جستجو در تالارهای گفتگو
در حال نمایش نتایج برای برچسب های 'c++'.
36 نتیجه پیدا شد
-

نگارش 5.0
هدف از این آموزشها آشنایی با امکاناتی که در Qt میتوان استفاده کرد میباشد، که شامل کدنویسی کمتر، خروجی و طرح های بیشتر و در نهایت استفاده در پلتفرمهای مورد مختلف است. لذا جهت بهرهمندی از این کتابخانه ما با در نظر گرفتن اینکه علاقهمندان با زبان ++C آشنایی لازم را دارند منتشر کردهایم. بنابراین در صورتی که علاقهمندان اطلاعات کافی در رابطه با خود زبان ندارند پیشنهاد میکنیم ابتدا اقدام به تهیه و مطالعه آموزشهای لازم در ++C نمایند که برخی از لینکهای رسمی و استاندارد آن را در زیر اعلام نمودهایم. نوع این کتاب الکترونیکی است، بعد از پرداخت میتوانید بر روی دکمهٔ دریافت فایل در همین صفحه کلیک کرده و آن را دریافت نمایید. در صورتی که درگاه پرداختی با مشکل مواجه شده باشد، میتوانید به شماره کارت ۶۱۰۴۳۳۷۸۸۴۵۳۳۳۴۸ (بانک ملت) واریز و آن را به آدرس kambiz.ceo@gmail.com و یا شناسهٔ تلگرامی @Kambiz_Asadzadeh اطلاع دهید تا تأیید شود. عنوان این آموزش "برنامه نویسی ++C همراه با کتابخانه های Qt 5.12.x (سطح مقدماتی ویرایش ۵) میباشد که به صورت زیر فهرست بندی شده است: فصل اول مقدمه کتابخانه Qt قابلیت ها در طراحی فناوری Qt Quick و QML نسخه های کیوت مجوز های موجود در این کتابخانه محیط های توسعه کیوت ویژگی های کیوت پشتیبانی از انواع سیستم عامل ها نصب و پیکربندی Qt فصل دوم انواه پروژه و ایجاد آن انواع پروژه ها ایجاد پروژه فصل سوم ساده ترین برنامه معرفی و کار با Signal و Slot ها و Event ها معرفی و کار با نمایش Windows معرفی و کار با لایه ها زبانه ها و بدنه های در طراحی معرفی و کار با قابلیت های HTML و CSS در طراحی فصل چهارم معرفی و کار با لایه های افقی و عمودی معرفی و کار با لایه های Grid در طراحی فرم معرفی و کار با جدا کننده ها Splitter فصل پنجم معرفی و کار با دایرکتوری ها معرفی و کار با فایل ها / خواندن و نوشتن در آن ها فصل ششم معرفی و کار با برچسب ها Label معرفی و کار با دکمه ها Button معرفی و کار با کنترل ورودی LineEdit معرفی و کار با چک باکس CheckBox معرفی و کار با RadioButton معرفی و کار با Combobox معرفی و کار با لیست ها / ListWidget معرفی و کار با لیست های درختی / TreeWidget معرفی و کار با Action ها معرفی و کار با Slider و Progress ها معرفی و کار با Statusbar در فرم فصل هفتم معرفی و کار با MessageBox معرفی و کار با Timer معرفی و کار با Thread ها فصل هشتم معرفی و کار با Map معرفی و کار با Hash معرفی و کار با QStringList لیست رشته ای فصل نهم معرفی و کار با الگوریتم های معرفی و کار شبکه / دانلود فایل بر اساس پروتکل های HTTP و FTP معرفی و کار با باینری و سریالیز کردن آبجکت ها معرفی و کار با TextStream ها فصل دهم مقایسه انواع حالت های کامپایل در Qt نحوه افزودن دیگر کتابخانه های C++ در محیط Qt Creator و استفاده همراه با کتابخانه Qt نحوه خروجی گرفتن / گسترش (Deployment) در Qt مقایسه و پیکربندی دو موتور قدرتمند OpenGL و ANGLE در پروژه درایور دیتابیس هایی که تحت این کتابخانه پشتیبانی میشوند ساخت راهانداز دیتابیس در پلتفرمهای Linux، macOS و Windows حق نشر کتاب و اهداف در نسخهٔ بعدی کتاب توجه : در داشتن هر گونه انتقاد و پیشنهاد در رابطه با این کتاب با آدرس شخصی نویسنده (kambiz.ceo@gmail.com) مکاتبه نمایید. نکته دوم : کسانی که این کتاب را یک بار خریداری میکنند نسخهٔ به روز رسانی شده آن را به صورت رایگان میتوانند دریافت کنند.﷼۴٬۵۰۰٬۰۰۰
-
نهاییسازی ویژگیهای استاندارد ۲۳ و خلاصهای از جلسهٔ استانداردسازی WG21
کامبیز اسدزاده نوشته وبلاگ را ارسال کرد در فناوری
با سلام، با توجه به گزارش آنتونی پولوخین که یکی از اعضای کمیتهٔ استانداردسازی WG21 (سازمانی که توسعهٔ زبان برنامهنویسی سیپلاسپلاس را کنترل میکند). این کمیته سه بار در هر سال، هر بار در یک شهر جدید در سراسر جهان جلسه برگزار میکند. در طول این جلسات، پیشنهاداتی برای تغییر در زبان در نظر گرفته میشود. همچنین به توسعهدهندههای محلی سی++ کمک میکنند تا پیشنهادات خود را ارائه کنند. خلاصهای از جلسهٔ ماه جولای با هدف نهایی شدن استاندارد ۲۳ که نشان میهد پیشرفت بزرگی به عنوان ویژگیهای جدید استاندارد ۲۳ وجود دارد ارائه شده است: فهرست برخی از ویژگیها به صورت زیر آمدهاست: std:mdspan std:flat_map std:flat_set freestanding std:print("Hello {}", "world") formatted ranges output constexpr for bitset, to_chars/from_chars std::string::substr() && import std; std::start_lifetime_as static operator() [[assume(x > 0)]] 16- and 128-bit floats std::generator و البته ویژگیهای بسیار بیشتر از این. ویژگی std::mdspan از زمان اتخاذ عملگر opertator[] چند بعدی در آخرین جلسه، معرفیstd::mdspan به عنوان یک ویژگی سادهتر مطرح شده است و نتیجهٔ یک آرایهٔ چند بعدی غیر مالک به صورت زیر است: using Extents = std::extents<std::size_t, 42,="" 32,="" 64="">; double buffer[ Extents::static_extent(0) * Extents::static_extent(1) * Extents::static_extent(2) ]; std::mdspan<double, Extents=""> A{ buffer }; assert( 3 == A.rank() ); assert( 42 == A.extent(0) ); assert( 32 == A.extent(1) ); assert( 64 == A.extent(2) ); assert( A.size() == A.extent(0) * A.extent(1) * A.extent(2) ); assert( &A(0,0,0) == buffer ); این ویژگی حتی میتواند با سایر زبانهای برنامهنویسی خارج از جعبه کار کند. به عنوان مثال، در پارامتر الگوی سوم خود، std::mdspan میتواند یکی از چندین کلاس طرح بندی از پیش تعریف شده را بگیرد: نوعstd::layout_right: سبک چیدمان برای C یا ++C، سطرها دارای شاخص صفر هستند. نوعstd::layout_left: سبک چیدمان برای Fortran یا Matlab، ستونها دارای شاخص صفر هستند. شما می توانید تمام جزئیات را در سند P0009 بیابید. نویسندگان قول دادهاند که در آینده نزدیک نمونههای زیادی از std:mdspan جدید ارائه کنند. ویژگی std::flat_map و std::flat_set نگهدارندههای شگفتانگیز flat_* از کتابخانهٔ بوست، دیگر در استاندارد اصلی سی++ در دسترس هستند. این خاصیتها در کار با دادههای کم بسیار پرکاربرد هستند. در زیر ساختها، ظروف flat دادهها را در یک آرایه مرتب شده ذخیرهسازی میکنند که به طور قابل توجهی تخصیص حافظهٔ پویا را کاهش داده و موقعیت دادهها را بهبود میبخشد. علیرغم پیچیدگی جستجوی O(log N) و پیچیدگی درجO(N) در بدترین حالت، ظروف مسطح هنگام کار با مقدار کمی از عناصر بهتر از std:unordered_map عمل میکنند. در واقع، در طی فرآیند استانداردسازی، ظروف flat_* به عنوان آداپتور ساخته شدهاند. به این ترتیب، برنامهنویسان میتوانند از نگهدارندههای خود برای پیادهسازی اساسی استفاده کنند: template <std::size_t N> using MyMap = std::flat_map< std::string, int, std::less<>, mylib::stack_vector<std::string, N>, mylib::stack_vector<int, N> >; static MyMap<3> kCoolestyMapping = { {"C", -200}, {"userver", -273}, {"C++", -273}, }; assert( kCoolestyMapping["userver"] == -273 ); const auto& keys = kCoolestyMapping.keys(); // Inspired by Python :) assert( keys.back() == "userver" ); یک نکتهٔ جالب این است که استاندارد STL برخلاف پیادهسازی Boost، کلیدها و مقادیر را در نگهدارندهها جداگانه ذخیره میکند. این مکانِ کلیدیِ بهبود یافته، جستجوی ظرفِ flat را سریعتر میکند. رابط کاملstd::flat_set در سند P1222 توضیح داده شده است، در حالی که شرح رابط std:flat_map در سند P0429 موجود است. مستقل (Freestanding) استاندارد ++C میگوید که امکان پیادهسازی کتابخانهٔ استاندارد به صورت میزبان (hosted) یا مستقل (freestanding) وجود دارد. پیادهسازی میزبان نیاز به پشتیبانی سیستمعامل دارد و باید تمام روشها و کلاسها را از کتابخانهٔ استاندارد پیادهسازی کند. مستقل (freestanding) میتواند بدون سیستمعامل کار کند، سختافزار مهم نیست، و برخی از کلاسها و توابع را شامل نمیشود. تا همین اواخر، هیچ توضیحی برای ایستادن آزاد وجود نداشت و سازندگان سختافزارهای مختلف بخشهای مختلفی از کتابخانهٔ استاندارد را ارائه میکردند. این کارِ پورت کردن کد را سختتر کرد و محبوبیت ++C را در محیطهای تعبیهشده (امبدها) تضعیف کرد. بنابراین، زمان تغییر آن فرا رسیده است! سند P1642 مشخص کرده است که کدام بخش از کتابخانهٔ استاندارد برای freestanding اجباری است. ویژگی std::print روشهایی از کتابخانهء محبوب fmt در C++20 اضافه شد. این کتابخانه آنقدر راحت و سریع بود که برنامهنویسان شروع به استفاده از آن کرده و تقریباً در همهجای کد خود به کار بردهاند، از جمله برای خروجی قالببندی شده: std::cout << std::format(“Hello, {}! You have {} mails”, username, email_count); اما کدی مانند آن به دلایل زیر کامل نیست: تخصیص پویا اضافی. نیاز به std::cout جهت قالببندی خطوط از قبل قالب بندی شده. عدم پشتیبانی از یونیکد. کدی که اندازهٔ فایل باینری حاصل را افزایش میدهد. ظاهری نه چندان جذاب. بنابراین، تمام این مشکلات با اضافه کردن متدهایstd::print حل شد: std::print(“سلام, {}! به جامعهٔ {} خوش آمدید!”, name, community); میتوانید جزئیات، معیارها و گزینههای استفاده ازstd::print باFILE* و استریمها را در سند P2093 بیابید. خروجی قالببندی شده محدودههای مقدار به لطف سند P2286 و، std::format (و std::print) اکنون میتوانند محدودههایی از مقادیر را بدون در نظر گرفتن اینکه در یک ظرف هستند یا توسط std::ranges::views::* ارائه شدهاند خروجی بگیرند. std::print("{}", std::vector<int>{1, 2, 3}); // Output: [1, 2, 3] std::print("{}", std::set<int>{1, 2, 3}); // Output: {1, 2, 3} std::print("{}", std::pair{42, 16}); // Output: (42, 16) std::vector v1 = {1, 2}; std::vector v2 = {'a', 'b', 'c'}; auto val = std::format("{}", std::views::zip(v1, v2)); // [(1, 'a'), (2, 'b')] ویژگی constexpr اخبار تجزیه و تحلیل عالی برای توسعهدهندگانی که با کتابخانههای مختلف کار میکنند وجود دارد: خاصیتهایstd::to_chars/std::from_chars اکنون میتوانند در مرحله کامپایل برای تبدیل مقادیر صحیح از متن به باینری استفاده شوند. این نیز باید هنگام توسعه DSL مفید باشد. به نظر میرسد توسعهدهندههای روسی Yandex Go (به نقل از عضو کمیته) قصد دارند از آن در چارچوب کاربر برای بررسی پرس و جوهای SQL در مرحله کامپایل استفاده کنند. گزینهٔ std::bitset نیز تبدیل به constexpr شده است، بنابراین کار با بیتها در مرحلهٔ کامپایل اکنون بسیار آسانتر از قبل است. دانیل گوچاروف روی std::bitset در سند P2417 کار کرد و الکساندر کارائف در سند std::to_chars/std::from_chars P2291 به او پیوست. با تشکر فراوان از آنها برای این کار خوب انجام شده! ویژگی import std; با توجه به اینکه، اولین ماژول کامل(تمامعیار) به کتابخانهٔ استاندارد (STL) اضافه شد. اکنون میتوان کل کتابخانه را با یک خط بر سند وارد کرد: import std;. اگر کل ماژول کتابخانهٔ استاندارد به جای گنجاندن فایلهای هدر وارد شود، ساختها میتوانند تا ۱۱ برابر (گاهی اوقات حتی ۴۰ بار!) سریعتر شوند. میتوانید بنچمارک ها را در P2412 مشاهده کنید. اگر به ترکیب ++C و C و همچنین استفاده از توابع C از فضای نام جهانی عادت دارید، ماژول std.compat برای شما مناسب است. وارد کردن آن همهٔ توابع فایلهای سرآیند C مانند ::fopen و ::isblank و همچنین محتویات کتابخانهٔ استاندارد را در اختیار شما قرار میدهد. با وجود همهٔ اینها، سند P2465 که ماژولهای جدید را پوشش میدهد، در واقع آنقدرها هم طولانی نیست. ویژگی std::start_lifetime_as تیمور داملر و ریچارد اسمیت یک هدیهٔ فوقالعاده برای همهٔ توسعهدهندگانی که روی برنامههای تعبیه شده (امبد) و پربار کار میکنند گرد هم آوردهاند. اکنون تنها چیزی که برای کار کردن همه چیز نیاز دارید این است: struct ProtocolHeader { unsigned char version; unsigned char msg_type; unsigned char chunks_count; }; void ReceiveData(std::span<std::byte> data_from_net) { if (data_from_net.size() < sizeof(ProtocolHeader)) throw SomeException(); const auto* header = std::start_lifetime_as<ProtocolHeader>( data_from_net.data() ); switch (header->type) {> // ... } } به عبارت دیگر، میتوانید بافرهای مختلف را به ساختارها تبدیل کنید و با آنها بدون reinterpret_cast، کپی کردن دادهها یا خطر عملکرد برنامهتان کار کنید. همه چیز در سند P2590 شرح و مستند شده است. ویژگیهای شناورهای (اعشاری) 16 و 128 بیتی استاندارد ++C اکنون شامل std::float16_t، std::bfloat16_t، std::float128_t و نام مستعار برای اعداد موجود با ممیز شناور است: std::float32_t، std::float16_t. شناورهای 16 بیتی در هنگام کار با کارتهای ویدئویی یا یادگیری ماشین کمک میکنند. به عنوان مثال، float16.h میتواند از انواع جدید شناور کوتاه بهرهمند شود. شناورهای 128 بیتی برای محاسبات علمی شامل اعداد بزرگ بهترین هستند. سندِ P1467 ماکروها را برای بررسی پشتیبانی کامپایلر برای اعداد جدید توصیف میکند، و حتی خاصیتِ stdfloat.properties، در جدول مقایسه با توصیف اندازههای مانتیس و توان در بیتها وجود دارد. ویژگی std::generator زمانی که کروتینها در استاندارد C++20 پذیرفته شدند، ایده این بود که میتوان از آنها برای ایجاد «مولد» استفاده کرد: توابعی که وضعیت خود را بین تماسها به خاطر میآورد و مقادیر جدید را بر اساس آن حالت برمیگرداند. در استاندارد C++23 با اشاره به، std::generator به عنوان یک کلاس جدید یاد میشود که به شما امکان میدهد به راحتی ژنراتورهای خود را ایجاد کنید: std::generator<int> fib() { auto a = 0, b = 1; while (true) { co_yield std::exchange(a, std::exchange(b, a + b)); } } int answer_to_the_universe() { auto rng = fib() | std::views::drop(6) | std::views::take(3); return std::ranges::fold_left(std::move(rng), 0, std::plus{}); } در مثال فوق میتوانید ببینید که ژنراتورها با std::ranges چقدر خوب کار میکنند. std::generator کارآمد و ایمن است. کدی که به نظر میرسد یک پیوند معلق ایجاد میکند در واقع کاملاً معتبر است و هیچ مشکلی ایجاد نمیکند: std::generator<const std::string&=""> greeter() { std::size_t i = 0; while (true) { co_await promise::yield_value("hello" + std::to_string(++i)); // Everything is ok! } } میتوانید مثالها و توضیحاتی دربارهٔ نحوه کارکرد و استدلال پشت این رابط را در سند P2502 بیابید. سورپرایزهای دلپذیر کلاس string استاندارد برای متد substr() برای ارجاعات rvalue یک بازنگری اساسی (بهبود) دریافت کرده است: std::string::substr() &&. مانند مثال زیر: std::string StripSchema(std::string url) { if (url.starts_with("http://")) return std::move(url).substr(5); if (url.starts_with("https://")) return std::move(url).substr(6); return url; } این روش اکنون بدون تخصیص پویا اضافی کار میکند. اطلاعات بیشتر را میتوانید در سند P2438 بیابید. به لطف سند P1169، اکنون میتوانیدoperator() را ثابت اعلام کنید، که برای ایجاد CPO برای محدودهها در کتابخانه استاندارد عالی است: namespace detail { struct begin_cpo { template <typename T> requires is_array_v<remove_reference_t<T>> || member_begin<T> || adl_begin<T> static auto operator()(T&& val); }; void begin() = delete; // poison pill } // namespace detail namespace ranges { inline constexpr detail::begin_cpo begin{}; // ranges::begin(container) } // namespace ranges علاوه بر std::start_lifetime_as، تیمور داملر یک راهنمایی عالی برای بهینهساز ارائه کرد[[assume (x > 0)]]. اکنون میتوانید در مورد مقادیر احتمالی اعداد و سایر متغیرهای ثابت به کامپایلر نکاتی بدهید. برخی از مثالها و معیارها در سند P1774 کاهش پنج برابری در تعداد دستورالعملهای اسمبلی را نشان میدهند. این استاندارد همچنین دارای بسیاری از ویرایشهای جزئی، رفع اشکال و پیشرفتها بوده است، در اینجا منظور استاندارد ۲۳ است. در برخی مکانها، از سازندههای حرکتی (move constructors) به جای سازندههای کپی (copy constructors) استفاده شد (P2266). خوشبختانه برای توسعهدهندگان درایور، برخی از عملیات فرار دیگر منسوخ نمیشوند (P2327 با رفع اشکال در C++20). عملگر<=> کدهای قدیمی را کمتر میشکند (P2468)، کاراکترهای یونیکد اکنون میتوانند با نام استفاده شوند (P2071)، و کامپایلرها عموماً برای پشتیبانی از یونیکد (P2295) مورد نیاز هستند. الگوریتمهای جدید برای محدودهها (ranges::contains P2302, views::as_rvalue P2446, views::repeat P2474, views::stride P1899, و ranges::fold P2322) و std::format_string برای بررسیهای زمان کامپایل اضافه شد. std::format (P2508) و ماکروی #warning در (P2437). محدودهها (Ranges) یاد گرفتاند که چگونه با انواع فقط حرکت کار کنند (P2494). و در نهایت std::forward_like برای ارسال متغیرها بر اساس نوع متغیر دیگری اضافه شد (P2445). برای مدت طولانی، به نظر میرسید مهمترین نوآوری C++23 اضافه کردن std::stacktrace از RG21 بود، اگرچه در آخرین جلسه ویژگیهای مورد انتظار بسیاری اضافه شد. نوآوریهایی برای توسعهدهندگان تعبیه شده، شیمیدانان/فیزیکدانان/ریاضیدانان/...، توسعهدهندگان کتابخانههای یادگیری ماشین، و حتی توسعهدهندگانی که روی برنامههای کاربردی با بار بالا کار میکنند، وجود دارد. -
سلام. اگر بخوایم برای ضرب دو عدد با طول بی نهایت در یک ماشین حساب که در محیط QT ساخته شده است به شرطی که نتیجه ضرب را نشان دهد و overflow رخ ندهد، از چه کتاب خانه ای می توان استفاده کرد؟
-
جایزهٔ زبان برنامهنویسی سال TIOBE به ++C تعلق یافت!
کامبیز اسدزاده نوشته وبلاگ را ارسال کرد در ابزارها
در سالی که گذشت (۲۰۲۲)، سیپلاسپلاس محبوبترین زبان برنامهنویسی با رشد شاخص محبوبیت ۴.۶۲٪ انتخاب شد! جایزه زبان برنامهنویسی سال TIOBE به ++C تعلق گرفت! این جایزه به زبان برنامهنویسی تعلق میگیرد که بیشترین افزایش محبوبیت را در یک سال تجربه کرده است. شاخص TIOBE میزان محبوبیت زبانهای برنامهنویسی را اندازهگیری میکند. با این حال، قبل از نتیجهگیری، توجه به این نکته مهم است که Index (شاخص) نه چیزی در مورد کیفیت یک زبان برنامهنویسی میگوید و نه ادعا میکند. این رتبهبندی با تجزیه و تحلیل تعداد مهندسان ماهر در یک زبان خاص، تعداد دورههای آموزشی در آن زبان و تعداد فروشندگان شخص ثالثی که محصولات یا خدمات مرتبط با آن زبان را ارائه میدهند، محاسبه میشود. این فهرست ماهانه بهروز میشود و بر اساس دادههای موتورهای جستجوی محبوب مانند گوگل، بینگ و یاهو است. جایزهٔ زبان برنامهنویسی سال TIOBE در ژانویه هر سال بر اساس رتبهبندی سال قبل اعلام میشود. سیپلاسپلاس یک زبان برنامهنویسی در سال ۲۰۲۲ انتخاب شد که با محبوبیت رشد ۴.۶۲ درصد و بیشترین رشد انتخاب شده است. این زبان برنامهنویسی سطح بالا با کارایی بالا و چندمنظوره برای توسعهٔ نرمافزارهای سیستمی، برنامههای کاربردی و بازیهای ویدیویی با انعطافپذیری و قابلیت کنترل سطوح پایین است. این زبان در نوامبر ۲۰۲۲ جاوا را پشتسر گذاشت و به رتبهٔ سوم شاخص رسید و محبوبیت آن به طور پیوسته در حال افزایش است. نایب قهرمان در سال ۲۰۲۲ به ترتیب C با رشد ۳.۸۲ و پایتون با ۲.۷۸ درصد رشد بودهاند. -
یک سوأل بسیار مهم و پر مخاطب در بارهٔ زبانبرنامهنویسی سیپلاسپلاس در سالهای اخیر این است که «آیا جایگزینی برای این زبان وجود دارد و یا قابل جایگزین است»؟ در بسیاری از پاسخها نشان از گزینههایی مانند Go، Rust و D دیده میشود که بهتر است نسبت به نظرات متخصصهای برنامهنویسی به این موضوع پرداخته شود، ابتدا باید در نظر گرفت که هر ابزاری میتواند جایگزینی داشته باشد اما شرایط و نحوهٔ استفادهٔ آن در رابطه با نیاز متفاوت است. اخیراً سوألات زیادی در این موضوع دیده شده است که میگویند، Rust یک زبان برنامهنویسی ایمن، سریع و سیستمیِ جایگزین برای سیپلاسپلاس است! اما آیا واقعاً اینگونه است یا صرفاً ما بر اساس احساسات و اشتیاق به بهروز شدن به این موضوع میپردازیم؟ پاسخ برای این سوأل به صورت زیر در مدلهای مختلف میتواند مطرح شود که نتیجهگیری و تصمیم از خلاصهٔ آن به عهدهٔ خودِ شماست. من بر این باورم که زبانهای برنامهنویسی همه و همه در حال بهروز رسانی و بهتر شدن نسبت به نسخهها، استانداردها، و نسلهای گذشتهٔ خودشان هستند و به هیچ عنوان هیچ زبانی تا به امروز به طور جدی منسوخ شده اعلام نشده است. برای درک این مطلب بهتر است ابتدا به واژهٔ «منسوخ شده» یا «Deprecated» بپردازیم، این واژه زمانی مورد استفاده قرار میگیرد که شرایط زیر بر آن حاکم باشد: گزینهٔ مورد نظر به طور رسمی از طرف سازنده، پشتیبان یا صاحب آن بد دانسته شده و رسماً کنار گذاشته شود. گزینهٔ مورد نظر بهروز رسانی نشود و آخرین بهروز رسانی آن نیز شامل مشکلاتی باشد که بعد از مدتها نیز حل نشده باشد. گزینهٔ مورد نظر دیگر مورد استفاده قرار نگیرد و کاربردی هم در بین رقبای خود نداشته باشد. گزینهٔ مورد نظر دیگر پشتیبانی نشود و به قولی مُرده باشد. گزینهٔ مورد نظر به علاوهٔ این که شامل این موارد میشود، باید دارای یک جایگزین مناسب و عالی باشد. با توجه به این معیارها و با در نظر گرفتن رسالت هر یک ابزارها باید به آن توجه کرد که هر زبان یا ابزار برنامهنویسی خارج از این، در مرحلهٔ پیشرفت قرار گرفته است که آن نشان دهندهٔ زنده بودن و کاربردی بودن آن است. از طرفی، زبانی مثل سیپلاسپلاس جایگزین نمیشود چرا که هیچ یک از دلایل و معیارهای بالا شامل حال آن نمیشود، اتفاقاً برعکس این زبان دارای ویژگیهای معیاری زیر است: این زبان به طور رسمی توسط کمیتهٔ استانداردسازی که متعلق به هیچ یک از شرکتهای غول صنعتی و یا خصوصی نمیباشد پشتیبانی میشود. این زبان به طور مداوم در حال بهروز رسانی است و کاربردهای چند-منظوره و همه جانبهٔ خود را داراست. این زبان از ویژگیهای از ویژگیهای بسیار خوب به همراه سریعترین بازدهیها را داراست. این زبان رقیبهای بسیاری دارد، اما هیچ کدام از آنها هنوز در عمل و دامنهٔ وسیعی موفق به نمایش عملکرد بهتری نبودهاند. این زبان همانند دیگر ابزارها دارای مشکلاتی است، اما با توجه به پوشش و پشتیبانی از ویژگی BC در روند استانداردسازی و بهروز رسانی به خوبی از پس آنها بر آمده است. برای مثال، زبان جاوا یکی از بهترین زبانهای برنامهنویسی است و خیلی از شرکتها مانند گوگل در سیستمهای توزیع شده از آن استفاده میکنند. اما به معنای این نیست که به سرعت سی++ میرسد و در حد مقایسه با آن است. این زبان میتواند دهها و صدها برابر کندتر از سی++ باشد و این مربوط به طراحی، ساختار و مسائل مربوط به زبان است. از طرفی سیپلاسپلاس محبوب است زیرا که ویژگیهای زیر را دارد و طی سالهای بسیاری آن را ثابت کرده است: کارآیی (پرفرمنس) و سرعت فوقالعادهٔ این زبان، البته خیلی از زبانها ادعا میکنند که همچین ویژگیای را دارند که در عمل نتیجهٔ جالبی مشاهده نمیشود. ذاتِ چند-سکویی و چند-منظوره بودن آن، حداقل همهٔ سیستمها میتوانند کدهای سی++ را کامپایل و اجرا کنند. این زبان به راحتی میتواند با زبانها و فناوریهای دیگری ارتباط برقرار کرده و با آنها تعامل داشته باشد. این زبان به عنوان یکی از کممصرفترین زبانهای برنامهنویسی از نظر مصرف انرژی محسوب میشود. بسیاری از مهندسین این زبانها را به صورت مقطعی و بارها دیده و با آن آشنا هستند. کتابخانههای پیشفرض استاندارد STL و دیگر کتابخانههای سی++ بسیار قدرتمند و گسترده هستند. کتابخانههای نوع سوم (Third-Party) بسیار قدرتمند و بهروز هستند. اولویتهای سیستمهای یونیکس و حتی ویندوز اکثراً بر روی C و ++C است و بازنویسی آنها با زبانهای دیگر هزینهٔ بسیاری را به ارمغان میآورد. بسیاری از وابستگیهای ایجاد شده در سالهای بسیار طولانی بر اساس سی و سی++ بوده و بازنگری و بازنویسی آنها مشروط بر این که رابطها باید بازنویسی شود بسیار سخت و کاری مشابه اختراع دوبارهٔ چرخ است. عملکرد تا حدی قابل پیشبینی است و میتواند آن را درک کرد، چیزی که در زبانهایی مانند جاوا، سیشارپ و گو نمیتواند پیشبینی کرد چرا که پیشبینی چرخهٔ GC دشوار است، هیچ رقیب جدیای در این باره در سطح سی++ وجود ندارد که مدیریت حافظه را برای شما در قالب یک RAII ارائه کند، هرچند در مورد Objective-C و Rust میتوان آنها را به صورت جداگانه مورد بررسی قرار داد و نه عین آن. پشتیبانی از پارادایم (سبک)های طراحی را سی++ به خوبی پشتیبانی میکند، برای مثال برنامهنویسی عمومی در زمان کامپایل را به خوبی ارائه میکند. پشتیبانی از برنامهنویسی سیستمی و سطح پایین در این زبان یک مزیتی دیگری است که در کنار تمامی ویژگیهای سطح بالای خود ارائه میکند. اما در این میان زبانهایی مثل Rust، Go، Swift و غیره ادعای جایگزینی را دارند اما ادعاهای فنی به تنهایی کافی نیستند، در دسترس بودن گسترده از جامعه به اندازهٔ کافی به همراه جامعهٔ معتمد به آن مهم است. علاوه بر ویژگیهای فنی زبان سی++، یک نقطه قوت بسیار مهم این زبان در بحث غیر فنی آن است، در واقع در پشت این زبان نه یک پیادهسازی محدودی وجود دارد و نه یک سازمان که در آینده در مورد آن تصمیم بگیرد و آن را کنترل کند. در حالی که تمامی زبانهای مطرح و ادعا کننده داخل یک چهارچوبی کنترل میشوند که به شدت آیندهٔ آنها را تیره و تار میکند. به طور کلی آزاد بودن یک ابزار و قدرت یک جامعه فارغ از جغرافیا، سازمان، نژاد و زبان یک قدرت بسیار خارقالعادهای را برای یک ابزار به ارمغان میآورد که به تنهایی بسیار اهمیت دارد. در این اواخر بسیاری از مهندسین به فکر بازنویسی بسیاری از موارد شدن و تحقیقات نشان میدهد ابزارهایی گرافیکی بسیار قدرتمند و سریع که اخیراً طراحی شدهاند، مانند وُلکان که با سی++ نوشته شده است زمانی میتوانند با راست و زبانهای دیگر امروزی بازنویسی شوند که یک سیستمعامل جدید با زبانهای جدید ساخته شود! بنابراین صرفاً میتوان یک نسخهٔ Wrapper یا همان (پوشنده) چرا که تقریباً همهٔ سیستمعاملهای مدرن امروزی با زبانهای سی و سی++ نوشته شدهاند. از طرفی تولید یک سیستمعامل بسیار پر خطر است و سرمایهگذاری کلان، زمان و هزینههای بسیاری را میطلبد و تا زمانی که چنین نرمافزارهایی تحت سلطهٔ زبانهایی مانند سی++ قرار گرفته باشند پادشاهی سیپلاسپلاس ادامه خواهد داشت. نکتهٔ پایانی من معتقدم هر ابزار و زبانهای برنامهنویسی جایگاه و شرایط استفادهٔ خودشان را شامل میشوند، دقیقاً مانند ابزارهای موجود در یک جعبهابزار بهتر است ابزارهای خود را طوری بچینید که در جای لازم از مناسبترین آنها استفاده کنید. با این حال زبانها و ابزارهای مانند سی یا سی++ طی سالها ثابت کردهاند که معمولاً در همهٔ حوزهها غالب هستند و میتواند هر کاری را که بخواهید با آنها انجام دهید و یا با یک جایگرین مناسب آن را مدیریت کنید و این بستگی به مهارت و انتخاب شخصی شما دارد. همچنین صحبتهای اخیر کمیتهٔ استانداردسازی در رابطه با نحو ۲ از سیپلاسپلاس میتواند مفهوم خوبی در آیندهٔ این زبان باشد. مقالات مرتبط با این موضوع که میتواند به عنوان مکملی از پیش تعریف شده برای شما مفید باشد:
-
سلام.وقتتون بخیر. من مدتی هست که با کتابخانه Qt کارمیکنم و از فناوری Qt Quick استفاده میکنم.مشکلی که دارم مشکل واکنش گرا کردن سایز متن هست این اصلی ترین مشکل من در طراحی با QML است. کتاب استاد اسد زاده رو نیز تهیه کردم ولی درمورد واکنش گرا بودن توضیح کم بود و نتونستم مثال کاربردی و درکل درکی از این موضوع داشته باشم. ممنون میشم اگر این موضوع و نحوه ریسپانسیو کردن سایز متن رو کسی توضیح بده. اگر با مثال باشه خیلی عالی میشه?
-
با سلام و وقت بخیر چگونه identifier جدیدی در ++visual studio C تعریف کنیم؟ Error (active) E0020 identifier "mexPrintf" is undefined Error (active) E0020 identifier "vector" is undefined Error (active) E0020 identifier "mxArray" is undefined
-
با سلام و وقت بخیر به کمک نرم افزارCmake، کتابخانه های مربوطه ایجاد شدند. در visual studio هنگام RUN_TESTS_PARALLEL, build با این خطا مواجه شدم: Error MSB6006 "cmd.exe" exited with code 8. RUN_TESTS_PARALLEL C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\V140\Microsoft.CppCommon.targets 171 چطور می توانم این خطا را برطرف کنم؟
-
سلام، بنده حدود 6 ماهه که برنامه نویسی با پلتفرم اندروید رو شروع کردم ولی امروز بعد از صحبت با یکی از دوستان برنامه نویس ++C دودل شدم که اندروید رو ادامه بدهم یا یادگیری زبان ++C رو شروع کنم. حالا ممنون میشم بنده رو راهنمایی کنید.
-
سلام دسترسی به اعضای nested یک repeater به چه صورتی هست؟ من با استفاده از دستور زیر به جواب نرسیدم : repeater.itemAt(id).children[0].children[0].children[0].color = "red"; Repeater { id: repeater model: 5 Rectangle { property int radius: 15 gradient: Global.Theme width: radius Button { id:control x: 20 y : -25 Text { id : saveId// saveId text: qsTr(Global.textArray[index]) font : myFont color: Global.Theme ? Global.fontColor_gray : "red" anchors.verticalCenter: parent.verticalCenter anchors.horizontalCenter: parent.horizontalCenter } InnerShadow { //anchors.fill: parent cached: true visible: true horizontalOffset: 0 verticalOffset: 0 radius: 8 samples: 16 color: Global.Theme ? Global.innerShadowColor_gray : "red" smooth: true source: saveId } DropShadow { anchors.fill: saveId source: saveId verticalOffset: 4 //color: "#80000000" color: Global.Theme ? Global.dropShadowColor_gray : "red" radius: 30 samples: 300 } background: Rectangle { implicitWidth: 130 implicitHeight: 55 border.width: control.activeFocus ? 2 : 1 border.color: "darkgray" radius: 10 gradient: Global.Theme ? gradientProvider.gradientThem_1 : gradientThem_0 } onClicked: { } } } }
-
فرض کنیم متدی به نام Calculate برای یکی از کلاسها درون برنامه وجود دارد و برحسب شرایطی فرا خوانی میشود. آیا راهی وجو دارد که بتوان کد داخی آنرا تغییر داد طوری که بعد از تغییر برنامه کد تغییر یافته را اجرا کند همانند proceger در sql server
-
سلام.من یه برنامه ی ساده Hello Word در eclipse و به زبان c++ نوشتم ولی وقتی به پوشه برنامه میرم و فقط فایل EXE رو اجرا میکنم پنجره cmd خیلی سریع باز و بسته میشه و چیزی قابل رویت نیس. دستورات getch() و system("pause") رو هم امتحان کردم ولی نشد.نمیدونم چیکار باید بکنم.کتابخانه ی خاصی و یا دستور خاصی رو باید بنویسم؟ ممنون میشم کمکم کنید
-
در این مقاله من قصد دارم در رابطه با تفاوتهای اختصاص دادن حافظه در اِستَک و هیپ توضیحاتی دهم که بسیاری از علاقهمندان راجع به آنها سوال کردهاند. با توجه به اینکه، از اوایل سیستمهای کامپیوتری این تمایز در این وجود داشته است که برنامه های اصلی در حافظه فقط خواندنی مانند ROM ، PROM و یا EEPROM نگه داری میشوند. به عنوان دیگر از زمانی که سیستم ها پیچیدهتر شدند برنامهها از حافظههای دیگری مانند RAM به جای اجرا در حافظه ROM استفاده کردند. این ایده به خاطر این بود که تعدادی از قسمت های حافظه مربوط به برنامه نباید تغییر یابند و در این حالت باید حفظ شوند. در این میان دو بخش .text و .rodata بخشیهایی از برنامه هستند که میتواند به بخش های دیگر برای وظایف خاص تقسیم شوند که در ادامه به آنها اشاره شده است. بخش کد، به عنوان یک بخش متنی (.text) و یا به طور ساده به عنوان متن شناخته میشود. جایی است که بخشی از یک فایل شیء یا بخش مربوطه از فضای آدرس مجازی برنامه که حاوی دستورالعمل های اجرایی است و به طور کلی فقط خواندنی بوده و اندازه ثابتی دارد میباشد. بخش .bss که به عنوانی بخشی ویژه (محل نگه داری اطلاعات تخصیص داده نشده (مقدار دهی نشده)) محلی که متغیرهای سراسری و ثابت با مقدار صفر شروع میشوند. بخش داده (.data) حاوی هر گونه متغیر سراسری و یا استاتیک که دارای یک مقدار از پیش تعریف شده هستند و میتوانند اصلاح شوند. تصویر زیر طرح معمولی از یک حافظه برنامه ساده کامپیوتری را با متن، داده های مختلف، و بخشهای استک و هیپ و bss را نشان میدهد. .section.data < initialized data here> .section .bss < uninitialized data here> .section .text .globl _start _start: <instruction code goes here> برای مثال در کد C به صورت زیر خواهد بود: int val = 3; char string[] = "Hello World"; مقادیر برای این نوع متغیرها در ابتدا در حافظه فقط خواندنی ذخیره میشوند. (معمولا در داخل .text) و در زمان اجرای برنامه که به صورت روتین خواهد بود در بخش .data کپی میشوند. بخش BSS یا همان .BSS در برنامهنویسی کامپیوتر، نام .bss یا bss توسط بسیاری از کامپایلرها و لینکرها برای بخشی از دیتا سِگمنت (Data Segment) استفاده میشود که حاوی متغیر های استاتیک اختصاصی که تنها از بیت هایی با ارزش صفر شروع شده است میباشد. این بخش به عنوان BSS Section و یا BSS Segment شناخته میشود. به طور معمول فقط طول بخش bss نه data در فایل آبجکت ذخیره میشود. برای نمونه، یک متغیر به عنوان استاتیک تعریف شده است static int i; این در بخش BSS خواهد بود. حافظه هیپ (Heap) ناحیهٔ هیپ (Heap) به طور رایج در ابتدای بخشهای .bss و .data قرار گرفته است و به اندازههای آدرس بزرگتر قابل رشد است. ناحیهٔ هیپ توسط توابع malloc, calloc, realloc و free مدیریت میشود که ممکن است توسط سیستمهای brk و sbrk جهت تنظیم اندازه مورد استفاده قرار گیرد. ناحیه هیپ توسط تمامی نخها، کتابخانههای مشترک و ماژولهای بارگذاری شده در یک فرآیند به اشتراک گذاشته میشود. به طور کلی حافطه Heap بخشی از حافظه کامپیوتر شما است که به صورت خودکار برای شما مدیریت نمیشود، و به صورت محکم و مطمئن توسط پردازنده مرکزی مدیریت نمیشود. آن بیشتر به عنوان یک ناحیه شناور بسیار بزرگی از حافظه است. برای اختصاص دادن حافظه در ناحیه هیپ شما باید از توابع malloc(), calloc() که توابعی از C هستند استفاده کنید. یکبار که شما حافظه ای را در ناحیه هیپ اختصاص دهید، جهت آزاد سازی آن باید خود مسئول باشید و با استفاده از تابع free() این کار را به صورت دستی جهت آزاد سازی حافظه اختصاص یافته شده انجام دهید. اگر شما در این کار موفق نباشید، برنامه شما در وضعیت نَشت حافظه (Memory Leak) قرار خواهد گرفت. این بدین معنی است که حافظه اختصاص یافته شده در هیپ هنوز خارح از دسترس قرار گرفته و مورد استفاده قرار نخواهد گرفت. این وضعیت همانند گرفتگی رَگ در بدن انسان است و حافظه نشت شده جهت عملیات در دسترس نخواهد بود. خوشبختانه ابزارهایی برای کمک کردن به شما در این زمینه موجود هستند که یکی از آنها Valgrind نام دارد و شما میتوانید در زمان اشکال زدائی از آن جهت تشخیص نواحی نشت دهنده حافظه استفاده کنید. بر خلاف حافظه اِستک (Stack) حافظه هیپ محدودیتی در اندازه متغیرها ندارد (جدا از محدودیت آشکار فیزیکی در کامپیوتر شما). حافظه هیپ در خواندن کمی کُند تر از نوشتن نسبت به حافظه اِستک است، زیرا جهت دسترسی به آنها در حافظه هیپ باید از اشاره گر استفاده شود. بر خلاف حافظه اِستک، متغیرهایی که در حافظه هیپ ساخته میشوند توسط هر تابعی در هر بخشی از برنامه شما در دسترس بوده و اساسا متغیرهای تعریف شده در هیپ در دامنه سراسری قرار دارند. حافظه اِستک (Stack) ناحیهٔ اِستک (Stack) شامل برنامه اِستک، با ساختار LIFO کوتاه شده عبارت Last In First Out (آخرین ورودی از همه زودتر خارج میشود) به طور رایج در بالاترین بخش از حافظه قرار میگیرد. یک (اشاره گر پشته) در بالاترین قسمت اِستک قرار میگیرد. زمانی که تابعی فراخوانی میشود این تابع به همراه تمامی متغیرهای محلی خودش در داخل حافظه اِستک قرار میگیرد و با فراخوانی یک تابع جدید تابع جاری بر روی تابع قبلی قرار میگیرد و کار به همین صورت درباره دیگر توابع ادامه پیدا میکند. مزیت استفاده از حافظه اِستک در ذخیره متغیرها است، چرا که حافظه به صورت خودکار برای شما مدیریت میشود. شما نیازی برای اختصاص دادن حافظه به صورت دستی ندارید، یا نیازی به آزاد سازی حافظه ندارید. به طور کلی دلیل آن نیز این است که حافظه اِستک به اندازه کافی توسط پردازنده مرکزی بهینه و سازماندهی میشود. بنابراین خواندن و نوشتن در حافظه اِستک بسیار سریع است. کلید درک حافظه اِستک در این است که زمانی که تابع خارج میشود، تمامی متغیرهای موجود در آن همراه با آن خارج و به پایان زندگی خود میرسند. بنابراین متغیرهای موجود در حافظه اِستک به طور طبیعی به صورت محلی هستند. این مرتبط با مفهوم دامنه متغیرها است که قبلا از آن یاد شده است، یا همان متغیرهای محلی در مقابل متغیرهای سراسری. یک اشکال رایج در برنامه نویسی C تلاش برای دسترسی به یک متغیر که در حافظه اِستک برای یک تابع درونی ساخته شده است میباشد. یعنی از یک مکان در برنامه شما به خارج از تابع (یعنی زمانی که آن تابع خارج شده باشد) رجوع میکند. یکی دیگر از ویژگیهای حافظه اِستک که بهتر است به یاد داشته باشید این است که، محدودیت اندازه (نسبت به نوع سیستم عامل متفاوت) است. این مورد در حافظه هیپ صدق نمیکند. خلاصه ای از حافظه اِستک (Stack) حافظه اِستک متناسب با ورود و خروج توابع و متغیرهای درونی آنها افزایش و کاهش مییابد نیازی برای مدیریت دستی حافظه برای شما وجود ندارد، حافظه به طور خودکار برای متغیرها اختصاص و در زمان نیاز به صورت خودکر آزاد میشود در اِستک اندازه محدود است متغیرهای اِستک تنها در زمان اجرای تابع ساخته میشوند مزایا و معایب حافظه اِستک و هیپ حافظه اِستک (Stack) دسترسی بسیار سریع به متغیرها نیازی برای باز پس گیری حافظه اختصاص یافته شده ندارید فضا در زمان مورد نیاز به اندازه کافی توسط پردازنده مرکزی مدیریت میشود، حافظه ای نشت نخواهد کرد متغیرها فقط محلی هستند محدودیت در حافظه اِستک بسته به نوع سیستم عامل متفاوت است متغیرها نمیتوانند تغییر اندازه دهند حافظه هیپ (Heap) متغیرها به صورت سراسری قابل دسترس هستند محدودیتی در اندازه حافظه وجود ندارد تضمینی برای حافظه مصرفی وجود ندارد، ممکن است حافظه در زمانهای خاص از برنامه نشت کرده و حافظه اختصاص یافته شده برای استفاده در عملیات دیگر آزاد نخواهد شد شما باید حافظه را مدیریت کنید، شما باید مسئولیت آزاد سازی حافظه های اختصاص یافته شده به متغیرها را بر عهده بگیرید اندازه متغیرها میتواند توسط تابع realloc() تغییر یابد در اینجا یک برنامه کوتاه وجود دارد که در آن متغیرها در یک حافظه اِستک ایجاد شده اند. #include <stdio.h> double multiplyByTwo (double input) { double twice = input * 2.0; return twice; } int main (int argc, char *argv[]) { int age = 30; double salary = 12345.67; double myList[3] = {1.2, 2.3, 3.4}; printf("double your salary is %.3f\n", multiplyByTwo(salary)); return 0; } ما متغیرهایی را اعلان کردهایم که یک int، یک double و یک آرایه که سه نوع double دارد هستند. این متغیرها داخل اِستک وارد و به زودی توسط تابع main در زمان اجرا حافظه مورد نیاز خود را دریافت خواهند کرد. زمانی که تابع main خارج میشود (برنامه متوقف میشود) این متغیرها همگی از داخل حافظه اِستک خارج خواهند شد. به طور مشابه، در تابع multiplByTwo() متغیر twice که از نوع double است، داخل اِستک وارد شده و در زمان اجرای تابع multiplyByTwo() حافظه به آن اختصاص مییابد. زمانی که تابع فوق خارج شود یعنی به نقطه پایان اجرایی خود برسد، حافظه اختصاص یافته شده به متغیرهای داخلی آن نیز آزاد خواهند شد. به طور خلاصه توجه داشته باشید که تمامی متغیرهای محلی در این نوع تعریف تنها در طول زمان اجرایی زمانی تابع زنده هستند. به عنوان یک یادداشت جانبی، روشی برای نگه داری متغیرها در حافظه اِستک وجود دارد، حتی در زمانی که تابع خارج میشود. آن روش توسط کلمه کلیدی static ممکن خواهد شد که در زمان اعلان متغیر استفاده میشود. متغیری که توسط کلمه کلیدی static تعریف میشود، بنابراین چیزی مانند متغیر از نوع سراسری خواهد بود، اما تنها در داخل تابعی که داخل آن ایجاد شده است قابل مشاهده خواهد بود. این یک ساختار عجیب و غریب است، که احتمالا به جز شرایط بسیار خاص نیازی به آن نباشد. نسخهٔ دیگری از برنامه فوق در قالب حافظه هیپ به صورت زیر است: #include <stdio.h> #include <stdlib.h> double *multiplyByTwo (double *input) { double *twice = malloc(sizeof(double)); *twice = *input * 2.0; return twice; } int main (int argc, char *argv[]) { int *age = malloc(sizeof(int)); *age = 30; double *salary = malloc(sizeof(double)); *salary = 12345.67; double *myList = malloc(3 * sizeof(double)); myList[0] = 1.2; myList[1] = 2.3; myList[2] = 3.4; double *twiceSalary = multiplyByTwo(salary); printf("double your salary is %.3f\n", *twiceSalary); free(age); free(salary); free(myList); free(twiceSalary); return 0; } همانطور که میبینید، استفاده از malloc() برای تخصیص حافظه در حافظه Heap و استفاده از free() جهت آزاد سازی حافظه تخصیص یافته میباشد. این مواجه شدن چیز بسیار بزرگی محسوب نمیشود اما کمی مبهم است. چیز دیگری که باید به آن توجه داشته باشید علامت ستاره (*) است که در همه جای کدها دیده میشود. اینها چه چیزهایی هستند؟ پاسخ این سوال این است : اینها اشاره گر هستند! توابع malloc() و calloc() و free() با اشارهگرهایی مواجه میشوند که مقادیرشان واقعی نیست. اشاره گرها نوع داده ای خاصی در C هستند که آدرس حافظه مربوطه را بر میگردانند. در خط ۵ متغیر twice یک متغیر از نوع double نیست، اما اشاره به یک double دارد. آن آدرس حافظه ای است که نوع double در آن بلوک از حافظه ذخیره شده است. در ++C توسط کلمه کلیدی new که خود آن نیز یک اپراتور محسوب میشود میتوان حافظه ای را در Heap اختصاص داد. به عنوان مثال: int* myInt = new int(256); آدرسهای موجود در حافظه توسط اپراتور new به اشارهگر مربوطه پاس داده میشود. به مثال زیر توجه کنید، متغیر تعریف شده در حافظه اِستک قرار گرفته است: int variable = 256; سوالی که ممکن است افراد کنجکاو از خود بپرسند این است که چه زمانی از Stack و چه زمانی از Heap باید استفاده کنیم؟! خب پاسخ این سوال اینگونه خواهد بود، زمانی که شما نیاز به یک بلوک بسیار بزرگی از حافظه دارید، که در آن یک ساختار بزرگ یا یک ارایه بزرگی را ذخیره کنید و نیاز داشته باشید که متغیرهای شما به مدت طولانی در سرتاسر برنامه شما در دسترس باشند در این صورت از حافظه Heap استفاده کنید. در صورتی که شما نیاز به متغیرهای کوچکی دارید که تنها نیاز است در زمان اجرای تابع در دسترس باشند و قابلیت خواندن و نوشتن سریعتری داشته باشند از نوع حافظه Stack استفاده کنید. فقط فراموش نکنید که حافظه Heap تحت توابع molloc(), realloc(), calloc() و free() مدیریت میشوند. هرچند اشارهگر های هوشمند نیز در ++C وجود دارند اما در بسیاری از مواقع که نیاز است بسیار جزئی و حساس بر روی کدهای خود کار کنید از مدیریت حافظه به صورت دستی استفاده کنید.
-
سلام بر دوستان و اساتید گرامی. پایه و اساس قیمت گذاری یک برنامه C++ چگونه هست؟ با سپاس فراوان.
-
آغازی طوفانی برای پیاده سازی یک پیام رسان ساده بر پایه ++C
Max Base نوشته وبلاگ را ارسال کرد در برنامه نویسی
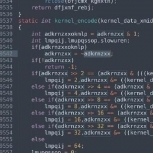
با سلام وقت بخیر, در این مطلب میخواهیم در مورد روش کارکرد پیام رسان ها بیشتر بدانیم و با یکدیگر کد یک پیام رسان ساده را پیاده و بررسی کنیم. طرز کار کرد پیام رسان در نظر داشته باشید که هر پیام رسانی که بر ساختار ها پیاده شده باشد از دو قسمت تشکیل شده است. نرم افزار اصلی برای مدیریت درخواست ها (سرور) نرم افزار برای کاربران (کاربر) به نرم افزار اولی سمت SERVER خواهیم گفت و به بعدی سمت CLIENT خواهیم گفت. روم یا تالار گفتگو ما تنها یک اتاق برای گفتگو در نظر میگیریم و هر کاربری که به سرور متصل شود را در همان تالار اضافه خواهیم کرد. تالار های گفتگو صرفا برای تقکیک سازی ارسال و دریافت ها و محدود کردن بازه ی کاربران مورد نظر... (ممکن است یک کاربر در چند اتاق بطور همزمان باشد.) سیستم های پیام رسان پیشرفته تر مانند تلگرام و ... تالار های زیادی را شامل می شوند. (هر کاربر خودش در کانال و گروه های مختلفی عضو است که هر کدام از آنها یک کانال متفاوت محسوب می شوند.) * دقت شود که منظور از کانال صرفا یک اتاق یا تالار گفتگو است و منظور کانال ارتباطی و پروتکل نیست. نرم افزار اصلی نرم افزار اصلی وظیفه دارد تا تمام کاربرانی که وارد تالار شده اند را به یاد داشته باشد و هر لحظه اماده دریافت درخواست هایی از طرف کاربرانش باشد. و پیام هایی را که از کاربران دریافت می کند برای تمامی کاربران دیگر هم ارسال کند که بسته به خلاقیت و نیاز می تواند هر یک از این بخش ها متفاوت طراحی شود. نرم افزار اصلی باید از قبل اجرا شده باشد. تا کاربران دیگر با استفاده از نرم افزار مخصوص به خودشان بتوانند به سرور متصل شوند و ارسال و دریافت داشته باشند. در نظر داشته باشید که اگر در نرم افزار اصلی اختلالی پیش بیایید و متوقف بشوند. قطا برای تمام کاربران مشکل پیش می آید. مگر اینکه از پایگاه های داده ی داخلی استفاده کرده باشند. (با خلاقیت می توان به گونه های متفاوتی چنین ساختاری را پیاده کرد) نرم افزار کاربران این نرم افزار جذاب ترین بخش است چرا تمام قابلیت هایی را که در اختیار کاربر قرار می دهیم را مستقیما طراحی می کنیم. در نظر داشته باشید که هر چیزی که در این نرم افزار طراحی می شود باید در نرم افزار اصلی پشتیبانی شوند... بنابراین اگر این دو بخش توسط دو فرد یا دو گروه مجزا طراحی می شوند آنها باید توسط داکیومنت ها و جلساتی به نظرات مشابه ای رسیده باشند. (اگرچه اینها تخصص و وظیفه ی تحلیلگر سیستم است! نه بطور همزمان وظیفه توسعه دهنده و برنامه نویس نرم افزار) پیاده سازی یک نمونه اکنون در نظر داریم تا با استفاده از ساختار کتابخانه BoostAsio پروژه ای را با نام BoostAsioChat ایجاد کنیم که در آن می خواهیم یک پیام رسان با حداقل ترین امکانات پایه طراحی کنیم که بیشتر جنبه شخصی و تفریحی دارد. زیرا از ساختار های استاندارد و ایمن و کاربری کاملا بدور است! (می توانید خودتان توسعه دهید و آنرا جالب تر بسازید) ساختار نرم افزار اصلی و سرور را به این صورت تعریف می کنیم : typedef deque<message> messageQueue; class participant { public: virtual ~participant() {} virtual void deliver(const message& messageItem) = 0; }; typedef shared_ptr<participant> participantPointer; class room { public: void join(participantPointer participant); void deliver(const message& messageItem); void leave(participantPointer participant); private: messageQueue messageRecents; enum { max = 200 }; set<participantPointer> participants; }; class session : public participant, public enable_shared_from_this<session> { public: session(tcp::socket socket, room& room) : socket(move(socket)), room_(room); void start(); void deliver(const message& messageItem); private: void readHeader(); void readBody(); void write(); tcp::socket socket; room& room_; message messageItem; messageQueue Messages; }; class server { public: server(boost::asio::io_context& io_context, const tcp::endpoint& endpoint) : acceptor(io_context, endpoint); private: void do_accept(); tcp::acceptor acceptor; room room_; }; int main(int argc, char* argv[]); ساختار نرم افزار کاربر را هم به این صورت تعریف می کنیم : typedef deque<message> messageQueue; class client { public: client(boost::asio::io_context& context, const tcp::resolver::results_type& endpoints) : context(context), socket(context); void write(const message& messageItem); void close(); private: void connect(const tcp::resolver::results_type& endpoints); void readHeader(); void readBody(); void write(); boost::asio::io_context& context; tcp::socket socket; message readMessage; messageQueue writeMessage; }; int main(int argc, char* argv[]); در نظر داریم تا در این پروژه از thread ها نیز استفاده کنیم... در مورد این مفهوم ها می توانید بصورت مجزا تحقیق کنید. بنابراین روش کامپایل این پروژه به این صورت خواهد بود : $ g++ client.cpp -lpthread -o client $ g++ Server.cpp -lpthread -o server آزمایش همانطور که گفته شد در ابتدا نرم افزار اصلی و سرور باید اجرا شود. در اینجا ما تمام ارتباطات شبکه را بر روی یک سیستم در شبکه داخلی برقرار خواهیم کرد... پس نگرانی در مورد ساختار های درونی شبکه و آی پی / دی ان اس / دامین نخواهیم داشت. بنابراین ای پی را می توانید ای پی داخلی یا localhost در نظر بگیرید. برای آزمایش پورت فرضی 4000 را در نظر میگیریم و نرم افزار اصلی را روی این پورت اجرا میکنیم : $ ./server 4000 در این مرحله متوجه می شوید که نرم افزار اصلی با موفقیت اجرا شده است و همچنان اجرا مانده است. بله درست است... نرم افزار اصلی هر لحظه باید منتظر دستور کاربران باشد. اگر لحظه ای برای نرم افزار اصلی اختلالی پیش آید نخواهد توانست دستورات کاربران را انجام یا پاسخ دهد. بنابراین این پردازش را قطع نکنید و اجازه دهید تا نرم افزار اصلی اجرا بماند. در محیط دیگری نرم افزار سمت کاربر را نیز اجرا کنید. این نرم افزار را می توانید به تعداد دلخواه وارد کنید. (همانطور که ممکن است 6 نفر همزمان به سرور متصل باشند / یا ممکن است هیچ فردی به سرور متصل نشوند) ابتدا یک کاربری را به سرور با پورت 4000 و شبکه داخلی وصل می کنیم : $ ./client localhost 4000 first user: you can type message here... حال در محیط دیگری با کاربر جدیدی نیز وارد می شویم : $ ./client localhost 4000 second user: you can type message here... در این پروژه نمونه از کاربران نام کاربری یا نام نمی پرسیم.. و صرفا وقتی وارد محیط گفتگو می شوند... یا زمانی که به سرور متصل می شوند منتظر هستیم تا انها پیامی را بنویسند... هر پیامی را که بنویسند به سرور ارسال می شود و سرور وظیفه دارد تا آنرا برای تمام کاربران بفرستد. و این روند درون یک حلقه بی نهایت تکرار می شوند. پس این ارتباط دو طرفه خواهد بود و هم کاربران برای سرور اطلاعات ارسال می کنند و هم سرور برای کاربران اطلاعات ارسال خواهد کرد. در نظر داشته باشید که کاربر اول می تواند پیامی را بنویسد و به کاربران دیگر ارسال شود. ممکن است کاربر سومی اصلا تصمیمی به نوشتن پیام نداشته باشد و صرفا تمایل به خواندن پیام دیگران داشته باشند. و این کاملا اختیاری است. و ما کاربران را اجباری نمیکنیم. اگرچه شما می توانید با خلاقیت خودتان اینها را با متغییر های کمکی و دستورات شرطی پیاده کنید. کد ها برای پیام ها یک ساختار در نظر میگیریم و بصورت مشترک در هر دو نرم افزار استفاده خواهیم کرد... بنابراین اینرا در هدر پیاده خواهیم کرد. هدر پیام : (message.hpp) #ifndef message_HPP #define message_HPP #include <cstdio> #include <cstdlib> #include <cstring> using namespace std; class message { public: enum { headerLength = 4 }; enum { maxBodyLength = 512 }; message() : bodyLength_(0) { } const char* data() const { return data_; } char* data() { return data_; } size_t length() const { return headerLength + bodyLength_; } const char* body() const { return data_ + headerLength; } char* body() { return data_ + headerLength; } size_t bodyLength() const { return bodyLength_; } void bodyLength(size_t new_length) { bodyLength_ = new_length; if(bodyLength_ > maxBodyLength) bodyLength_ = maxBodyLength; } bool decodeHeader() { char header[headerLength + 1] = ""; strncat(header, data_, headerLength); bodyLength_ = atoi(header); if(bodyLength_ > maxBodyLength) { bodyLength_ = 0; return false; } return true; } void encodeHeader() { char header[headerLength + 1] = ""; sprintf(header, "%4d", static_cast<int>(bodyLength_)); memcpy(data_, header, headerLength); } private: char data_[headerLength + maxBodyLength]; size_t bodyLength_; }; #endif نرم افزار اصلی و سرور : (server.cpp) #include <iostream> #include <cstdlib> #include <deque> #include <memory> #include <list> #include <set> #include <utility> #include <boost/asio.hpp> #include "message.hpp" using boost::asio::ip::tcp; using namespace std; typedef deque<message> messageQueue; class participant { public: virtual ~participant() {} virtual void deliver(const message& messageItem) = 0; }; typedef shared_ptr<participant> participantPointer; class room { public: void join(participantPointer participant) { participants.insert(participant); for(auto messageItem: messageRecents) participant->deliver(messageItem); } void deliver(const message& messageItem) { messageRecents.push_back(messageItem); while(messageRecents.size() > max) messageRecents.pop_front(); for(auto participant: participants) participant->deliver(messageItem); } void leave(participantPointer participant) { participants.erase(participant); } private: messageQueue messageRecents; enum { max = 200 }; set<participantPointer> participants; }; class session : public participant, public enable_shared_from_this<session> { public: session(tcp::socket socket, room& room) : socket(move(socket)), room_(room) { } void start() { room_.join(shared_from_this()); readHeader(); } void deliver(const message& messageItem) { bool write_in_progress = !Messages.empty(); Messages.push_back(messageItem); if(!write_in_progress) { write(); } } private: void readHeader() { auto self(shared_from_this()); boost::asio::async_read(socket, boost::asio::buffer(messageItem.data(), message::headerLength), [this, self](boost::system::error_code ec, size_t) { if(!ec && messageItem.decodeHeader()) { readBody(); } else { room_.leave(shared_from_this()); } }); } void readBody() { auto self(shared_from_this()); boost::asio::async_read(socket, boost::asio::buffer(messageItem.body(), messageItem.bodyLength()), [this, self](boost::system::error_code ec, size_t) { if(!ec) { room_.deliver(messageItem); readHeader(); } else { room_.leave(shared_from_this()); } }); } void write() { auto self(shared_from_this()); boost::asio::async_write(socket, boost::asio::buffer(Messages.front().data(), Messages.front().length()), [this, self](boost::system::error_code ec, size_t) { if(!ec) { Messages.pop_front(); if(!Messages.empty()) { write(); } } else { room_.leave(shared_from_this()); } }); } tcp::socket socket; room& room_; message messageItem; messageQueue Messages; }; class server { public: server(boost::asio::io_context& io_context, const tcp::endpoint& endpoint) : acceptor(io_context, endpoint) { do_accept(); } private: void do_accept() { acceptor.async_accept([this](boost::system::error_code ec, tcp::socket socket) { if(!ec) { make_shared<session>(move(socket), room_)->start(); } do_accept(); }); } tcp::acceptor acceptor; room room_; }; int main(int argc, char* argv[]) { try { if(argc < 2) { cerr << "Usage: server <port> [<port> ...]\n"; return 1; } boost::asio::io_context io_context; list<server> servers; for(int i = 1; i < argc; ++i) { tcp::endpoint endpoint(tcp::v4(), atoi(argv[i])); servers.emplace_back(io_context, endpoint); } io_context.run(); } catch (exception& e) { cerr << "Exception: " << e.what() << "\n"; } return 0; } نرم افزار دوم و سمت کاربر : (client.cpp) #include <iostream> #include <thread> #include <cstdlib> #include <deque> #include <boost/asio.hpp> #include "message.hpp" using boost::asio::ip::tcp; using namespace std; typedef deque<message> messageQueue; class client { public: client(boost::asio::io_context& context, const tcp::resolver::results_type& endpoints) : context(context), socket(context) { connect(endpoints); } void write(const message& messageItem) { boost::asio::post(context, [this, messageItem]() { bool write_in_progress = !writeMessage.empty(); writeMessage.push_back(messageItem); if(!write_in_progress) { write(); } }); } void close() { boost::asio::post(context, [this]() { socket.close(); }); } private: void connect(const tcp::resolver::results_type& endpoints) { boost::asio::async_connect(socket, endpoints, [this](boost::system::error_code ec, tcp::endpoint) { if(!ec) { readHeader(); } }); } void readHeader() { boost::asio::async_read(socket, boost::asio::buffer(readMessage.data(), message::headerLength), [this](boost::system::error_code ec, size_t) { if(!ec && readMessage.decodeHeader()) { readBody(); } else { socket.close(); } }); } void readBody() { boost::asio::async_read(socket, boost::asio::buffer(readMessage.body(), readMessage.bodyLength()), [this](boost::system::error_code ec, size_t) { if(!ec) { cout.write(readMessage.body(), readMessage.bodyLength()); cout << "\n"; readHeader(); } else { socket.close(); } }); } void write() { boost::asio::async_write(socket, boost::asio::buffer(writeMessage.front().data(), writeMessage.front().length()), [this](boost::system::error_code ec, size_t) { if(!ec) { writeMessage.pop_front(); if(!writeMessage.empty()) { write(); } } else { socket.close(); } }); } boost::asio::io_context& context; tcp::socket socket; message readMessage; messageQueue writeMessage; }; int main(int argc, char* argv[]) { try { if(argc != 3) { cerr << "Usage: client <host> <port>\n"; return 1; } boost::asio::io_context context; tcp::resolver resolver(context); auto endpoints = resolver.resolve(argv[1], argv[2]); client c(context, endpoints); thread t([&context](){ context.run(); }); char line[message::maxBodyLength + 1]; while(cin.getline(line, message::maxBodyLength + 1)) { message messageItem; messageItem.bodyLength(strlen(line)); memcpy(messageItem.body(), line, messageItem.bodyLength()); messageItem.encodeHeader(); c.write(messageItem); } c.close(); t.join(); } catch (exception& e) { cerr << "Exception: " << e.what() << "\n"; } return 0; } این پروژه آزمایشی بصورت رایگان و اوپن سورس در اینترنت بخصوص اینجا وجود دارد و می توانید آنرا مستقیما بصورت کامل دانلود کنید. با تشکر, Max Base / مکس بیس -
 به نام خدا در این مطلب قصد داریم تا طریقه پیکربندی پایگاه داده MySQL را با استفاده از کامپایلر مایکروسافت بر روی سیستم عامل ویندوز، بررسی نماییم. در ابتدا میبایست پایگاه داده MySQL را بر روی سیستم خود نصب نماییم. بدین منظور به آدرس این آدرس رفته و سپس و نصاب آنلاین یا آفلاین آن را دریافت و بر روی سیستم خود نصب مینماییم. حال لازم است تا مسیر qmake مربوط به کیت مورد نظر واقع در محل نصب کتابخانه کیوت به متغیر محیطی Path سیستم عامل معرفی شود. در اینجا قصد داریم تا از MSVC 2017 64 bit استفاده کنیم که بر روی سیستم عامل 64 بیتی اجرا شده و خروجی دودویی برای سیستم عامل 64 بیتی تولید میکند. مطابق شکل زیر مسیر qmake مورد نظر را به Path سیستم عامل اضافه میکنیم: پس از این کار از منوی Start پوشه Visual Studio 2017 را انتخاب کرده و سپس x64 Native Tools Command Prompt for VS 2017 را انتخاب کرده تا کنسول باز شود. حال میبایست به آدرس محل درایور پایگاه داده کیوت برویم. بدین منظور دستور زیر را در کنسول وارد میکنیم: C:\Program Files (x86)\Microsoft Visual Studio\2017\BuildTools>F: F:\>cd F:\Softwares\Qt\5.13.1\Src\qtbase\src\plugins\sqldrivers دستور اول به منظور تغییر درایو از C به F وارد شده و دستور دوم آدرس محل نصب کیوت روی سیستم نگارنده مطلب میباشد. حال دستور زیر را وارد میکنیم: qmake -- MYSQL_INCDIR="C:\Program Files\MySQL\MySQL Server 8.0\include" MYSQL_LIBDIR="C:\Program Files\MySQL\MySQL Server 8.0\lib" فراخوانی دستور qmake سبب ایجاد یک makefile شده که بعدا برای کامپایل درایور MySQL استفاده میشود. آدرسهای بالا نیز محل نصب پایگاه داده MySQL در حالت پیشفرض را نشان میدهد. پس از اتمام عملیات نتیجه زیر میبایست حاصل شود: ملاحظه میشود که در مقابل MySql کلمه yes نوشته شده که این به معنی موفقیت آمیز بودن یافتن درایور MySQL میباشد. در نهایت با دستور زیر عملیات کامپایل آغاز میشود: nmake sub-mysql پس از اتمام این مرحله نیز در پایان دستور زیر را اجرا کرده تا فایلهای کامپایل شده، نصب شوند: nmake install محل نصب این فایلهای راه انداز درایور در مسیر زیر میباشد: F:\Softwares\Qt\5.13.1\Src\qtbase\src\plugins\sqldrivers\plugins\sqldrivers در مسیر بالا دو فایل به نامهای qsqlmysql.dll و qsqlmysqld.dll وجود دارد که باید در کنار فایل اجرایی برنامه کامپایل شده قرار گیرد تا برنامه به درستی اجرا شود. همچنین در مسیر: C:\Program Files\MySQL\MySQL Server 8.0\lib فایل libmysql.dll وجود دارد که میبایست در مسیر فایل اجرایی برنامه قرار گیرد. در پایان نوبت به این رسیده تا با ایجاد یک پروژه آزمایشی در Qt Creator بررسی کنیم تا همه چیز به درستی پیکربندی شده باشد. قبل از آن میبایست یک پایگاه داده آزمایشی در MySQL ایجاد کرده و سپس با استفاده از کتابخانه کیوت به آن متصل شویم. ابتدا خط فرمان MySQL را باز کرده و دستور زیر را وارد میکنیم: CREATE DATABASE mydatabase; که mydatabase نام پایگاه داده ایجاد شده میباشد. حال پس از ایجاد یک پروژه ساده در Qt Creator محتویات فایل .pro را مطابق شکل زیر وارد میکنیم: QT += core sql TEMPLATE = app CONFIG += console c++11 CONFIG -= app_bundle SOURCES += \ main.cpp و در فایل main.cpp خواهیم داشت: #include <iostream> #include <QtSql/QSqlDatabase> #include <QtSql/QSqlError> #include <QDebug> using namespace std; int main() { QSqlDatabase db {QSqlDatabase::addDatabase ("QMYSQL")}; db.setHostName ("localhost"); db.setDatabaseName("mydatabase"); db.setUserName ("root"); db.setPassword ("123456789"); if(db.open ()) { qDebug() << "Success!"; } else { qDebug() << db.lastError ().text (); } } با ساخت و اجرا پروژه باید پیام Success! در خروجی نمایش داده شود. این یعنی پایگاه داده MySQL با موفقیت نصب و پیکربندی شده است.
به نام خدا در این مطلب قصد داریم تا طریقه پیکربندی پایگاه داده MySQL را با استفاده از کامپایلر مایکروسافت بر روی سیستم عامل ویندوز، بررسی نماییم. در ابتدا میبایست پایگاه داده MySQL را بر روی سیستم خود نصب نماییم. بدین منظور به آدرس این آدرس رفته و سپس و نصاب آنلاین یا آفلاین آن را دریافت و بر روی سیستم خود نصب مینماییم. حال لازم است تا مسیر qmake مربوط به کیت مورد نظر واقع در محل نصب کتابخانه کیوت به متغیر محیطی Path سیستم عامل معرفی شود. در اینجا قصد داریم تا از MSVC 2017 64 bit استفاده کنیم که بر روی سیستم عامل 64 بیتی اجرا شده و خروجی دودویی برای سیستم عامل 64 بیتی تولید میکند. مطابق شکل زیر مسیر qmake مورد نظر را به Path سیستم عامل اضافه میکنیم: پس از این کار از منوی Start پوشه Visual Studio 2017 را انتخاب کرده و سپس x64 Native Tools Command Prompt for VS 2017 را انتخاب کرده تا کنسول باز شود. حال میبایست به آدرس محل درایور پایگاه داده کیوت برویم. بدین منظور دستور زیر را در کنسول وارد میکنیم: C:\Program Files (x86)\Microsoft Visual Studio\2017\BuildTools>F: F:\>cd F:\Softwares\Qt\5.13.1\Src\qtbase\src\plugins\sqldrivers دستور اول به منظور تغییر درایو از C به F وارد شده و دستور دوم آدرس محل نصب کیوت روی سیستم نگارنده مطلب میباشد. حال دستور زیر را وارد میکنیم: qmake -- MYSQL_INCDIR="C:\Program Files\MySQL\MySQL Server 8.0\include" MYSQL_LIBDIR="C:\Program Files\MySQL\MySQL Server 8.0\lib" فراخوانی دستور qmake سبب ایجاد یک makefile شده که بعدا برای کامپایل درایور MySQL استفاده میشود. آدرسهای بالا نیز محل نصب پایگاه داده MySQL در حالت پیشفرض را نشان میدهد. پس از اتمام عملیات نتیجه زیر میبایست حاصل شود: ملاحظه میشود که در مقابل MySql کلمه yes نوشته شده که این به معنی موفقیت آمیز بودن یافتن درایور MySQL میباشد. در نهایت با دستور زیر عملیات کامپایل آغاز میشود: nmake sub-mysql پس از اتمام این مرحله نیز در پایان دستور زیر را اجرا کرده تا فایلهای کامپایل شده، نصب شوند: nmake install محل نصب این فایلهای راه انداز درایور در مسیر زیر میباشد: F:\Softwares\Qt\5.13.1\Src\qtbase\src\plugins\sqldrivers\plugins\sqldrivers در مسیر بالا دو فایل به نامهای qsqlmysql.dll و qsqlmysqld.dll وجود دارد که باید در کنار فایل اجرایی برنامه کامپایل شده قرار گیرد تا برنامه به درستی اجرا شود. همچنین در مسیر: C:\Program Files\MySQL\MySQL Server 8.0\lib فایل libmysql.dll وجود دارد که میبایست در مسیر فایل اجرایی برنامه قرار گیرد. در پایان نوبت به این رسیده تا با ایجاد یک پروژه آزمایشی در Qt Creator بررسی کنیم تا همه چیز به درستی پیکربندی شده باشد. قبل از آن میبایست یک پایگاه داده آزمایشی در MySQL ایجاد کرده و سپس با استفاده از کتابخانه کیوت به آن متصل شویم. ابتدا خط فرمان MySQL را باز کرده و دستور زیر را وارد میکنیم: CREATE DATABASE mydatabase; که mydatabase نام پایگاه داده ایجاد شده میباشد. حال پس از ایجاد یک پروژه ساده در Qt Creator محتویات فایل .pro را مطابق شکل زیر وارد میکنیم: QT += core sql TEMPLATE = app CONFIG += console c++11 CONFIG -= app_bundle SOURCES += \ main.cpp و در فایل main.cpp خواهیم داشت: #include <iostream> #include <QtSql/QSqlDatabase> #include <QtSql/QSqlError> #include <QDebug> using namespace std; int main() { QSqlDatabase db {QSqlDatabase::addDatabase ("QMYSQL")}; db.setHostName ("localhost"); db.setDatabaseName("mydatabase"); db.setUserName ("root"); db.setPassword ("123456789"); if(db.open ()) { qDebug() << "Success!"; } else { qDebug() << db.lastError ().text (); } } با ساخت و اجرا پروژه باید پیام Success! در خروجی نمایش داده شود. این یعنی پایگاه داده MySQL با موفقیت نصب و پیکربندی شده است. -
وباسمبلی (WebAssembly) یا wasm یک فناوری برنامهنویسی سطحپایین برای استفاده در مرورگر است. هدف اولیهی آن پشتیبانی از کامپایل کدها به سی و سی++ است هرچند که قرار است از سایر زبانها نیز حمایت شود. حال کتابخانهی Qt این امکان را تحت ماژول Qt WebAssembly فراهم میکند تا برنامهی نوشته شده توسط سی++ و کیوت در محیط مرورگر قابل اجرا باشند. این ویژگی در حال حاضر به عنوان پیشنمایش برای نسخهی Qt 5.11 برنامهریزی شده است. کیوت برای ساخت وب اسمبلی دستورالعملهایی را در اینجا آورده است. قبل از هرچیز شما نیاز دارید تا ابزار کامپایلر emsdk را آماده و نصب نمایید. بنابراین دستورات زیر را به ترتیب اجرا کنید. # Get the emsdk repo git clone https://github.com/juj/emsdk.git # Enter that directory cd emsdk # Fetch the latest registry of available tools. ./emsdk update # Download and install the latest SDK tools. ./emsdk install latest # Make the "latest" SDK "active" for the current user. (writes ~/.emscripten file) ./emsdk activate latest # Activate PATH and other environment variables in the current terminal source ./emsdk_env.sh در صورتی که در پیکربندی نیاز به راهنمایی دارید از راهنمای اصلی آن استفاده کنید و یا در همین مرجع در تالارهای گفتمان از ما بپرسید. ما به این ابزار به عنوان ابزار کامپایل-چندمنظوره استفاده خواهیم کرد. برخی از اسکرین شاتها از نتایج خروجی این ماژول به صورت زیر آمدهاند: یک بازی ساده به نام Colliding mice ویژگی پنجرههای گفتگو به نظر میرسد پنجرههای ساخته شده توسط QOpenGLWindow با فریم ریت ۶۰ به خوبی عمل میکنند. البته به نظر میرسد QOpenGLWidget فعلاً شامل برخی از مشکلات است که حل خواهند شد. کامپایلر Emscripten که به عنوان یک کامپایلر منبعباز که بک اند آن بر روی LLVM اجرا میشود کُدهای OpenGL را به WebGL ترجمه میکند. بنابراین محدودیتهایی در نسخههای دسکتاپ و اِمبدها وجود خواهد داشت. نمونه مثال پنجره تحت OpenGL در کنار اینها QtBases و QtDeclarative که از شاخهی Wip/Web Assembly استقاده میکنند، ماژولهای شناخته شدهی کیوت به صورت زیر به کار گرفته میشوند: QtCharts QtGraphicalEffects QtQuickControls QtQuickControls2 QtWebSockets QtMqtt (با استفاده از وب سوکت) برای استفاده از QtMqtt، شما باید کلاس WebSocketIODevice از نمونه مثالی با نام (websocketsubscription) وارد برنامهی خود کنید. نمونه مثالهای ساعت در QML نکته: از آنجا که جاوااسکریپت و وباسمبلی تنها یک نخ (Thread) دارند، QtDeclarative تنها برای یک نَخ (ترد) کار خواهد کرد. در نظر داشته باشید که ماژولهای QtCharts QtGraphicalEffects، QtQuickcontrols، QtQuickControls2 بدون هیچ تغییراتی کار میکنند. ماژول QtChart از نمونه مثال oscilloscope این پروژه به عنوان یک رویکرد جدید و ویژگیای که در آینده میتواند مفید باشد در حال توسعه است. بخش ویکی رسمی آن در این لینک آورده شده است.
-
سلام.خسته نباشید. من می خوام از کتابخانه ی nakama در qml استفاده کنم.این کتابخانه به زبان cpp است.برای توابعش می تونم سیگنال و اسلات بنویسم و در qml فراخوانی کنم. ولی data type های سفارشی اون رو نمی دونم چطور در qml ایجاد کنم.مثلا در کد زیر (cpp): NClientParameters parameters; parameters.serverKey = "defaultkey"; parameters.host = "127.0.0.1"; parameters.port = DEFAULT_PORT; NClientPtr client = createDefaultClient(parameters); می خوام NClientParameters در qml قابل دسترسی باشه و بتونم هاست و پورت رو داخل qml تنظیم کنم(مثل بالا). بعد هم به عنوان پارامتر برای تابعم استفاده کنم. لینک کتابخانه cpp: https://heroiclabs.com/docs/cpp-client-guide/#usage
-
اولین پلتفرم آموزشی چند منظورهٔ بومی اگر شما به دنبال فراگیری مهارت خاصی در زندگی خود هستید، فانوکس بستر مناسبی برای شما است؛ نام فانوکس الهام گرفته از فانوس دریایی است که نماد پیدا کردن مسیر و نور راهنما تا رسیدن به مقصد میباشد. هدف : آموزش و یادگیری هوشمند در هر زمان و هر جا برای بهبود زندگی و کسب و کار این تاپیک برای این منظور ایجاد شده است که پروژه معرفی و بازخوردهای آن در این بخش اعلام و اصلاح شوند. بنابراین تمامی دوستان و علاقهمندانی که بازخوردهایی برای آن دارند میتوانند در این بخش آن را اعلام کنند تا به کمک هم آن را اصلاح و توسعه دهیم. نکته: نسخهٔ ریلیز شده ویژگی ثبت خطاها را دارد که به شما اجازه میدهد کد و پیغام خطا را کپی و در اختیار ما قرار دهید. بنابراین شرط جاری روی مُد User و فلگهای Info، Warning، Failed و Critical نیز تنظیم شدهاند که میتوانید در صورت مشاهده آنها را تقسیم بندی کنید. if(DeveloperMode::IsEnable) { Logger::LoggerModel = Logger::Mode::User; Log("Log Message : " + Event , LoggerType::Info); Log("Log Message : " + Event , LoggerType::Warning); Log("Log Message : " + Event , LoggerType::Failed); Log("Log Message : " + Event , LoggerType::Critical); } پیش اطلاعات فنی انجین : سِل Cell رابط کاربری: JavaScript، QML و فناوری Qt Quick کتابخانهها : STL, OpenSSL, Curl و Qt سمت سرور: Php7.2 و MySQLi MariaDB (در آینده همین بخش رو هم احتمالاً با ++C توسعه بدم). رابطهای برنامهنویسی: Restful Api v.1.0 در قالب JSon نسخهٔ فعلی: ۰.۵ آلفا پلتفرمهای پشتیبانی دسکتاپ : Windows, macOS, Linux پلتفرمهای پشتیبانی موبایل و تبلت : iOS, Android, iPadOS معرفی در آیاواستریم نسخهٔ فعلی توسعه یافته : ۰.۵.۳۴۳.۰ ریلیز شده در سه حالت Normal, OpenGLEs و Software Mode هدف از این روش ریلیز این هست که سیستمهایی که دارای کارت گرافیکی ضعیفتر و یا بدون نصب کارت گرافیک و درایور آن هستند را تحت پوشش دهیم، بنابراین نسخهٔ Software Mode تنها مناسب برای سیستمهای اداری و مشابه آن هستند که عموماً خبری از کارت گرافیکی و یا درایورهای نصب شده بر روی آنها نیست ? دوستان توجه داشته باشند که برای بازخوردها و اعلام نظرات توسعه حتماً از مُد اجرای برنامهٔ خودشون و نوع سیستمعامل و شرایط سختافزاریشون مطلع باشند تا بتونیم به درستی مشکلات احتمالی را حل کنیم. در ادامه بعد از نظر نسخهٔ آلفا شروع به بررسی و حل مشکلات احتمالی در مسیر توسعه خواهیم کرد.
-
درود و خستهنباشید به دوستان؛ درحال طراحی یک رابطکابریساده بودهام که خواستم قسمت رنگآمیزی Itemها و Fontها و ... به راحتی قابل تغییر و برنامهریزی باشد. اینکار را با استفاده از یک فایل QML جدا به اسم Style.qml به شکل زیر انجام دادم : pragma Singleton import QtQuick 2.13 Item { property int textinputTextSize : 22 property color transparent : "transparent" property color bluredColor : "#5AAFAAAA" property int tabBarWidth : 50 property int tabBarHeight : 75 property int tabBarIconSize : 44 property int tabBarTextSize : 20 property color tabBarIconColor: "#81D8DE" property color tabBarTextColor: "#059EAB" property color tabBarBackColor: "#0571AB" property alias sahelRegular : sahel_font.name property alias fontAwesome : font_awesome.name FontLoader{ id: sahel_font source: "qrc:/assets/fonts/sahel/Sahel-FD-WOL.ttf" } FontLoader{ id: font_awesome source: "qrc:/assets/fonts/awesome/fontawesome-regular.ttf" } property color mainpageColor : "#E3F2FD" property color mainpageToolbarColor : bluredColor } آیا این روش بهینه و درست است ؟ و یا راه بهتری هم وجود دارد ؟
-
سلام به همه دوستان. یک کلاس سی داریم که ارتباط سریال رو انجام میده و من با این کد qmlRegisterType<serialPort>("io.qt.Serial.SerialPort", 1, 0, "SerialPort"); کلاس سی رو نمونه سازی کردم در qml. مشکل اینجاست که چطور زمانی که در سی و توسط پورت سریال اطلاعاتی رو دریافت کردم textarea در qml مقادیر رو نمایش بده. کد دریافت از سریال در کلاس سی ++ QString serialPort::getData() { QByteArray serialData; QString serialBuffer = ""; serialData = _serialport->readAll(); serialBuffer = QString::fromStdString(serialData.toStdString()); qDebug() << serialBuffer; return serialBuffer; } textarea in qml Rectangle { id:containerTextArea width: parent.width anchors.top: container.bottom anchors.bottom: btnClearTextCommunication.top color: "#e0e0eb" TextArea { id:txtCommunication anchors.fill: parent; readOnly: true } } نمونه سازیم کلاس سی++ SerialPort { id:serialport }
-
با سلام و خسته نباشید چطوری میتوان دیتابیس موجود در شبکه اینترنت را خواند ودر کلاینت نشان داد دوستان اگه کسی اطلاعاتی در این مورد داره راهنمایی کنه
-
سلام ... تو فعال سازی اسپلش واسه اندروید به مشکل خوردم . البته کلی لینک رو هم گشتم و همه یه روش رو میگن که جواب هم نمیده. میگن باید تو فایل AndroidManifest.xml از قسمت اسپلش این کار و کنیم . کاشف به عمل اومده قبلا تو سایت یه پست بوده واسه اسپلش و نسخه ی جدید پاک شده . اگه مقدور هست اضافه بشه . ممنون ...
-
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #2cdb89; color: #000000;" >کتابخانه کیوت (Qt)</span>
همانطور که میدانید محیط توسعهی یکپارچهی نرمافزار Visual Studio به عنوان یکی از جامعترین محیطهای توسعه بسیار شناخته شده است. برنامهنویسان سیپلاسپلاس بسیاری از پروژههای خود را تحت این محیط علاوه بر آن کیوت کریتور توسعه میدهند. کتابخانهی کیوت افزونهای را برای یکپارچه سازی خود با محیط ویژوال استودیو ارائه داده است که در حالت عادی از کتابخانهی Qt به خوبی پشتیبانی میکند و اجازه میدهد تا شما کُدهای خود را که بر اساس کتابخانهی کیوت هستند در محیط ویژوال استودیو توسعه و خروجی بگیرید. اما محدودیتهایی در این افزونه تا به امروز وجود دارد، یکی از آنها عدم هماهنگی و پشتیبانی از زبان QML بر پایه جاوا اسکریپت است. در نسخهی بعدی کیوت یعنی 5.12.0 افزونهی Qt Visual Studio Tools, v2.3.0 نیز منتشر خواهد شد که با نسخههای جدید ویژوال استودیو هماهنگ و به شما امکان اینم را خواهد داد تا بتوانید کدهای نوشته شده توسط QML و JavaScript را اشکالزدایی کنید. این امکان وجود خواهد داشت تا شما هر جایی که نقطهی توقف برای اشکال زدایی ایجاد کرده اید را مورد تجزیه تحلیل قرار خواهید داد. از جمله، تغییر تحولات در ارزشهای متغیرها و دیگر موارد. نسخهی جدید این افزونه به طور کامل با زیرساخت اشکال زدایی QML یکپارچه سازی شده است. که به عنوان بخشی از ماژول Qt QML خدماتی برای اشکال زدایی، بررسی و ثبت و ظبط برنامه را از طریق یک پور TCP فراهم میکند. به صورت پیشفرض ویژگی اشکال زدایی در QML برای ویژوال استودیو فعال است. شما میتوانید آن را در بخش تنظیمات افزونه ویژوال استودیو برای Qt غیرفعال کنید. این ابزار را میتوانید از این بخش دریافت کنید. -
همانطور که میدانید یکی از مباحث شاید به ظاهر پیچیده در کیوت برقراری ارتباط بین سیپلاسپلاس و کیواماِل باشد. در این پست من تصمیم گرفتم مثالی را در قالب لیست تماسها ایجاد کنم که شاید بعدها توسعه آن ادامه داشته باشد. فرض کنید قرار است لیستی از تماسها یا کاربران را دریافت و در بخش رابط کاربری خود در قالب یک لیست نمایش دهیم. قبل از هرچیز باید بدانید که برای چنین کاری کلاسی را در سمت بکاِند ایجاد کنید. نام این کلاس را در این مثال ContactList گذاشتهایم. فایل هدر مرتبط با کلاس تماسها به صورت زیر است: // // File : contactlist.h // Class or Function (ContactList) // // Created by Kambiz Asadzadeh on 2018/7/19. // Copyright © 2018 Kambiz Asadzadeh. All rights reserved. // Official Website : http://kambizasadzadeh.com // Powered by : Dotwaves LLC (http://dotwaves.com) // #ifndef CONTACTLIST_H #define CONTACTLIST_H #include <QObject> //Namespace Contact namespace Contact { class ContactList; class ContactList : public QObject { Q_OBJECT Q_PROPERTY ( QString name READ name WRITE setName NOTIFY nameChanged ) Q_PROPERTY ( QString family READ family WRITE setFamily NOTIFY familyChanged ) Q_PROPERTY ( QString phone READ phone WRITE setPhone NOTIFY phoneChanged ) Q_PROPERTY ( QString device READ device WRITE setDevice NOTIFY deviceChanged ) Q_PROPERTY ( QString avatar READ avatar WRITE setAvatar NOTIFY avatarChanged ) Q_PROPERTY ( QString color READ color WRITE setColor NOTIFY colorChanged ) Q_PROPERTY ( QString url READ url WRITE setUrl NOTIFY urlChanged ) public: ContactList(QObject *parent=0); ContactList( const QString &name, const QString &family, const QString &phone, const QString &device, const QString &avatar, const QString &color, const QString &url, QObject *parent=0 ); ~ContactList(); QString name () const; QString family () const; QString phone () const; QString device () const; QString url () const; void setName (const QString &name); void setFamily (const QString &family); void setPhone (const QString &phone); void setDevice (const QString &device); void setUrl (const QString &url); //Avatar of user QString avatar () const; void setAvatar (const QString &image); //Color of user QString color () const; void setColor (const QString &color); signals: void nameChanged (); void familyChanged (); void phoneChanged (); void deviceChanged (); void avatarChanged (); void colorChanged (); void urlChanged (); private: QString m_name; QString m_family; QString m_phone; QString m_device; QString m_avatar; QString m_color; QString m_url; }; } #endif // CONTACTLIST_H قبل از هر چیز دقت کنید که برای استفاده و دسترسی به تمامی آبجکتهای موجود در کیوت نیاز به کلاس QObject خواهیم داشت. بنابراین فایل هدر آن را در فایل خود افزودهایم. فضای نام Contact سپس اعلان کلاس مشتق شده از کلاس QObject مشخص کرده و سپس برای فعال سازی امکان استفاده از سرویس متا آبجکت (به عنوان یک مکانیزم) برای دسترسی به سیگنالها و اسلاتها در کیوت از ماکروی Q_OBJECT استفاد میکنیم. شکل کلی ماکروی Q_PROPERTY Q_PROPERTY(type name (READ getFunction [WRITE setFunction] | MEMBER memberName [(READ getFunction | WRITE setFunction)]) [RESET resetFunction] [NOTIFY notifySignal] [REVISION int] [DESIGNABLE bool] [SCRIPTABLE bool] [STORED bool] [USER bool] [CONSTANT] [FINAL]) ماکروی Q_PROPERTY جهت اعلان ویژگیهای موجود در اشیاء کلاس به کار گرفته شده است که از کلاس QObject ارث بری میکند. در نظر داشته باشید که این ویژگیهای موجود در اصل همانند اعضای موجود در کلاسها رفتار میکنند، با این تفاوت که در اینجا امکانات و ویژگیهای اضافی بر اساس مکانیزم سیستم متا آبجکت کیوت را ارائه میدهند. ویژگیهای نام، نوع و تابع READ ضروری هستند. نوع میتواند هر نوعی را توسط QVariant پشتیبانی کند، یا توسط کاربر نوع مورد نیاز تعریف شود. آیتمهای دیگر اختیاری هستند، اما یک تابع WRITE رایج است. صفاتهای دیگر به صورت پیشفرض به جز USER که به صورت پیشفرض false است همگی true میباشند. برای مثال Q_PROPERTY(QString title READ title WRITE setTitle USER true) بر اساس همین روش ما پارامترهای کلاس را اعلان و در نهایت توابع، سیگنالها و اعضای خصوصی کلاس را بر اساس نیاز اعلان کردهایم. تعریف کلاس و توابع آن در ادامه به صورت زیر آمده است: // // File : contactlist.cpp // Class or Function (ContactList) // // Created by Kambiz Asadzadeh on 2018/7/19. // Copyright © 2018 Kambiz Asadzadeh. All rights reserved. // Official Website : http://kambizasadzadeh.com // Powered by : Dotwaves LLC (http://dotwaves.com) // #include "contactlist.h" using namespace Contact; ContactList::ContactList(QObject *parent) : QObject(parent) { } ContactList::ContactList( const QString &name, const QString &family, const QString &phone, const QString &device, const QString &avatar, const QString &color, const QString &url, QObject *parent ) : QObject(parent), m_name (name), m_family (family), m_phone (phone), m_device (device), m_avatar (avatar), m_color (color), m_url (url) { } ContactList::~ContactList() {} QString ContactList::name() const { return m_name; } void ContactList::setName(const QString &name) { if (name != m_name) { m_name = name; emit nameChanged(); } } QString ContactList::family() const { return m_family; } void ContactList::setFamily(const QString &family) { if (family != m_family) { m_family = family; emit familyChanged(); } } QString ContactList::phone() const { return m_phone; } void ContactList::setPhone(const QString &phone) { if (phone != m_phone) { m_phone = phone; emit phoneChanged(); } } QString ContactList::device() const { return m_device; } void ContactList::setDevice(const QString &device) { if (device != m_device) { m_device = device; emit deviceChanged(); } } QString ContactList::avatar() const { return m_avatar; } void ContactList::setAvatar(const QString &avatar) { if (avatar != m_avatar) { m_avatar = avatar; emit avatarChanged(); } } QString ContactList::color() const { return m_color; } void ContactList::setColor(const QString &color) { if (color != m_color) { m_color = color; emit colorChanged(); } } QString ContactList::url() const { return m_url; } void ContactList::setUrl(const QString &url) { if (url != m_url) { m_url = url; emit urlChanged(); } } توجه داشته باشید که هر یک از توابع مقادیر ورودی را در قالب پارامترهای ثابت دریافت و در صورتی که اعضای موجود در کلاس مقداری نداشته باشند برابر با پارامتر ورودی خواهند بود. سپس در صورتی که مقدار آنها تغییر یافت وضعیت تغییر آنها توسط emit به عنوان یک پیشپردازندهٔ از قبل تعریف شده کیوت انتشار (ساطع) خواهد شد. بعد از اعلان و تعریف کلاس مربوطه در فایل main.cpp لیستی را به عنوان دادههای ارسالی ایجاد میکنیم که به صورت زیر آمده است: #include <QGuiApplication> #include <QQmlApplicationEngine> #include <QQmlContext> #include "contactlist.h" using namespace Contact; int main(int argc, char *argv[]) { QCoreApplication::setAttribute(Qt::AA_EnableHighDpiScaling); QGuiApplication app(argc, argv); QList<QObject*> dataList; dataList.append(new ContactList("کامبیز", "اسدزاده", "09140000000", "Apple iPhone", "https://avatars0.githubusercontent.com/u/4066299?s=460&v=4", "#00D397", "https://github.com/Kambiz-Asadzadeh")); dataList.append(new ContactList("حامد", "مصافی", "09350000000", "Samsung Galaxy", "https://avatars2.githubusercontent.com/u/13809362?s=460&v=4", "#E83B0B", "https://github.com/HamedMasafi")); dataList.append(new ContactList("بهنام", "صباغی", "09190000000", "Google Nexus", "https://avatars3.githubusercontent.com/u/17690495?s=460&v=4", "#E15504", "https://github.com/FONQRI")); dataList.append(new ContactList("آرش", "میلانی", "09140000000", "Apple iPhone", "https://avatars3.githubusercontent.com/u/586816?s=460&v=4", "#3650F7", "https://github.com/arashmilani")); dataList.append(new ContactList("سروش", "ربیعی", "09190000000", "Google Nexus", "https://avatars0.githubusercontent.com/u/920670?s=460&v=4", "#8C56EA", "https://github.com/soroush")); QQmlApplicationEngine engine; QQmlContext *ctxt = engine.rootContext(); qmlRegisterType<ContactList>("api.dotwaves.qml", 1, 0, "Data"); ctxt->setContextProperty("contactModel", QVariant::fromValue(dataList)); engine.load(QUrl(QStringLiteral("qrc:/main.qml"))); if (engine.rootObjects().isEmpty()) return -1; return app.exec(); } تحت کلاس QList اشیاء را به کلاس ساخته شده سفارشی خود به عنوان دادههای جدید معرفی میکنیم. جهت رجیستر (ثبت) کردن کلاس و دادههای سمت بکاِند به سمت فرانت اِند در QML توسط تابع qmlRegisterType به عنوان یک تابع سربار گذاری شده اقدام میکنیم که ساختار آن به صورت زیر است: qmlRegisterType<MyClass>("com.mycompany.qmlcomponents", 1, 0, "CppClass"); این کار باعث میشود شما به کلاسها و توابع کلاس سفارشی خود در سمت فرانت اند دسترسی داشته باشید. این روش در این پروژه اختیاری بوده است و فعلاً آنچنان مهم نیست اما برای اینکه روش آن را بدانید آورده شده است. در ادامه با نمونه گیری کلاس QQmlContext تابع setContextProperty که به عنوان ریشهای از محتوا مجموعهای از خواصهای موجود از مُدل کلاس را بر میگرداند را تنظیم میکند که نام ویژگی را در قالب QVariant برمیگرداند. در نهایت قرار است با استفاده از نوع ListView در سمت QML مقادیر ارسالی از سمت سیپلاسپلاس را دریافت کنیم. به عنوان مثال دریافت نام به صورت زیر خواهد بود: ListView { id:listview model : contactModel delegate: Rectangle { .... ....... Text { id: nameTitle text: model.modelData.name } } نمونه خروجی این مثال به صورت زیر است: برای دسترسی به منبع این مثال میتوانید به گیتهاب من در این لینک مراجعه کنید.












