینی این مدل و بخش حیاتی اکوسیستمهای مورداستفاده برای توسعه نرمافزار هستند. ارزش یک زبان برنامهنویسی در کیفیت کاربردهای آن است.
- مرجع اصلی مقاله به همراه همهٔ مراجع علمی- ادامه مطلب...
-
- 0 دیدگاه
-

بررسی دیزاسمبلی x86 در لینوکس – کامپایلر gcc
به منظور بررسی دیزاسمبلی کد منبع C در لینوکس که محتوای آن در تصویر 2 نمایش داده شد، ابتدا خروجی تولید شده توسط کامپایلر gcc برای معماری x86 را توسط دیباگر gdb مورد بررسی قرار خواهیم داد. همانطور که در تصویر 12 قابل مشاهده است، وقتی کامپایلر باینری را با فلگ -ggdb کامپایل میکند، به دلیل وجود اطلاعات دیباگ درون باینری، دیباگر gdb میتواند اطلاعات تکمیلی و کامل درباره ساختار درونی باینری ELF ما نمایش دهد. برنامه ای که در تصویر 12 برای دیباگ باینری مورد استفاده قرار گرفته است، GDB Dashboard است که علاوه بر کد منبع، کد دیزاسمبلی، اطلاعات مرتبط با پشته و رجیسترها و خروجی که توسط کدها در حال تولید است، نمایش میدهد.
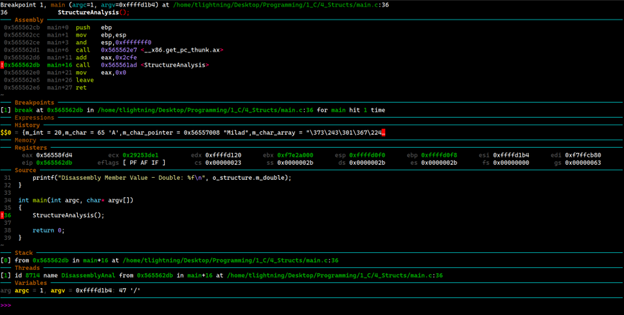
تصویر 12: خروجی دیزاسمبلی برنامه در محیط لینوکس
در ادامه به منظور درک بهتر کدی که توسط gcc برای معماری x86 تولید شده است، خط به خط مورد بررسی و تحلیل قرار خواهیم داد تا با رفتار کامپایلر gcc در تولید کدهای اسمبلی آشنا شویم. همانطور که در تصویر 13 قابل نمایش است، وقتی دستورالعمل call فراخوانی میشود، مجدد آدرس دستورالعمل بعدی را درون پشته قرار خواهد داد. آدرسی که توسط call بر روی پشته قرار گرفته است، در تصویر 13 با رنگ قرمز قابل مشاهده است.
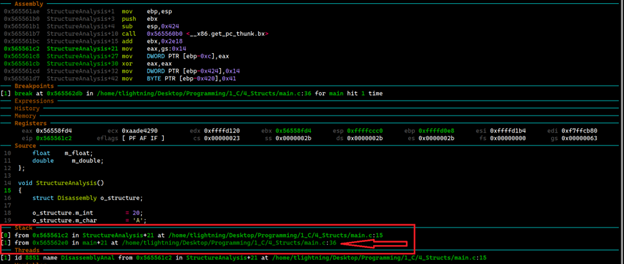
تصویر 13: خروجی اجرای دستورالعمل call
وقتی وارد تابع StructureAnalysis میشویم، در گام اول با Prologue تابع روبهرو خواهیم شد. در Prologue تابع StructureAnalysis بعد از اینکه فریم جدید تابع ایجاد میشود، مقدار 0x424 (1060 دسیمال) از مقدار جاری رجیستر ESP کم خواهد شد. این مقدار نشان میدهد که 1060 بایت برای ذخیرهسازی متغییرهای درون این تابع رزرو خواهد شد.
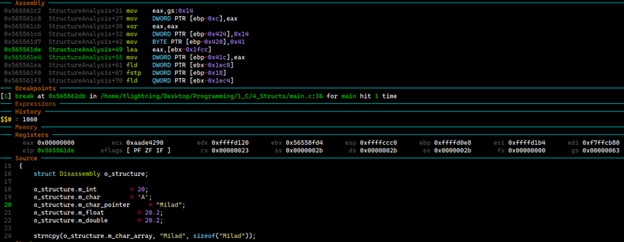
تصویر 14: دیزاسمبی مقداردهی اعضای Structure توسط GCC
خروجی که توسط کامپایلر GCC تولید شده است، مشابه خروجی MSVC است. متغیرهای درون Struct با استفاده از آدرس پایهای که درون رجیستر EBP قرار دارد، و همچنین آفستهایی که مشخص کننده اندازه متغیرها است، مقداردهی میشوند. برای کار با دادههای اعشاری هم از دستورات fld و fstp استفاده شده است. در نهایت وقتی استراکچر مقداردهی اولیه شد، برای نمایش مقادیر آنها به تابع printf عبور داده میشوند.
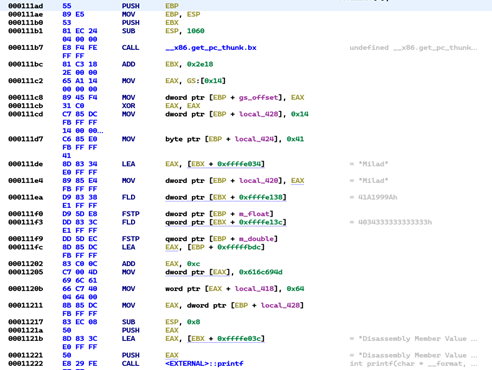
تصویر 15: خروجی دیزاسمبلی تابع StructureAnalysis
شایان ذکر است، در ابتدای هر تابع درون برنامه همانطور که در تصویر 15 و تصویر 16 قابل مشاهده است، یک تابع با نام __x86.get_pc_thunk.bx فراخوانی میشود. در تجزیه و تحلیل یک باینری لینوکس، تابع __x86.get_pc_thunk.bx معمولاً همراه با ثبت ebx برای محاسبه آدرس پایه یک بخش داده یا کد مستقل از موقعیت (PIC) استفاده میشود. هدف __x86.get_pc_thunk.bx این است که آدرس دستور بعدی را در رجیستر ebx بارگذاری کند. این امکان را فراهم میکند تا دستورات بعدی بتوانند از ebx به عنوان یک رجیستر پایه استفاده کنند تا به دادهها یا کدهای نسبت به موقعیت فعلی در حافظه دسترسی پیدا کنند. با استفاده از __x86.get_pc_thunk.bx و ebx، کدهای مستقل از موقعیت میتوانند به گونهای نوشته شوند که به آدرس مطلق کد یا داده وابسته نباشند. شایان ذکر است، پیادهسازی __x86.get_pc_thunk.bx ممکن است بسته به کامپایلر و توزیع لینوکس متفاوت باشد. این تابع معمولاً توسط کتابخانههای اجرایی کامپایلر یا کتابخانه C سیستم ارائه میشود. در تصویر 16، این موضوع قابل نمایش است.
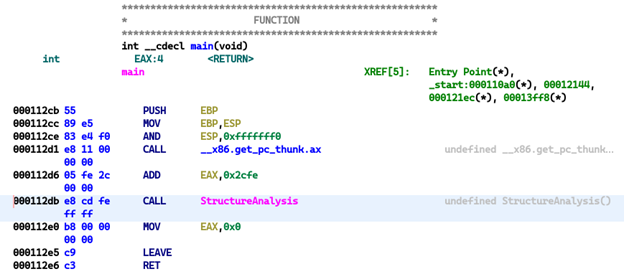
تصویر 16: نمایش فراخوانی __x86.get_pc_thunk.ax در ابتدای تابع main
بررسی دیزاسمبلی x86 در لینوکس – کامپایلر clang
خروجی که کامپایلر clang تولید میکند به مراتب از خروجی که توسط GCC و MSVC در مراحل قبلی تولید شده است، متفاوتر است. در ادامه خروجی نسخه 14 کامپایلر clang را برای برنامهای که به زبان C نوشته شده بود، مورد بررسی قرار خواهیم داد. در تصویر 17، ساختار دیزاسمبلی تابع main قابل مشاهده است که توسط کامپایلر clang تولید شده است. یکی از مهم ترین تفاوت هایی که در خروجی تولید شده توسط کامپایلر clang نسبت به gcc و msvc وجود دارد، در شروع توابع است. خروجی که clang تولید میکند، بعد از ایجاد فریم برای تابع، ما یک دستور call خواهیم داشت. هنگامیکه این دستور call اجرا میشود، تازه بدنه اصلی تابع شروع به اجرا خواهد شد.

تصویر 17: دیزاسمبلی کد تولید شده توسط clang
همانطور که در تصویر 17 قابل مشاهده است، در ابتدای تابع یک call به یک لیبل با عنوان LAB_000112EA داریم که از ابتدای آن اجرای بدنه اصلی تابع شروع میشود. تفاوت بعدی که وجود دارد، Calling Convention مورد استفاده توسط کامپایلر clang است که نسبت به msvc و gcc تفاوت دارد. به عنوان مثال، در تصویر 18 اصول عبور پارامترها به تابع printf قابل مشاهده است. در خروجی دیزاسمبلی clang به جای PUSH شدن پارامترها از راست به سمت چپ درون پشته، در خروجی clang از رجیسترها برای عبور پارامترها به توابع C استفاده میشود.

تصویر 18: نحوه عبور پارامترها به تابع
با توجه بررسی خروجی کامپایلرهای GCC و MSVC و Clang در پردازش Structها در زبان سی تفاوت برجسته ای وجود نداشت. هر سه کامپایلر برای مقداردهی اعضای استراکچر از آدرس پایه ای استفاده کرده بودند که توسط رجیستر EBP مورد ارجاع قرار میگرفت. دو کامپایلر GCC و MSVC از یک اصول تقریبا مشابهای دنباله روی می کردند، ولی clang به جای استفاده از Stack از رجیسترهای عمومی x86 برای عبور پارامترها به توابع استفاده میکرد.
پایان.
- ادامه مطلب...
-
- 0 دیدگاه
-

یکی از مهمترین و پرمخاطبترین سوألاتی که در مورد فریمورک کیوت پرسیده میشود، شرایط استفاده و مجوزهای مربوط به آن است؛ از آنجایی که این کتابخانه تحت پشتیبانی یک شرکت تجاری است، برخی از شرایط و قوائدی وضع شده است که در استفاده از آن باید دقت لازم را داشت. در این مقاله من قصد دارم به توضیحات و شفافسازی کامل در این خصوص بپردازم که امیدوارم از آن بهرهمند شده و به اشتراک بگذارید.
بررسی مجوزهای جامع Qt
ابزار Qt، یک چهارچوب قدرتمند برنامهنویسی چندسکویی است که انواع مختلفی از مجوزها را ارائه میدهد تا به نیازهای متنوع کاربران خود پاسخ دهد. با توجه به تاریخچهٔ غنیای که به آغاز توسعهٔ آن باز میگردد، Qt به تدریج به یکی از اصلیترین بازیگران در زمینه توسعه نرمافزار تبدیل شده است که در این مقاله به آن اشاره میکنیم.
Qt تحت چندین گزینه مجوز مختلف قرار دارد که برای توسعه نرمافزارهای مختلف مناسب هستند که به صورت زیر تعریف شدهاند.
-
مجوز تجاری Qt
- فریمورک کیوت، زیر مجوزهای تجاری مناسبی را برای توسعه نرمافزارهای تجاری فراهم کرده است که کاربران نمیخواهند کد منبع خود را با دیگران به اشتراک بگذارند یا نمیتوانند با شرایط نسخه 3 مجوز GNU LGPL (GNU Lesser General Public License) سازگاری یابند.
-
مجوز LGPL Qt
- این مجوز برای توسعه نرمافزارهای Qt مناسب است، تا زمانی که شما میتوانید با شرایط نسخه 3 مجوز GNU LGPL (یا GNU GPL نسخه 3) سازگار باشید.
- مجوز بازار Qt (Qt Marketplace)
- اجزای Qt تحت توافقنامه مجوز بازار Qt مناسب برای توسعه نرمافزارهای Qt هستند، معمولاً با شرایط مجوز تجاری یا GNU LGPL (یا GNU GPL نسخه 3) برنامهریزی میشوند.
استفاده از کد، از طریق مجوزهای متنباز
فریمورک Qt شامل کدهای شخص ثالثی است که تحت مجوزهای خاص متنباز از نویسندگان اصلی مجوزدهی شدهاند.
نقل قولتوجه: برخی از اجزاء (ماژولها) در Qt که تحت مجوز GNU LGPL نسخه 3 موجود نیستند، بلکه تحت مجوز GNU GPL (GNU General Public License) قرار دارند. برای اطلاعات بیشتر، لیست ماژولهای Qt را مشاهده کنید.
برخی از سوأل و پرسشهای جامعه و تیم کیوت در رابطه با مجوزها و اهداف آنها در توسعه
چرا Qt همچنین زیر مجوز نرمافزار متن باز نیز منتشر میشود؟
ما به جنبش نرمافزار آزاد اعتقاد داریم که استفاده از نرمافزار با حقوق وظایف خاصی همراه است. استفاده از مجوزهای نرمافزار متن باز، به کاربران چهار درجه اصلی از آزادی را در استفاده از برنامهها یا دستگاههای Qt میدهد:
- آزادی اجرای برنامه برای هر هدفی.
- آزادی مطالعه نحوه عمل برنامه و سازگارسازی آن با نیازهای خاص.
- آزادی توزیع نسخههای کپی شده تا بتوانید به همسایه خود کمک کنید.
- آزادی بهبود برنامه و انتشار بهبودهای خود به عموم، تا کل جامعه بهرهمند شود.
این آزادیها غیرقابل مذاکره و مطلق هستند، نمیتوان آنها را به صورت انتخابی یا جزئی تجربه کرد، شما همچنین موظف به انتقال آنها به کاربران خود هستید.
نقل قولجامعه نرمافزار آزاد به دلیل این قوانین به رشد پیشرفت کرده است، اما همچنین توسعهدهندگانی وجود دارند که هرگز نقشه ندارند یا نمیتوانند این قوانین را رعایت کنند و بنابراین باید مجوز تجاری بگیرند. شرکت Qt برای حمایت از هر دو گروه با ارائه مجوزهای دوگانه وجود دارد.
چرا شما توافقی با KDE در مورد مجوزهای خود دارید؟ KDE چیست و تاریخچهٔ Qt و KDE چگونه است؟
توافق بین Qt و KDE دربارهٔ مجوزها، ریشه در تاریخچهٔ مشترک این دو نهاد دارد. KDE (kde.org) مخفف محیط کاری دسکتاپ (Desktop Environment) است که یک جامعهٔ بینالمللی نرمافزار آزاد است و در سال ۱۹۹۶ تأسیس شد. KDE به خاطر محیط کاری Plasma Desktop شناخته میشود که به عنوان محیط کاری پیشفرض در بسیاری از توزیعهای لینوکس به کار میرود. نرمافزارهای KDE بر پایهٔ چارچوب Qt ساخته میشوند. در اوایل توسعهٔ Qt، این چارچوب از یک مدل مجوز دوگانه برخوردار بود و کد منبع آن تحت مجوزهای متن باز اختصاصی قابل دسترس بود. با درک اهمیت Qt برای پروژههای خود، KDE تلاش کرد تا توافقاتی برای اطمینان از دسترسی به Qt تحت مجوزهای مناسب متن باز، حتی اگر Trolltech (شرکت بنیانگذار Qt) به تصرف بشود یا ورشکست شود، به دست آورد. نتیجهٔ این تفاهم، بنیاد آزاد KDE Qt (KDE Free Qt Foundation) تأسیس شد و توافقنامه بنیاد آزاد KDE Qt ایجاد شد.
بنیاد آزاد KDE Qt یک سازمان با هدف ایمن کردن دسترسی به چارچوب Qt برای توسعهٔ نرمافزارهای آزاد و بهویژه برای توسعهٔ نرمافزارهای KDE است. این بنیاد در ابتدا توسط Trolltech و سازمان غیرانتفاعی حقوقی KDE (KDE e.V.) در سال ۱۹۹۸ تأسیس شد و یک توافقنامهٔ مجوز دارد که تأمین میکند که Qt برای پلتفرمهای اصلی دسکتاپ و موبایل تحت مجوزهای LGPLv3 و GPLv3 در دسترس است. این توافقنامه در طی سالها چندین بار بهروزرسانی شده است، عمدتاً به دلیل انجام معاملات مرتبط با Qt یا بهروزرسانی مجوزها و پلتفرمها.
عدم رعایت محدودیتهای مجوزهای LGPL/GPL چه تبعاتی دارد؟
اگر نرمافزاری که از این کتابخانههای مجوز متنباز استفاده میکند، به طور کامل الزامات مجوز را رعایت نکند، شما حق استفادهٔ مجوز و حقوق توزیع مرتبط با آن را از دست خواهید داد. همچنین لازم به ذکر است که در بیشتر کشورها، نقض حقوق نسخهٔ پدیدآورندگان یک نقض تشریعی است، نه نقض قرارداد، و بنابراین تدابیر تشریعی مرتبط با این موضوع اعمال میشود. برای کسب اطلاعات بیشتر در مورد GPL، میتوانید به صفحه FAQ GPL از لینک آن مراجعه کنید.
آیا میتوانم از نسخهٔ متن باز جوامع برای توسعه محصول تجاری خود استفاده کنم؟
این بستگی به نحوهٔ ارائه و ارائهٔ محصول شما دارد. نسخهٔ متن باز Qt اصلی به طور عمده تحت مجوز LGPL نسخه 3 و GPLv2/v3 منتشر میشود. شما باید الزامات مجوزهای این گونه را که در زمان استفاده از Qt در محصول خود باید رعایت کنید.
تفاوت بین LGPLv2 و LGPLv3 چیست؟
LGPLv3 نسخه فعلی مجوز GNU Lesser General Public License است. LGPLv2.1 یک نسخه قدیمیتر است و برای پروژههای جدید توصیه نمیشود. هر دو مجوز همان هدف را دارند، یعنی حفاظت از آزادی کاربران برای استفاده و اصلاح نرمافزار تحت مجوز LGPL.
LGPLv3 این هدف را به وضوح بیان میکند. شما باید چیزهایی را برای کاربر نهایی فراهم کنید تا نسخه اصلاح شدهٔ کتابخانه تحت مجوز LGPLv3 را نصب کرده و نرمافزار خود را با استفاده از آن کتابخانه اصلاح شده اجرا کند. در عمل، این به عنوان مثال به موارد زیر اشاره دارد:
- Tivoization – به وضوح اجازه ندهید دستگاههای بسته سازیشده ایجاد شود که کاربر نهایی حقوق مجوز LGPL برای کتابخانههای متن باز Qt را ندارد.
- DRM و رمزگذاری سختافزاری – نمیتوان از این تعهدات برای دور زدن این تعهدات استفاده کرد.
- انتقام از پتنت نرمافزار – جایی که تمام کاربران نرمافزار مجوزها را دارند، که این باعث بیمعنی شدن انتقام از پتنت نرمافزارهایی که ممکن است در نرمافزار منتشر شده، میشود.
وظایف من چیستند هنگام استفاده از Qt تحت مجوز LGPL؟
در ابتدا، باید توجه داشته باشید که تمامی ماژولهای متن باز Qt تحت مجوز LGPLv3 در دسترس نیستند. برخی از ماژولها برای استفاده در نرمافزارهای متن باز تحت GPLv3 قرار دارند و برخی از اجزاء توسعهیافته توسط شخص ثالث مانند موتور وب Chromium تحت مجوز LGPLv2.1 در دسترس قرار گرفتهاند.
زمانی که از ماژولها و کتابخانههای Qt تحت مجوز LGPLv3 استفاده میکنید، برخی از وظایفی که باید رعایت کنید به شرح زیر است:
- هنگام استفاده از نرمافزار متن باز، باید از مجوز هر نمونه، قطعه کد منبع، ماژول و کتابخانهای که در پروژه خود استفاده میکنید، آگاه باشید و مجوزهای مرتبط را ردیابی کنید.
- باید کد منبع کامل کتابخانههای Qt که استفاده کردهاید را به همراه تمام اصلاحات اعمال شده یا اعمال شده، به کاربران یا مشتریان خود ارائه دهید. به عنوان یک گزینه دیگر، میتوانید پیشنهاد نامهای با دستورالعملهایی در مورد چگونگی دریافت کد منبع ارائه دهید. لطفاً توجه داشته باشید که این باید تحت کنترل شما باشد، بنابراین ارائه یک لینک به کد منبع ارائهشده توسط پروژه Qt یا شرکت Qt کافی نیست.
- مجوز LGPL به شما این امکان را میدهد که کد منبع خود نرمافزار را به عنوان «کاری که از کتابخانه استفاده میکند» خصوصی نگهدارید. به طور معمول، در اینجا پیشنهاد میشود که از اتصال پویا استفاده کنید (برای کامپایل استاتیک این مورد مجاز نیست و نیاز به تهیهٔ مجوز دارد).
- کاربر نهایی باید قادر باشد نرمافزار شما را با یک نسخه مختلف یا اصلاحشده از کتابخانه Qt مجدداً لینک کند. با LGPLv3، به وضوح ذکر شده است که کاربر باید قادر باشد باینری مجدداً لینکشده را بر روی دستگاه هدف خود اجرا کند. این وظیفه به شما محول است که کاربر را با همه ابزارهای لازم برای فعال کردن این فرآیند تجهیز کنید. برای دستگاههای جاسازیشده، این شامل فراهمکردن تمام ابزارهایی است که برای کامپایل کتابخانه استفادهشده به کاربران مورد نیاز است. برای اجزاء مجوزده LGPLv3، شما موظف به ارائه دستورالعملهای کامل در مورد نصب کتابخانه اصلاحشده بر روی دستگاه هدف هستید (این با LGPLv2.1 به طور واضح بیان نشده است، اگرچه اجرای برنامه در برابر نسخهٔ اصلاح شدهٔ کتابخانه با هدف اعلام شده در مجوز است).
- کاربری که از یک برنامه یا دستگاه که از نرمافزار متن باز تحت مجوز LGPL استفاده میکند، باید از حقوق خود مطلع شود، با ارائه یک نسخه از مجوز LGPL به کاربر نهایی و نمایش اعلان مشهور در مورد استفاده شما از نرمافزار متن باز باید اعلام شود.
- این آزادیها به هیچ وجه توسط شرایط دیگر مجوز گزینشی نمیتوانند محدود شوند؛ اگر یک برنامه به کلی از تمام وظایفی که در بالا ذکر شده است پیروی نکند، اجازه توزیع آن به هیچ وجه داده نمیشود.
- همچنین باید اطمینان حاصل کنید که از هیچ ماژولی که تحت مجوز GPL استفاده نمیکنید.
آیا نیاز است که از مجوز LGPL هنگام استفاده از نسخهٔ تجاری Qt نگران باشم؟
به طور معمول، خیر. هنگام استفاده از نسخهٔ تجاری مجوزگذاری شده Qt، ما تقریباً تمامی بخشها را تحت شرایط یک مجوز تجاری ارائه میدهیم.
هرچند، چندین ماژول در Qt از کد منبع پروژههای متن باز شخص ثالث مانند Qt WebEngine استفاده میکنند که از پروژه Chromium با مجوز LGPLv2.1 استفاده میکند. بنابراین، هنگام استفاده از این ماژولها، شما باید از تعهدات مجوز مرتبط رعایت کنید، در مورد Chromium این موضوع به مجوز LGPLv2.1 اشاره دارد.
تمامی ماژولها و وابستگیهای شخص ثالثی که توسط ماژولهای مختلف Qt استفاده میشوند، در مستندات Qt برای هر نسخه از Qt مستند شدهاند.
به عنوان یک کاربر مجوز تجاری، در عمل، تنها نیاز دارید که به تعهدات مجوز LGPLv2.1 اهمیت بدهید، و تنها اگر از Qt WebEngine استفاده کنید.
چه کاری باید انجام دهم؟
مطمئن نیستم که مطابق مجوزهای متن باز هستم؟ از مجوزهای متن باز گیج شدهام، چه باید انجام دهم؟
همیشه خوشحال هستیم که با شما درباره وضعیتتان صحبت کنیم، اما ما در جایی نیستیم که مشاوره حقوقی ارائه دهیم. همیشه توصیه میشود با یک وکیل که با مجوزهای متن باز آشنا است، تماس بگیرید تا یک بررسی کامل از پروژه شما صورت گیرد و تصمیم گیری شود که آیا شما میتوانید تمامی تعهدات مجوزهای متن باز مربوطه (مانند LGPLv/GPLv) را انجام دهید یا خیر.
مجوز تجاری Qt چگونه کار می کند؟ آیا همه توسعه دهندگان من باید مجوز معتبر Qt داشته باشند؟
در رابطه با مجوزهای تجاری، هر کاربر Qt باید مجوز تجاری Qt مختص خود را داشته باشد. طراحان رابط کاربری، هنرمندان فنی، توسعهدهندگان نرمافزار یا مهندسان اتوماسیون تست ممکن است انواع مختلفی از مجوزهای Qt داشته باشند، اما هر فرد باید یک مجوز اشتراک معتبر داشته باشد.
آیا میتوانم کد نوشتهشده با Qt متن باز را با Qt تجاری مجوزگذاری شده ترکیب کنم؟
خیر.
اگر میخواهید از Qt متن باز به یک مجوز تجاری مهاجرت کنید، لطفاً با فروشگاه Qt تماس بگیرید.
برای این سوال، موارد بیشتری نیز در لینک FAQ مجوزگذاری تجاری Qt وجود دارد.
آیا امکان توزیع برنامههای توسعه یافته با نسخهٔ متن باز Qt از طریق فروشگاههای عمومی وجود دارد؟
هر فروشگاه اپلیکیشن شرایط و مقررات منحصر به فردی دارد که ممکن است با توزیع برنامهها تحت مجوزهای LGPL یا GPL سازگار یا سازگار نباشد.
مجوز تجاری Qt با شرایط و مقررات تمامی فروشگاههای اپلیکیشن معتبر سازگار است و بنابراین معمولاً بهترین گزینه برای توزیع یک برنامه به صورت منبع بسته در فروشگاههای مختلف است.
من شروع به توسعه یک محصول با استفاده از نسخهٔ متن باز Qt کردهام، حالا میتوانم یک نسخهٔ تجاری از Qt خریداری کرده و کدم را تحت آن مجوز قرار دهم؟
بله. پروژههای توزیعشده تحت نسخهٔ تجاری Qt نیز باید تحت نسخهٔ تجاری Qt توسعه یابند.
اگر قبلاً توسعه را با نسخهٔ متن باز Qt شروع کردهاید، ما به همکاری برای یافتن یک راهحل برای انتقال پایه کد شما از حاکمیت متن باز به مجوز تجاری میپردازیم.
اگر از ابتدا مطمئن نیستید که از کدام مجوز یا نسخه برای شروع توسعه استفاده کنید، توصیه میشود با The Qt Company تماس بگیرید تا بر اساس نیازهای توسعهی خود شما راهنمایی شود.
ممکن است در یک برنامه از کتابخانههای دارای مجوز LGPLv2.1 و LGPLv3 استفاده کرد؟
بله، امکان استفاده از هر دو نسخهٔ مجوز LGPLv2.1 و LGPLv3 در یک برنامه وجود دارد، به عنوان مثال با استفاده از آنها به عنوان کتابخانههای جداگانه به عنوان shared libraries. انجام این کار نیاز به تغییر مجوز در هیچ یک از کتابخانهها ندارد و در صورت نیاز، امکان انتخاب یک مجوز مولد برای برنامه وجود دارد.
ماتریس سازگاری GNU نشان میدهد که من نمیتوانم LGPLv2 و LGPLv3 را ترکیب کنم؟
اگر کد LGPLv2.1 و کد LGPLv3 در کتابخانههای جداگانه به عنوان shared libraries قرار داده شوند، میتوانند در یک برنامه استفاده شوند، و شما میتوانید برنامه خود را با یک مجوز مالکیتی / LGPLv2.1 / LGPLv3 به دلخواه خود مجوزگذاری کنید.
در مورد نسخهٔ مجوز LGPL/GPL که شما استفاده میکنید، چه کسانی مهم هستند؟
شما، مشتریان شما و کاربران نهایی، مگر اینکه از Qt تحت یک مجوز تجاری استفاده کنید. مجوزهای copyleft مانند LGPL و GPL به این معناست که مجوز با محصول شما به مشتریان و کاربران یا راهحل شما همراه میشود.
با توجه به تمامی توضیحات موجود، به طور خلاصه چه زمانی نیاز به تهیهٔ مجوزهای کیوت داریم؟
تهیهٔ مجوز کتابخانه Qt بستگی به نوع کاربرد و نیازهای پروژه دارد. جوانب مختلفی که تعیین میکنند چه زمانی نیاز به مجوز Qt داریم و چه مواردی ممکن است بدون نیاز به مجوز باشند.
-
استفادهٔ شخصی:
- نیاز به مجوز: اگر برنامهنویس قصد استفاده از Qt را برای توسعهٔ پروژهٔ شخصی و خصوصی دارد بدون انتشار کد منبع، نیاز به مجوز ندارد. در این حالت، میتوان از Qt به صورت رایگان استفاده کرد.
- بدون نیاز به مجوز: استفاده از Qt برای پروژههای شخصی بدون هدف انتشار کد منبع با محدودیتی همراه نخواهد بود.
-
توسعهٔ نرمافزار باز (Open Source):
- نیاز به مجوز: اگر قصد توسعهٔ یک نرمافزار منبع باز با Qt را دارید و میخواهید کد منبع خود را نیز تحت یک مجوز Open Source انتشار دهید، نیاز به مجوز GPL یا LGPL خواهید داشت.
- بدون نیاز به مجوز: اگر نیازی به انتشار کد منبع ندارید و از Qt برای پروژه منبع باز خود استفاده میکنید، میتوانید از نسخهٔ Qt با مجوز LGPL بدون مشکل استفاده کنید.
-
توسعهٔ نرمافزار تجاری (Commercial Software):
- نیاز به مجوز: اگر قصد توسعهٔ نرمافزار تجاری دارید و نمیخواهید کد منبع خود را انتشار دهید، نیاز به مجوز تجاری Qt دارید.
- بدون نیاز به مجوز: اگر از Qt برای توسعهٔ یک نرمافزار تجاری استفاده میکنید و توافق به اشتراکگذاری کد منبع ندارید، میتوانید از نسخهٔ تجاری Qt بهرهمند شوید.
-
توسعهٔ نرمافزار تحت LGPL:
- نیاز به مجوز: اگر میخواهید نرمافزار تجاری توسعه دهید، اما نیاز به استفاده از کتابخانه Qt دارید و میخواهید تغییرات خود را در کتابخانه منتشر کنید، باید از مجوز LGPL استفاده کنید.
- بدون نیاز به مجوز: اگر قصد استفاده از Qt را در یک نرمافزار تجاری با حفظ محرمانگی کد دارید، میتوانید از مجوز تجاری Qt بهرهمند شوید.
برخی از نکات را نیز باید در نظر بگیرید، مانند نوع کامپایل و نوع مجوزهای قابل پذیرش در فروشگاهها که عموماً همهٔ آنها را توضیح دادیم به چه صورت هستند.
- ادامه مطلب...
-
- 0 دیدگاه
-
مجوز تجاری Qt
-

شرکت اینتل یک کیت توسعه نرمافزار آزمایشی کوانتومی با نام Quantum SDK را منتشر کرد!
این کیت یک سری ابزار و روشهای برنامهنویسی را در اختیار توسعهدهندگان قرار میدهد که امکان برنامهنویسی الگوریتمهای کوانتومی را در یک شبیهسازی ممکن میکند. این کیت از زبان برنامهنویسی ++C و کامپایلر LLVM برای برنامهنویسی الگوریتمهای کوانتومی استفاده میکند و به سادگی میتواند با برنامههای C و ++C و پایتون به کار برده شود. این کیت، به نوعی باعث بزرگ شدن جامعهٔ توسعهدهندگانی میشود که در زمینهٔ کامپیوترهای کوانتومی فعالیت میکنند.
این عکس نشان میدهد که شرکت اینتل، و افرادی که در آن کار میکنند، با استفاده از یک دستگاه پردازشی ۳۰۰ میلیمتری، وافرین بر روی یک وافر کیوبیتی (بخشی از یک صفحه اتصال کوانتومی) سیلیسیوم بر روی یک ورقه کوچک انجام دادهاند.
نقل قولاین نقلقول بیان میکند که کیت توسعه نرمافزاری کوانتومی اینتل، به برنامهنویسان کمک میکند تا برای کامپیوترهای کوانتومی گسترده مقیاس آینده آماده شوند. این کیت نه تنها به توسعهدهندگان کمک میکند تا در شبیهسازی الگوریتمهای کوانتومی و برنامهها مسلط شوند بلکه با ایجاد یک جامعه از توسعهدهندگان به پیشرفت صنعت کوانتومی کمک میکند که باعث تسریع در توسعهی برنامههایی میشود که آمادگی آنها در هنگام قرار گرفتن سختافزار کوانتومی اینتل را دارند.
– آن ماتسورا، مدیر برنامههای کاربردی و معماری کوانتومی، آزمایشگاههای اینتل
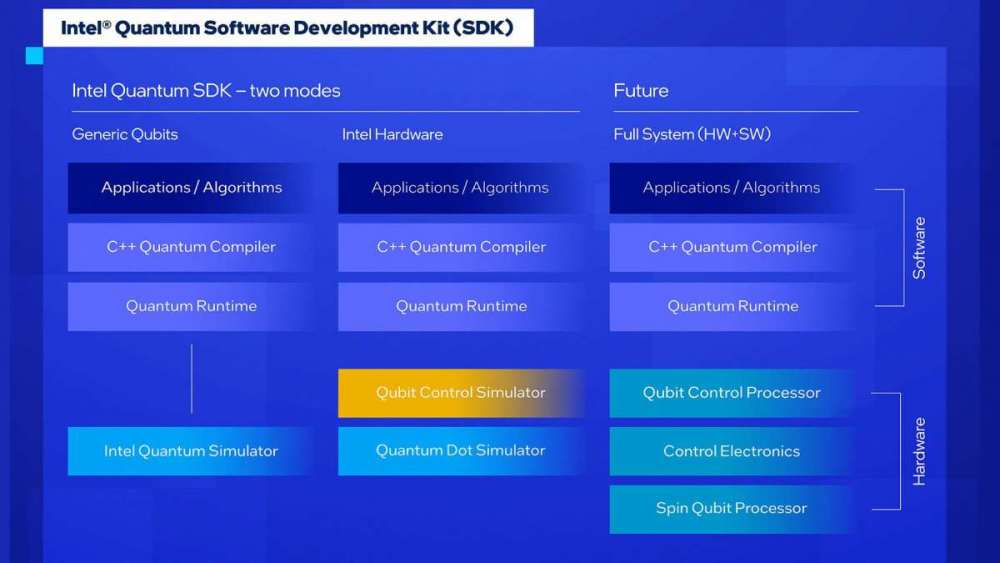
دربارهی Intel Quantum SDK 1.0: نسخهٔ 1.0 این SDK، شامل یک رابط برنامهنویسی مبتنی بر سیپلاسپلاس است که به برنامهنویسان کلاسیکی، زبان برنامهنویسی که با آن آشنایی دارند، را ارائه میدهد و امکان همکاری بین آنها و برنامهنویسان کوانتومی را فراهم میکند. این کیت نیز، یک محیط اجرایی کوانتومی بهینهسازی شده برای اجرای الگوریتمهای کوانتومی-کلاسیکی هیبریدی دارد. توسعهدهندگان میتوانند از دو محیط مختلف برای شبیهسازی کیوبیتها استفاده کنند، یکی برای نمایش بیشتر تعدادی کیوبیتهای عمومی و دیگری، برای شبیهسازی سختافزار کیوبیتی اینتل. محیط اولیه، یک شبیهساز کیوبیت عمومی بسیار عالی با کد منبع باز به نام Intel® Quantum Simulator (IQS) میباشد که برای 32 کیوبیت در یک گره و بیش از 40 کیوبیت در چندین گره، توانایی دارد. محیط دوم نیز با شبیهسازی سختافزار کیوبیتی اینتل، شبیهسازی کوچک مدل کیوبیتهای گرداننده اسپین سیلیکونی اینتل را فراهم میکند. کیوبیتهای اینتل، از تخصص شرکت در تولید ترانزیستور سیلیکونی برای ساخت کامپیوترهای کوانتومی مقیاس گسترده استفاده میکنند.
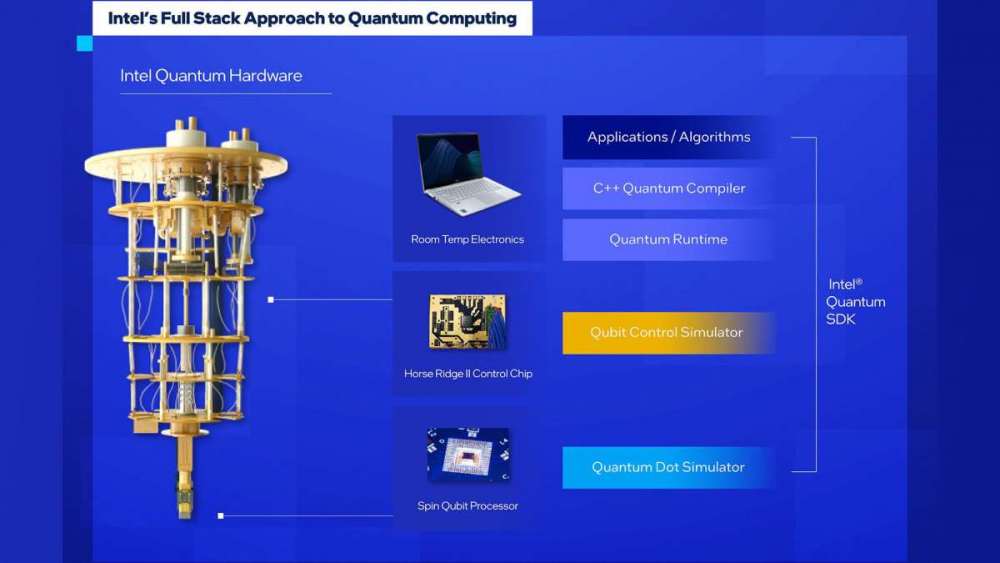
تحقیقات کوانتومی اینتل از دستگاههای کیوبیتی تا معماری سختافزار کلی، معماری نرمافزار و برنامهها را پوشش میدهد. Intel Quantum SDK یک کامپیوتر کوانتومی کامل در شبیهسازی است که همچنین قادر به اتصال به سختافزار کوانتومی اینتل، از جمله چیپ کنترل Horse Ridge II و چیپ کیوبیت گرداننده اسپین اینتل است که بزودی در اختیار عموم قرار خواهد گرفت.
کیت توسعهٔ کوانتومی اینتل، به توسعهدهندگان این امکان را میدهد که انتخاب کنند کدام یک از دو محیط موردنیاز برای شبیهسازی کیوبیتها استفاده شود:
- شبیهساز بسیار عالی و با کد منبع باز کیوبیت عمومی، شبیهساز کوانتومی اینتل (Intel Quantum Simulator)
- محیط هدف که سختافزار کیوبیتی اینتل را شبیهسازی میکند و به شبیهسازی مدل کوچک کیوبیتهای گرداننده اسپین سیلیکون اینتل امکان میدهد.

اعلام شده که شرکت اینتل، متعهد به پیشروی در حوزهٔ کامپیوترهای کوانتومی است و از جمله اینترنت از همه جا به عنوان یک روش برای جذب جامعهٔ توسعهدهندگان میباشد. کاربران بتا این کیت، در حال بررسی انواع موارد مثل دینامیک سیالات، فیزیک نجوم وطراحی مواد هستند.

تحقیقات کوانتومی اینتل از دستگاههای کیوبیتی تا معماری سختافزار کلی، کنترل و معماری نرمافزار و برنامهها را پوشش میدهد.
- ادامه مطلب...
-
- 0 دیدگاه
-

سلام و درود،
این اواخر راجع به مشورت و راهنماییها خیلی ساده به قضیه نگاه میشه، همه فکر کردن کشکه و فقط با دونستن JS یا QML میشه محصول ساخت. البته این مثال JS و QML یک مثال هست و این مسئله در همهٔ ابزارها و حول محور حوزهٔ کامپیوتر و نرمافزار به چشم میخوره، هرچند روی داستان ساده هست اما حتی پشت این کارهای ساده کلی زمان باید صرف بشه. همین گرفتن یک دادهٔ ساده از سمت سرور و تجزیه کردنش سمت JS نیاز به یک دانش خوب در مورد معماری Apiداره، نیاز به آگاهی از استانداردهای Http داره، نیاز به تخصص کافی در ریز به ریز مسائل داره، نیاز به آگاهی لازم در مورد شبکه و نحوهٔ مدیریتش داره، نیاز به درک خوب راجع به کلاسهای شبکه و نحوهٔ مدیریت بستهها داره و صدها جور مسئلهٔ دیگه.
یا راهنمایی نکنیم یا میکنیم همه چیز رو ساده نشون ندیم!
به خصوص برای کسایی که سالها یه چیز دیگه خوندن و الآن قراره وارد این حوزه بشن.
قشنگ واقعیت رو باید به نمایش گذاشت، و اگرنه به اشتراک گذاری چهارتا UI خفن که بگین با QML هم میشه کاری نداره، سه سوته میشه اینها رو طراحی کرد.اگر کسی اطلاعات کافی و پایهٔ تخصصی نداشته باشه و همینطور متکی به یک ابزار یا زبان پیش بره چه اتفاق میافته؟ از نظر من قطعاً بهتون از نظر تجربی آسیب میزنه، ساخت یک محصول واقعاً به این سادگیها نیست که تو گروههای تلگرامی داریم راجع بهش صحبت میکنیم! قضیه خیلی پیچیدهتر از اینهاست. فراموش نکن در این حوزه اگه یک کار ساده رو سریع انجام میدیم یا به نتیجه میرسونیم دلیلش به خاطر سالها زمان و تلاشه، امکان نداره کسی حتی با ۲..۳ سال تجربه یک کار رو سریع بتونه صفر تا صد انجام بده و مشکلی نداشته باشه یا نتیجهٔ اون در سطح یک استاندارد معتبر باشه.
ساخت محصول اصول داره که اولین مرحلش شفافسازی و نقشهٔ توسعه و ایدهپردازی درسته، نباید مثل بعضی از مشتریها باشه که پشت تلفن زنگ میزنن میگن یه سایت میخوایم یا یه اپلیکیشن چند میگیری و بعدش شروع کنن به چک و چونه زدن و شما هم کیف کنی بگی که آره دیگه مشتری دارم!
شما تا زمانی که جزء به جزء محصول رو آگاه نباشید، یعنی تا زمانی که دقیق متوجه نشید نیاز چی هست و روش حلش رو متوجه نباشید منطقی نیست که واردش بشید. چون همین مرحلهٔ نیازسنجی به قدری مهمه که فرآیند مسیر و نقشهٔ توسعهٔ یک محصول رو نشونتون میده و اگه درست تشخیص ندین و ابزارها و راهکارها رو درست انتخاب نکنید بی برو برگرد با مشکل مواجه میشید.
مشکلاتش میتونه به این صورت باشه:
- سردرگمی
- عدم توانایی کالبدشکافی مسئله
- عدم توانایی حل مسئله
- عدم توانایی انتخاب یک روش یا ابزار صحیح و مناسب
- عدم تعامل شما با مشتری
- عدم رضایت شما از حقالزحمه
- عدم رضایت مشتری از نتیجهٔ کار
- عدم توانایی در پاسخدهی به اعضا و شرکای کلیدی دیگه در محصولات تجاری و بزرگ!
- و هزاران مسئلهٔ دیگه که همشون نتیجهٔ تشخیص نا درسته.
- در کنارش مهمترین خاصیتی که پیدا میکنه این خواهد بود در اوج نادانی احساس خواهد کرد که همه چیز دان هست! به قولی همه چیز گیگ!از نظر من حداقل مواردی که (به طور خیلی خیلی خلاصه و محدود) نیاز هست تا یک متخصص بتونه پاسخگوی تصمیمگیری نقشهٔ توسعهٔ یک محصول برای مشتری در ابعاد مختلف و سطوح متفاوت از حوزههای موجود در قالب اصولی باشه به صورت زیر هستند:
۱- آشنا مبانی کامپیوتر که امر طبیعیه (شامل درک و فهم مسائل و نحوهٔ حلشون متناسب با پلتفرم اجرایی محصول)
۲- آشنا به ساختار نوع محصول استاندارد در یک حوزه مثل: وب، آیاواس، اندروید یا دسکتاپهای مختلف مثل لینوکس، مک و ویندوز، اینترنت اشیاء و دیگر موارد.
۳- آشنا به فلسفهٔ بکاند و فرانتاند یا ترکیبی از این دو به همراه ابزارهای مناسب.
۴- آشنا به اصول طراحی UI/UX به عنوان یک نیاز و یک فاکتور مهم در ساخت محصولی که وابسته به عملکرد کاربر داره و در حوزهٔ فرانتاند مهم و کاربردی هست.
۵- آشنا به اصول SOLID و امثالش مهم هستند.
۶- آشنا اصول برنامهریزی ساخت بانک اطلاعاتی، اینکه از چه بانک اطلاعاتیای استفاده کنی و چرا؟
۷- آشنا به ارتباطات دادهای، جداول و ارتباط بین فیلدها، جدوال و روشهای درست تبادل اطلاعات مابینی دادهها.
۸- آشنا و تسلط کافی به یک محیط توسعه و ادغام ابزارها و محیط طراحی برای هدف.
۹- آشنا به معماری ساختار و رابطهای برنامهنویسی (Api)
۱۰- آشنا به استانداردهای Http، درک و مدیریت درخواست، پاسخها و ...
۱۱- آشنا به الگوهای طراحی برنامهنویسی (DP)
۱۲- آشنا به روشهای نگهداری و آزمایش نرمافزار و کدها به خصوص درک مبحث Fault tolerance.
۱۳- آشنا به روشهای اطمینانسازی و ایمنسازی پردازشهای داخلی نرمافزار برای جلوگیری یا دشوار سازی نفوز و خرابکاری
۱۴- آشنا به روشها و معماریهای احراز هویت و نحوهٔ ادغامش با نرمافزار مثل:JWT, OAuth, AWS و غیره...
۱۵- آشنا به نوع پارادایمهای زبان برنامهنویسی، در قالبهای (دستوری) Imperative و (اعلانی) Declarative مثل OOP، functional و دیگر موارد.
۱۶- آشنا به سبک معماری نرمافزاری (Microservice یا مثلاً Monolith) مزایا و معایبشون.
۱۷- آشنا به سبک معماری طراحی مانند MVC در طراحی بدنهٔ محصول.
۱۸- آشنا به سبک و الگوهای طراحی ساختاری در بکاند مانند Builder، Abstract، Factory و غیره.
۱۹- آشنا به ساختار یک زبان (در صورتی که میخواین جوابگوی مسائلِ پیش آمده باشید) کالبدشکافی زیرپوستی و عمیق یک زبان مهمه.
۲۰- آشنا و درک کامپایلرها و مفسرها، تفاوتها و شیوههای عملکردیشون نسبت به کدهای بهینه شده و عادی.
۲۱- آشنا و درک مدلهای مختلفی از سیستمهای توزیع شده مثل IaaS، PaaS، SaaS یا FaaS.
۲۲- آشنا به ابزارهای ساخت و فرآیند کاری اونها مثل CMake، NMake، QMake و غیره.
۲۳- آشنا به روشهای مدیریت وابستگیهای نرمافزار و ابزارهای لازم برای بستهبندی بهتر خروجی.
۲۴- آشنا به روشهای کدنویسی قابل آزمایش (Unit Test) و استفاده از ابزارهایی مثل CTest, GTest, Catch2 و غیره.
۲۵- آشنا به توسعهٔ آزمون محور (Test Driven- Development)
۲۶- آشنا به گامها و شرایط نسخهنگاری و مراحل توسعهٔ نرمافزار (SDP)
۲۷- آشنا به روشهای امنیت در کد و توسعه به شیوههای بررسی از طریق Fuzz-Test، Sanitizer، آنالیزرهای پویا و ایستا و غیره...
۲۸-آشنا به قوائد طراحی بر پایهٔ خدمات مبتدی بر معماری ابری برای خدمات پیامی، وبسرویسها، پردازش و غیره.
۲۹- در سطوح وب آشنا به مکانیزم شاخص بندی، فاکتورهای SEO و شیوههای درست بهبود صفحات وب.
۳۰- آشنا به روشهای به کار گیری و پیادهسازی ثبت کنندهٔ وقایع در دل محصول و روشهای بازخورد برای توسعهٔ بهتر به همراه مانیتورینگ، نظارت و تریسینگ.
۳۱- در شرایط لزوم آشنا به نحوهٔ به کار گیری و دلیل استفاده از فناوریهایی مثل Redis، Memcached و غیره.
۳۲- آشنا و درک صحیح از مفاهیم همزمانی (Concurrency) و روشهای به کار گیری آن نسبت به زبان برنامهنویسی و شرایط مناسب استفاده.
۳۳- آشنا به سبک و قوائد و ساختار زبانهای برنامهنویسی و فرآیند ساخت و ترجمه.
۳۴- و تا صدها گزینهٔ دیگه میتونم لیست کنم اینجا که اگه انتخابتون زبانهای نزدیک به سیستم باشه این داستان در ادامهٔ این توضیحات سر به فلک میکشه نمونش کامپایلرها خودشون شونصد جور مباحث دارند، پلتفرمها ومعماریهای پردازندهای هم در این زبانها مهمن و شما حتی تا عمق سیستمعامل و رابطهای اونها و نحوهٔ رفتارشون باید اطلاعات کافی داشته باشید که هر کدوم به نوبهٔ خودشون هزاران صفحه میشه راجع بهشون کتاب معرفی کرد.این لیست چیزی بود که به زبان بسیار بسیار ساده شده و خیلی خلاصه به ذهنم رسید تا بدانید همچین هم الکی نیست ای عزیزانی که فتواهای صد من یه غاز میدین و این مسائل رو حل شده میدونید!
در ادامه اصل ماجرا خیلی فراتر از اینها هم هست که بخوای حساب کتاب کنی میبینی باید هفت خان رستم رو فتح کنی تا در تمامی سطوح پاسخگو باشی، این امر شدنی هست اما زمانی که شما محدود به یک موضوع باشید قطعاً درک همهٔ مسائل محدود و ناتوان در اجرای آن خواهید شد.
* وقتی میگم آشنا قطعاً در حد حروف الفبا کافی نیست، باید در حد نیاز تسلط و درک کافی ازشون وجود داشته باشه.
* همهٔ اینها رو باید در کمترین زمان ممکن نسبت به یک مشتری، محصول و نیاز تشخیص بدین و انتخاب کنید، به این کار میگن ارزیابی محصول بر اساس دانستههای فنی که تماماً متکی بر دانش و تجربهٔ شماست. (کارشناسی پروژه دقیقاً همین موضوع است).
* برای بهتر شدن و حرفهای تر شدن هم باید فراتر از اینها پیش برید و در قالب «مثلث دانش» بهبودش بدهید.
* محصولات معتبر جهانی حاصلِ چنین نقشههای پیشبردی هستند و اصول تخصصی و مهندسی رو رعایت میکنن تا به یک درجهٔ کیفی موفق و زبان زد میرسند. شاید این مسائل از نظر یک برنامهنویس ساده و نه چندان با تجربه مهم نباشه، اما در سطح کیفی یک محصول نرمافزاری همهٔ این مسائل مهم تلقی میشوند.برای همین میگم گولِ توصیههای ساده و ظاهر چهارتا برنامه یا کیوت، داتنت و امثال این ابزارها رو نخورید، پشت همهٔ نیازهای یک محصول به فاکتورهای بسیاری باید توجه کنید. فردا بخواهید بدون آگاهی در این مسائل وارد پروژههایی بشید که به ظاهر ساده هستند یا باید دست به گریبان دیگران باشید و توی گروهها مدام سوأل پرسی کنید و یا باید بیخیال آن شوید؛ چون به هیچ یک از این فاکتورهای مورد نیاز توسعه توجه نکردین! پس این اصول رو به عنوان سر نخ مطالعه کنید تا بخش بزرگی از سرگردانیهای شما حل شود.
این مواردی که این جا اشاره کردم، همونطور که گفتم بخش بسیار کوچکی از دنیای نیازمندیهای ساخت و ساز و طراحی یک محصول واقعی در پیرامون نرمافزار و کامپیوتر هست، اما یک دلگرمی بدم به کسایی که با خودشون فکر میکنند چنین مسیر یا نقشهای از راه که قراره پیش بگیرند سخته و همهٔ ماجرا این نیست (جزئیات رو در کتابها، موقعیت و فرصتهای شغلی، شکستها، موفقیتها و آزمون و خطاها یاد خواهند گرفت) و نتیجهٔ اون میتونه مطابق همین حکایت زیر باشه:
نقل قولحکایت برنامهنویسان، ابزارها، تجربه و تخصصی که در بازار بی ارتباط با آن نیست!
یک روز موتور یک کشتی بزرگی خراب شد.
مهندسان زیادی تلاش کردند تا مشکل را حل کنند اما هیچکدام موفق نشدند!
سرانجام صاحبان کشتی تصمیم گرفتند مردی را که سالها تعمیر کار کشتی بود، بیاورند...وی با جعبه ابزار بزرگی آمد و بلافاصله مشغول بررسی دقیق موتور کشتی شد.
دو نفر از صاحبان کشتی نیز مشغول تماشای کار او بودند.
مرد از جعبه ابزارش آچار کوچکی بیرون آورد و با آن به آرامی ضربه ای به قسمتی از موتور زد، بلافاصله موتور شروع به کار کرد و درست شد.یک هفته بعد صورتحسابی ده هزار دلاری از آن مرد دریافت کردند، صاحب کشتی با عصبانیت فریاد زد:
او واقعا هیچ کاری نکرد!
ده هزار دلار برای چه می خواهد بگیرد؟بنابراین از آن مرد خواستند ریز صورتحساب را برایشان ارسال کند؟
مرد تعمیر کار نیز صورتحساب را اینطور برایشان فرستاد:ضربه زدن با آچار: ۲دلار
تشخیص اینکه ضربه به کجا باید زده شود: ۹۹۹۸ دلارو ذیل آن نیز نوشت:
تلاش کردن مهم است.
اما دانستن اینکه کجای زندگی باید تلاش کرد میتواند همه چیز را تغییر بدهد. -

سلام.
عدم دسترسی به یک سیستم مناسب و با خبر نبودن از حساب کاربری گیت هاب خود یکی از مشکلاتی بود که در این چند ساله برنامه نویسان با آن روبرو بودند.
چک کردن حساب ایمیل در تلفن همراه می توانست تا حدودی به این موضوع کمک کند. اما یک اپلیکیشن اختصاصی برای این مورد می تواند این امر را به بهترین شکل پوشش دهد.
بعد از کارهایی که برروی اپلیکیشن رسمی شرکت گیت هاب برای پلتفرم iOS انجام شد و خوشبختانه بدون هیچ مشکلی در بزرگ رویداد و کنفرانس شرکت و مایکروسافت - GitHub Universe 2019 در تاریخ November 13-14, 2019 رونمایی شد. به عنوان یکی از اعضای شرکت این نوید را می دهم که نوبت به آن رسید تا اپلیکیشن برای اندروید نیز پیاده شود.
در حال حاضر این اپلیکیشن در حال توسعه است و هنوز رونمایی نشده است.
برای این اپلیکیشن میزان پشتیبانی API 21+ Android device در نظر گرفته شده است و خواهد توانست از نسخه Android 5.0 به بالا را پشتیبانی کند.
می توانید پیشنهادات و نظرات خود را نیز ایمیل کنید. Max [@] Asrez {.DOR.} com
Hi, I'm Max Base.
GitHub team did work on the official GitHub application for the iOS platform and fortunately unveiled at the big event and conference(GitHub Universe 2019 on November 13-14, 2019). As a member of the company, I have the promise that the app will launch for Android.
This app is currently under development and has not been unveiled yet.
This app is designed to support Android 21+ API and will support Android 5.0 or later.
You can also email your suggestions and comments. Max [@] Asrez {.DOR.} com
Best,
Max Base






با تشکر
-

- 4
نوشته - 0
دیدگاه - 9636
مشاهده
نوشتههای اخیر
دو هفته پیش، نشست ۲۰۱۸ سیپلاسپلاس آغاز شد. شرکت کنندهها مدالهای خودشان را دریافت کردند چرا که همه چیز با هماهنگی بسیار خوبی به پایان رسید. این رویداد به عنوان یکی از چندین رویداد مهم
C++بشمار میرود که هرساله توسط حامیان و علاقهمندانش برگزار میشود.سخنان کلیدی
امسال در این رویداد سه یادداشت کلیدی وجود داشت، که با حضور Andrei Alexandrescu ،Lisa Lippincott و Nicolai Josuttis ارائه شد.

اولین سخنران Andrei Alexandrescu بود، او این کنفرانس را با افکار و اندیشههای خودش برای شروع آغاز کرد عنوان موضوع آن به بَد بودنِ کپی
constexprازstatic ifاشاره میکرد. او یک سخنران سرگرم کننده است، بنابراین سخنرانی او بسیار طبیعی در مورد یادداشتهای خودش منعکس میشد. همچنین او به عنوان یک توسعهدهندهٔ ++C به نقاط بسیاری اشاره کرد که کمیتهٔ استاندارد سازی زبان حرفهای او را تایید میکرد.
سخنران دوم Lisa Lippincott روز دوم را با یک سخنرانی آغاز کرد که دیدگاههای مختلفی در مورد محاسبات و منطق که در آن به کار میرود ارائه داد. زمانی که مُجری لیزا را دعوت کرد، میدانست که این موضوع به عنوان یک نکته مهم برای فکر کردن است، چیزی که همه نمیتوانند به طور مستقیم آن را درک کنند و به آن دسترسی پیدا کنند. اما این تلنگری برای نحوهٔ درک کُد از دیدگاه ریاضی و دیدگاه جدیدی بود.

سخنران سوم و آخر Nicolai Josuttis بود که در مورد، او اولین سخنران در نشست Hartmut Kaiser در سال ۲۰۱۴ بود. در آن سخنرانی بسیار خوب درخشیده، بنابراین در قسمت سوم نقصهایی را با جزئیات در مورد نقاط خشن ++C نشان داد. این سخنرانی بسیار صادقانه بود! چرا که بسیاری از جزئیات خشن بودن سیپلاسپلاس را عنوان کرد که همگی با آن موافق بودند.
مذاکرات، مسابقه و گفتگوهای چند دقیقهای
جلسات و رویدادهای مرتبط با ++C همیشه گفتگوهای بسیار خوبی دارد، و با یک مسیر مشخص که هدفش آوردن سخنرانان جدید با دیدگاههای جدید است برگزار میشود. بازخورد سخنرانها در این رویداد خوب بود چرا که به برخی از نکات در مورد چگونگی بهبودها اشاره کردند.


تصویر بالا مربوط به Hana Dusíková است که میتوان به آن بهترین نمره را داد. بهترین سخنرانی هم مربوط به Andrei Alexandrescu بود که دنبال شد. در اولین عصر این رویداد، امتحان (Quiz) برجستهترین مورد رویداد در آن روز بود. سازماندهی آن توسط Diego و اسپانسری آن توسط Conan است که برای چند سال اخیر حمایت شده است. به نظر میرسید که سوالات امتحانی این سال سختتر از سوالات رویداد قبلی در سال گذشته بوده است. اما بار دیگر این سرگرمی ترکیب بسیار خوبی با ترس از سی++ را داشت.
هر یک از سوالات امتحانی یک خروجی از کُد را تولید میکردند، که هر گروه باید برای کسب امتیاز آن را مینوشتند. ده نوع کُد امتحانی وجود داشت که تهیه کنندهٔ گزارش برای به تصویر کشیدن آنها زیاد خوب عمل نکرده است. بنابراین تصویر زیر مربوط به سوالات چالشی در مورد سیپلاسپلاس است:

گفتگوهای کوتاه در طی جلسات سیپلاسپلاس صورت میگیرد. اما در سالهای گذشته روش به گونهای تغییر یافته است که سوالات پرسیده شده باید با گفتگوها و سوالات دیگر رقایبت میکردند. با این حال این یک قالب و روش جالبی بود که نتیجهٔ موفقیت آمیزی را داشت. همهٔ شرکت کنندهها میتوانستند این سوالات رو ببینند و در مورد آنها تفکر کرده و پاسخ دهند.
-
نقل قول
نتیجه : این رویداد بیشتر به عنوان یک دورههمی و گفتگو در مورد رفتارهای خشن زبان سیپلاسپلاس و پاسخهای سرگرم کننده در مورد آنها را فراهم کرده است و به ویژگیهای جدید زبان در آن پرداخته نشده است.
نکته: شما میتوانید تصاویر ویدیویی مربوط به این رویداد را از کانال رسمی آن در یوتیوب دریافت کنید.
- ادامه مطلب...
-
- 0 دیدگاه
- 4

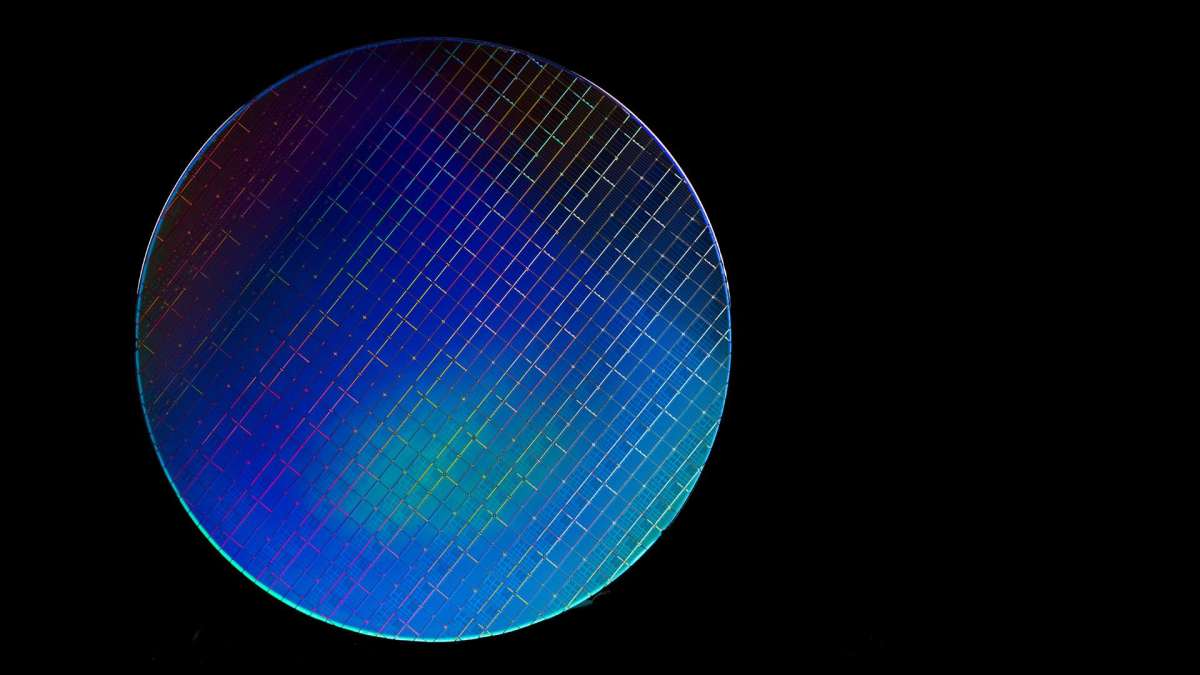

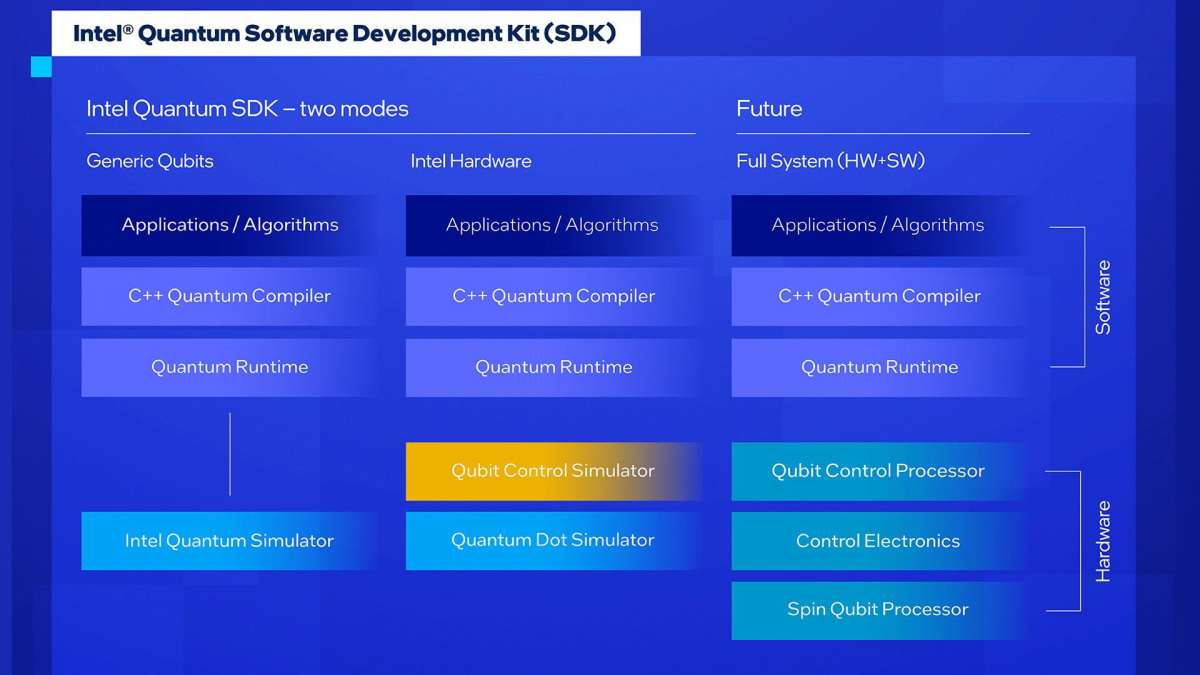


-
مقالات
-
- 3 دیدگاه
- 22,950 مشاهده
-

- دیدگاه توسط سید محمد
-
- 2 دیدگاه
- 8,755 مشاهده
-
- دیدگاه توسط کامبیز اسدزاده
-
- 0 دیدگاه
- 4,626 مشاهده
-
- نوشته شده توسط کامبیز اسدزاده
-
- 0 دیدگاه
- 4,206 مشاهده
-
- نوشته شده توسط کامبیز اسدزاده
-
- 0 دیدگاه
- 3,481 مشاهده
-
- نوشته شده توسط کامبیز اسدزاده
-
-
چه کسانی آنلاین هستند؟ 0 کاربر, 0 مخفی, 54 مهمان (مشاهده لیست کامل)
در حال حاضر هیچ کاربر عضوی آنلاین نیست