جستجو در تالارهای گفتگو
در حال نمایش نتایج برای برچسب های 'cpp'.
22 نتیجه پیدا شد
-
ترکیب کدهای ++C با وردپرس بدون شکستن کد آن
کامبیز اسدزاده نوشته وبلاگ را ارسال کرد در برنامه نویسی
سادهترین راه برای افزودن کد سفارشی به سایتهایی که بر پایهٔ وردپرس ساخته شدهاند، بدون شکستن کد آن چیست؟ زبان برنامهنویسیِ ++C یکی از محبوبترین زبانهای برنامهنویسی است. آخرین آمار نشان میدهد که این زبان با سرعت بسیار زیادی در حال توسعه و پوستاندازی است. این زبان، علیرغم اینکه بیش از 40 سال از عمرش میگذرد، همچنان زبان انتخابی برای بسیاری از برنامهنویسان در سراسر جهان است. برای بسیاری از موارد مانند برنامههای کاربردی دستکاری تصویر، بازیهای سه بعدی، شبیه سازیها، مرورگرهای وب و نرمافزارهای سازمانی استفاده میشود. دلیلش این است که سیپلاسپلاس در حال تکامل است، به انرژی سبز اهمیت میدهد و در عین حال کارآیی بسیار بالا و بهینهای دارد. از آنجایی که این زبان پیچیدهتر از سایر زبانهای برنامهنویسی است، یک کمیتهٔ فرعی از یک سازمان چند سطحی وظیفه استانداردسازی آن را بر عهده دارد. سیپلاسپلاس اکنون از یک مدل قطار پیروی میکند و هر سه سال یکبار نسخههای جدید دریافت میکند که در مورد استانداردهای جدید، اخیراً مقالاتی منتشر شده است. سیپلاسپلاس معمولاً برای توسعهٔ نرمافزار در مقیاس بزرگ استفاده میشود، اما میتوان از آن برای پروژههای توسعه وب نیز استفاده کرد. ممکن است تعجب کنید که چگونه از آن با وردپرس، یکی از محبوبترین سیستمهای مدیریت محتوا و سازندگان وب سایت امروزه استفاده کنید. در این باره قبلاً من مقالاتی را منتشر کردهام که به صورت زیر آمدهاند: در حالی که بسیاری از وب سایتها با استفاده از وردپرس به عنوان پایه ساخته میشوند، این لزوماً به این معنی نیست که اکوسیستم وردپرس تکامل یافته یا کامل است. به عنوان مثال، وردپرس تمرکز زیادی بر تجربهکاربران و نیازهای وبلاگ نویسان دارد، به همین دلیل است که بر چهار زبان HTML، CSS، جاوا اسکریپت و PHP متکی است و این بدان معناست که برای توسعهدهندگانی که میخواهند به طور کامل از قدرت آن استفاده کنند، محدودیتهایی وجود دارد. در حالی که افزونههایی مانند Custom Post Types برای گسترش عملکرد وردپرس وجود دارد و راههای زیادی برای افزودن قابلیتهای جدید بدون شروع از ابتدا وجود ندارد. همچنین، افزودن کد ++C به طور مستقیم به یک سایت وردپرس توصیه نمیشود زیرا به طور بالقوه میتواند آسیب پذیریهای امنیتی را ایجاد کند و وب سایت را خراب کند. با این حال، اگر نیاز خاصی به اجرای کد ++C در سایت وردپرس شما وجود دارد، در اینجا روشهایی که میتوانید آن را انجام دهید گفته شدهاست: شما می توانید یک برنامه یا کتابخانه مستقل ++C ایجاد کنید و سپس آن را از طریق وب API در معرض دید قرار دهید، که میتواند توسط وردپرس مصرف شود. بیایید نگاهی به مراحل کلی بیندازیم: کد ++C خود را بنویسید و آن را در یک برنامه یا کتابخانه مستقل کامپایل کنید. عملکرد برنامه یا کتابخانه ++C را از طریق وب API به نمایش بگذارید. شما میتوانید از یک کتابخانه به عنوان cpprestsdk برای ایجاد نقاط پایانی API استفاده کنید. برنامه یا کتابخانه ++C را بر روی یک سرور، یا در همان سرور سایت وردپرس خود یا در یک سرور جداگانه، مستقر کنید. در سایت وردپرس خود، از یک افزونه یا کد سفارشی برای درخواست HTTP به API و بازیابی نتایج استفاده کنید. شما میتوانید از کتابخانهای مانند cURL برای ارائه چنین درخواستهایی استفاده کنید. در صورت نیاز از نتایج بازیابی شده در سایت وردپرس خود استفاده کنید. راه دیگر برای افزودن قابلیت ++C به سایت وردپرس استفاده از افزونهای است که به شما امکان میدهد کد ++C را مستقیماً در صفحات یا پستهای وردپرس جاسازی کنید. مراحل بسته به افزونهای که استفاده میکنید متفاوت است، اما در اینجا چند مرحله کلی وجود دارد که میتواند کمک کند. افزونهای را که از کد ++C پشتیبانی میکند را در سایت وردپرس خود نصب کنید. یک صفحه یا پست جدید در وردپرس ایجاد کنید و کد کوتاه [cpp] را به قسمت محتوا اضافه کنید. در کد از نوع برچسبِ [cpp]، کد ++C خود را اضافه کنید. صفحه یا پست را منتشر کنید و آن را مشاهده کنید تا کد جاسازی شده ++C را در عمل ببینید. مجدداً توجه داشته باشید که افزودن کد ++C به طور مستقیم به یک صفحه یا پست میتواند خطرناک باشد. مهم است که پیادهسازی خود را به طور کامل آزمایش کنید تا مطمئن شوید که ایمن و قابل اعتماد است. از هر روشی که استفاده میکنید، به یک پایه محکم در سیپلاسپلاس و مهارتهای یکپارچه سازی وردپرس نیاز دارد. وقتی صحبت از وردپرس به میان میآید، شاید بهتر باشد از زبانی مانند PHP استفاده کنید. اگر میخواهید دربارهٔ ++C و نحوهٔ به حداکثر رساندن آن برای پروژهتان بیشتر بدانید، میتوانید به آموزههای مربوط به سیپلاسپلاس در این سایت را بررسی کنید یا کتابهای پیشنهادی در بخش معرفی زبان را بخوانید. فراموش نکنید که سیپلاسپلاس یک زبان جذاب و همیشه در حال تکامل است و افزودن آن به مجموعه مهارتهای شما سودمند است. -
جایزهٔ زبان برنامهنویسی سال TIOBE به ++C تعلق یافت!
کامبیز اسدزاده نوشته وبلاگ را ارسال کرد در ابزارها
در سالی که گذشت (۲۰۲۲)، سیپلاسپلاس محبوبترین زبان برنامهنویسی با رشد شاخص محبوبیت ۴.۶۲٪ انتخاب شد! جایزه زبان برنامهنویسی سال TIOBE به ++C تعلق گرفت! این جایزه به زبان برنامهنویسی تعلق میگیرد که بیشترین افزایش محبوبیت را در یک سال تجربه کرده است. شاخص TIOBE میزان محبوبیت زبانهای برنامهنویسی را اندازهگیری میکند. با این حال، قبل از نتیجهگیری، توجه به این نکته مهم است که Index (شاخص) نه چیزی در مورد کیفیت یک زبان برنامهنویسی میگوید و نه ادعا میکند. این رتبهبندی با تجزیه و تحلیل تعداد مهندسان ماهر در یک زبان خاص، تعداد دورههای آموزشی در آن زبان و تعداد فروشندگان شخص ثالثی که محصولات یا خدمات مرتبط با آن زبان را ارائه میدهند، محاسبه میشود. این فهرست ماهانه بهروز میشود و بر اساس دادههای موتورهای جستجوی محبوب مانند گوگل، بینگ و یاهو است. جایزهٔ زبان برنامهنویسی سال TIOBE در ژانویه هر سال بر اساس رتبهبندی سال قبل اعلام میشود. سیپلاسپلاس یک زبان برنامهنویسی در سال ۲۰۲۲ انتخاب شد که با محبوبیت رشد ۴.۶۲ درصد و بیشترین رشد انتخاب شده است. این زبان برنامهنویسی سطح بالا با کارایی بالا و چندمنظوره برای توسعهٔ نرمافزارهای سیستمی، برنامههای کاربردی و بازیهای ویدیویی با انعطافپذیری و قابلیت کنترل سطوح پایین است. این زبان در نوامبر ۲۰۲۲ جاوا را پشتسر گذاشت و به رتبهٔ سوم شاخص رسید و محبوبیت آن به طور پیوسته در حال افزایش است. نایب قهرمان در سال ۲۰۲۲ به ترتیب C با رشد ۳.۸۲ و پایتون با ۲.۷۸ درصد رشد بودهاند. -
یک سوأل بسیار مهم و پر مخاطب در بارهٔ زبانبرنامهنویسی سیپلاسپلاس در سالهای اخیر این است که «آیا جایگزینی برای این زبان وجود دارد و یا قابل جایگزین است»؟ در بسیاری از پاسخها نشان از گزینههایی مانند Go، Rust و D دیده میشود که بهتر است نسبت به نظرات متخصصهای برنامهنویسی به این موضوع پرداخته شود، ابتدا باید در نظر گرفت که هر ابزاری میتواند جایگزینی داشته باشد اما شرایط و نحوهٔ استفادهٔ آن در رابطه با نیاز متفاوت است. اخیراً سوألات زیادی در این موضوع دیده شده است که میگویند، Rust یک زبان برنامهنویسی ایمن، سریع و سیستمیِ جایگزین برای سیپلاسپلاس است! اما آیا واقعاً اینگونه است یا صرفاً ما بر اساس احساسات و اشتیاق به بهروز شدن به این موضوع میپردازیم؟ پاسخ برای این سوأل به صورت زیر در مدلهای مختلف میتواند مطرح شود که نتیجهگیری و تصمیم از خلاصهٔ آن به عهدهٔ خودِ شماست. من بر این باورم که زبانهای برنامهنویسی همه و همه در حال بهروز رسانی و بهتر شدن نسبت به نسخهها، استانداردها، و نسلهای گذشتهٔ خودشان هستند و به هیچ عنوان هیچ زبانی تا به امروز به طور جدی منسوخ شده اعلام نشده است. برای درک این مطلب بهتر است ابتدا به واژهٔ «منسوخ شده» یا «Deprecated» بپردازیم، این واژه زمانی مورد استفاده قرار میگیرد که شرایط زیر بر آن حاکم باشد: گزینهٔ مورد نظر به طور رسمی از طرف سازنده، پشتیبان یا صاحب آن بد دانسته شده و رسماً کنار گذاشته شود. گزینهٔ مورد نظر بهروز رسانی نشود و آخرین بهروز رسانی آن نیز شامل مشکلاتی باشد که بعد از مدتها نیز حل نشده باشد. گزینهٔ مورد نظر دیگر مورد استفاده قرار نگیرد و کاربردی هم در بین رقبای خود نداشته باشد. گزینهٔ مورد نظر دیگر پشتیبانی نشود و به قولی مُرده باشد. گزینهٔ مورد نظر به علاوهٔ این که شامل این موارد میشود، باید دارای یک جایگزین مناسب و عالی باشد. با توجه به این معیارها و با در نظر گرفتن رسالت هر یک ابزارها باید به آن توجه کرد که هر زبان یا ابزار برنامهنویسی خارج از این، در مرحلهٔ پیشرفت قرار گرفته است که آن نشان دهندهٔ زنده بودن و کاربردی بودن آن است. از طرفی، زبانی مثل سیپلاسپلاس جایگزین نمیشود چرا که هیچ یک از دلایل و معیارهای بالا شامل حال آن نمیشود، اتفاقاً برعکس این زبان دارای ویژگیهای معیاری زیر است: این زبان به طور رسمی توسط کمیتهٔ استانداردسازی که متعلق به هیچ یک از شرکتهای غول صنعتی و یا خصوصی نمیباشد پشتیبانی میشود. این زبان به طور مداوم در حال بهروز رسانی است و کاربردهای چند-منظوره و همه جانبهٔ خود را داراست. این زبان از ویژگیهای از ویژگیهای بسیار خوب به همراه سریعترین بازدهیها را داراست. این زبان رقیبهای بسیاری دارد، اما هیچ کدام از آنها هنوز در عمل و دامنهٔ وسیعی موفق به نمایش عملکرد بهتری نبودهاند. این زبان همانند دیگر ابزارها دارای مشکلاتی است، اما با توجه به پوشش و پشتیبانی از ویژگی BC در روند استانداردسازی و بهروز رسانی به خوبی از پس آنها بر آمده است. برای مثال، زبان جاوا یکی از بهترین زبانهای برنامهنویسی است و خیلی از شرکتها مانند گوگل در سیستمهای توزیع شده از آن استفاده میکنند. اما به معنای این نیست که به سرعت سی++ میرسد و در حد مقایسه با آن است. این زبان میتواند دهها و صدها برابر کندتر از سی++ باشد و این مربوط به طراحی، ساختار و مسائل مربوط به زبان است. از طرفی سیپلاسپلاس محبوب است زیرا که ویژگیهای زیر را دارد و طی سالهای بسیاری آن را ثابت کرده است: کارآیی (پرفرمنس) و سرعت فوقالعادهٔ این زبان، البته خیلی از زبانها ادعا میکنند که همچین ویژگیای را دارند که در عمل نتیجهٔ جالبی مشاهده نمیشود. ذاتِ چند-سکویی و چند-منظوره بودن آن، حداقل همهٔ سیستمها میتوانند کدهای سی++ را کامپایل و اجرا کنند. این زبان به راحتی میتواند با زبانها و فناوریهای دیگری ارتباط برقرار کرده و با آنها تعامل داشته باشد. این زبان به عنوان یکی از کممصرفترین زبانهای برنامهنویسی از نظر مصرف انرژی محسوب میشود. بسیاری از مهندسین این زبانها را به صورت مقطعی و بارها دیده و با آن آشنا هستند. کتابخانههای پیشفرض استاندارد STL و دیگر کتابخانههای سی++ بسیار قدرتمند و گسترده هستند. کتابخانههای نوع سوم (Third-Party) بسیار قدرتمند و بهروز هستند. اولویتهای سیستمهای یونیکس و حتی ویندوز اکثراً بر روی C و ++C است و بازنویسی آنها با زبانهای دیگر هزینهٔ بسیاری را به ارمغان میآورد. بسیاری از وابستگیهای ایجاد شده در سالهای بسیار طولانی بر اساس سی و سی++ بوده و بازنگری و بازنویسی آنها مشروط بر این که رابطها باید بازنویسی شود بسیار سخت و کاری مشابه اختراع دوبارهٔ چرخ است. عملکرد تا حدی قابل پیشبینی است و میتواند آن را درک کرد، چیزی که در زبانهایی مانند جاوا، سیشارپ و گو نمیتواند پیشبینی کرد چرا که پیشبینی چرخهٔ GC دشوار است، هیچ رقیب جدیای در این باره در سطح سی++ وجود ندارد که مدیریت حافظه را برای شما در قالب یک RAII ارائه کند، هرچند در مورد Objective-C و Rust میتوان آنها را به صورت جداگانه مورد بررسی قرار داد و نه عین آن. پشتیبانی از پارادایم (سبک)های طراحی را سی++ به خوبی پشتیبانی میکند، برای مثال برنامهنویسی عمومی در زمان کامپایل را به خوبی ارائه میکند. پشتیبانی از برنامهنویسی سیستمی و سطح پایین در این زبان یک مزیتی دیگری است که در کنار تمامی ویژگیهای سطح بالای خود ارائه میکند. اما در این میان زبانهایی مثل Rust، Go، Swift و غیره ادعای جایگزینی را دارند اما ادعاهای فنی به تنهایی کافی نیستند، در دسترس بودن گسترده از جامعه به اندازهٔ کافی به همراه جامعهٔ معتمد به آن مهم است. علاوه بر ویژگیهای فنی زبان سی++، یک نقطه قوت بسیار مهم این زبان در بحث غیر فنی آن است، در واقع در پشت این زبان نه یک پیادهسازی محدودی وجود دارد و نه یک سازمان که در آینده در مورد آن تصمیم بگیرد و آن را کنترل کند. در حالی که تمامی زبانهای مطرح و ادعا کننده داخل یک چهارچوبی کنترل میشوند که به شدت آیندهٔ آنها را تیره و تار میکند. به طور کلی آزاد بودن یک ابزار و قدرت یک جامعه فارغ از جغرافیا، سازمان، نژاد و زبان یک قدرت بسیار خارقالعادهای را برای یک ابزار به ارمغان میآورد که به تنهایی بسیار اهمیت دارد. در این اواخر بسیاری از مهندسین به فکر بازنویسی بسیاری از موارد شدن و تحقیقات نشان میدهد ابزارهایی گرافیکی بسیار قدرتمند و سریع که اخیراً طراحی شدهاند، مانند وُلکان که با سی++ نوشته شده است زمانی میتوانند با راست و زبانهای دیگر امروزی بازنویسی شوند که یک سیستمعامل جدید با زبانهای جدید ساخته شود! بنابراین صرفاً میتوان یک نسخهٔ Wrapper یا همان (پوشنده) چرا که تقریباً همهٔ سیستمعاملهای مدرن امروزی با زبانهای سی و سی++ نوشته شدهاند. از طرفی تولید یک سیستمعامل بسیار پر خطر است و سرمایهگذاری کلان، زمان و هزینههای بسیاری را میطلبد و تا زمانی که چنین نرمافزارهایی تحت سلطهٔ زبانهایی مانند سی++ قرار گرفته باشند پادشاهی سیپلاسپلاس ادامه خواهد داشت. نکتهٔ پایانی من معتقدم هر ابزار و زبانهای برنامهنویسی جایگاه و شرایط استفادهٔ خودشان را شامل میشوند، دقیقاً مانند ابزارهای موجود در یک جعبهابزار بهتر است ابزارهای خود را طوری بچینید که در جای لازم از مناسبترین آنها استفاده کنید. با این حال زبانها و ابزارهای مانند سی یا سی++ طی سالها ثابت کردهاند که معمولاً در همهٔ حوزهها غالب هستند و میتواند هر کاری را که بخواهید با آنها انجام دهید و یا با یک جایگرین مناسب آن را مدیریت کنید و این بستگی به مهارت و انتخاب شخصی شما دارد. همچنین صحبتهای اخیر کمیتهٔ استانداردسازی در رابطه با نحو ۲ از سیپلاسپلاس میتواند مفهوم خوبی در آیندهٔ این زبان باشد. مقالات مرتبط با این موضوع که میتواند به عنوان مکملی از پیش تعریف شده برای شما مفید باشد:
-
سلام.وقتتون بخیر. امیدوارم حالتون خوب باشه. من برای ولیدت کردن تکست فیلد نام کاربری از کد زیر استفاده میکنم.ولی متاسفانه بعد از استفاده از regular expression زیر برای نام کاربری، دیگه نمیتونم هیچ مقداری رو داخل تکست فیلد وارد کنم. TextField{ Layout.preferredWidth: parent.width font.family: appTextFont.name font.pixelSize: designSettingItem._textFontSize validator: RegExpValidator { regExp: /^[a-zA-Z0-9]([._-](?![._-])|[a-zA-Z0-9]){3,18}[a-zA-Z0-9]$/ } } این regular expression رو هم از سطح وب پیدا کردم.
-
سلام من به تازگی با opengl کار میکنم میخواستم بدونم ایا منطقی هست که به جای ساخت ابجکت های گرافیکی توسط کتابخانه window.h (در ویندوز) و یا x11.h (داخل لینوکس) من خودم داخل کد c یا cpp بعد از ساخت پنجره مربوط به opengl ابجکت ها را خودم و داخل opengl بسازم و قابلیت های کلیک شدن و سلکت شدن و ... خودم اضافه کنم؟؟ از این منظر که بتونم ابجکت های سفارشی با هر شکل و ظاهری را بسازم و در کل میخوام کنترل کل برنامه دست خودم باشه، چون اینجوری عداوه بر این که میدونم ظاهر برنامه چطور ساخته شده ،حجم برنامه هم خیلی کم میشه در مقایسه با qt
-
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #7a75ff; color: #ffffff;" >پادکستهای آموزشی</span>
پادکستِ مربوط به شفافسازی تقریبی از مسیرِ توسعهدهندگی تحت سی++ و ساخت محصولِ هدفمند زمان مورد نیاز : ۲۰ دقیقه و ۱۱ ثانیه Podcast-03.mp3 -
اگر آبجکتی رو به صورت سینگلتون در چندجای برنامه استفاده کنیم، به این دلیل که این آبجکت در چندجا در حال استفاده هست و نمی شود آن را دیلیت کرد و از اول ایجاد کرد(یا حتی یکی دیگر ایجاد کنم و جایگزین قبلی کنم)، آیا امکانش هست که آن آبجکت ریست بشود (آبجکت به لحظه های اولیه ساخته شدنش برگرده)؟ برای این می پرسم که دیگر نیاز نباشد خودم اطلاعات داخل آبجکت رو به حالت اول برگردانم. .
-

قسمت اول معماری CPP: مبحث Overloading و Name Mangling و Template و Auto
cdefender نوشته وبلاگ را ارسال کرد در برنامه نویسی
هنگامیکه شما برای اولین بار از C به CPP مهاجرت می کنید، یا اصلا برنامه نویسی را قصد دارید با CPP شروع کنید، با مفاهیم متعددی روبرو خواهید شد که شاید برای شما جالب باشند که بدانید، این ایده ها چطور شکل گرفتند، چطور به CPP افزوده شدند و اهمیت آن ها در عمل (هنگام برنامه نویسی و توسعه نرم افزار) چیست. در این پست وبلاگی IOStream، به این خواهیم پرداخت که ایده Overloading و Template و Auto Deduction چطور از CPP سر در آوردند. همانطور که شما ممکن است تجربه کرده باشید، هنگامیکه برنامه نویسی و توسعه نرم افزاری را با C شروع می کنید، برنامه شما چیزی بیش از یک مجموعه بی انتها از توابع و استراکچرها و متغیرها و اشاره گرها و ... نخواهند بود. از همین روی شما مجبور هستید مبتنی بر ایده مهندسی نرم افزار و پارادیم برنامه نویسی ساخت یافته، برای هر کاری یک تابع منحصربفرد پیاده سازی کنید. این تابع باید از هر لحاظی از قبیل نام، نوع ورودی ها، نوع خروجی و حتی نوع عملکرد منحصربفرد باشد تا بتواند یک کار را به شکل صحیح کنترل کند که همین مسئله می تواند در پیاده سازی برخی نرم افزارها، انسان را در جهنم داغ و سوزان قرار بدهد. مثلا پیاده سازی یک برنامه محاسباتی مانند ماشین حساب که ممکن است با انواع داده های محاسباتی مانند عدد صحیح (Integer) و عدد اعشاری (Float) رو به رو شود. از همین روی فرض کنید، ما قرار است یک عمل محاسباتی مانند جمع از برنامه ماشین حساب را پیاده سازی کنیم. برای اینکه برنامه به شکل صحیحی کار کند، باید عمل جمع یا همان Add برای انواع داده های موجود از قبیل عدد صحیح و اعشاری پیاده سازی شود. اگر شما این کار را انجام ندهید، برنامه شما به شکل صحیحی کار نخواهد کرد (یعنی نتایج اشتباه ممکن است برای ما تولید کند). در تصویر زیر، نمونه این برنامه و توابع مرتبط با آن پیاده سازی شده است: #include <stdio.h> int AddInt(int arg_a, int arg_b) { return arg_a + arg_b; } float AddFloat(float arg_a, float arg_b) { return arg_a + arg_b; } double AddDouble(double arg_a, double arg_b) { return arg_a + arg_b; } int main(int argc, const char* argv[]) { int result_int = AddInt(1, 2); float result_float = AddFloat(10.02f, 21.23f); double result_double = AddDouble(9.0, 24.3); printf("Result Integer: %d", result_int); printf("Result Float: %f", result_float); printf("Result Double: %lf", result_double); return 0; } به برنامه بالا دقت کنید. ما سه تا تابع Add با نام های منحصربفرد داریم که سه نوع داده مجزا را به عنوان ورودی دریافت می کنند، سه نوع نتیجه مجزا بازگشت می دهند، اگرچه پیاده سازی آن ها کاملا مشابه هم دیگر است و تفاوتی در پیاده سازی این سه تابع وجود ندارد. ولی به هر صورت، اگر به خروجی دیزاسمبلی برنامه مشاهده کنید، دلیل این مسئله را متوجه خواهید شد که چرا هنگام برنامه نویسی با زبان C، به نام های منحصربفرد نیاز است، چون اگر توابع نام های مشابه با هم داشته باشند، لینکر نمی تواند به دلیل تداخل نام (Name Conflict)، آدرس آن ها را محاسبه یا اصطلاحا Resolve کند. همانطور که در تصویر بالا خروجی دیزاسمبلی برنامه Add را مشاهده می کنید، اگر توابع نام مشابه داشتند، در هنگام فراخوانی (Call) تابع Add تداخل رخ می داد، چون دینامیک لودر سیستم عامل دقیقا نمی داند که کدام تابع را باید فراخوانی کند. برای همین نیاز است وقتی برنامه نوشته می شود، نام توابع در سطح کدهای اسمبلی و ماشین منحصر بفرد باشد. به هر صورت، به نظر شما آیا راهی وجود دارد که ما پیاده سازی این نوع توابع را ساده تر کنیم یا حداقل بار نامگذاری آن ها را از روی دوش توسعه دهنده و برنامه نویس برداریم؟ بله امکان این کار وجود دارد. مهندسان CPP با افزودن ویژگی Overloading و Name Mangling یا همان بحث Decoration مشکل برنامه نویسان در پیاده سازی توابع با نام های منحصربفرد را حل کردند (البته کاربردهای دیگر هم دارد که فعلا برای بحث ما اهمیت ندارند). ویژگی اورلودینگ در CPP به ما اجازه خواهد داد یک تابع با عنوان Add پیاده سازی کنیم که تفاوت آن ها فقط در نوع ورودی و نوع خروجی است. به عنوان مثال، در قسمت زیر، کد برنامه Add را مشاهده می کنید که با قواعد CPP بازنویسی شده است. #include <iostream> int Add(int arg_a, int arg_b) { return arg_a + arg_b; } float Add(float arg_a, float arg_b) { return arg_a + arg_b; } double Add(double arg_a, double arg_b) { return arg_a + arg_b; } int main(int argc, const char* argv[]) { int result_int = Add(1, 2); float result_float = Add(10.02f, 21.23f); double result_double = Add(9.0, 24.3); std::cout << "Result Integer: " << result_int << std::endl; std::cout << "Result Float: " << result_float << std::endl; std::cout << "Result Double: " << result_double << std::endl; return 0; } همانطور که مشاهده می کنید، ما اکنون سه تابع با نام Add داریم. ولی شاید سوال پرسیده شود که چطور لینکر متوجه تفاوت این توابع با یکدیگر می شود درحالیکه هر سه دارای یک نام واحد هستند. اینجاست که مسئله Name Mangling یا همان Decoration نام آبجکت ها در CPP مطرح می شود. اگر شما برنامه مذکور را دیزاسمبل کنید، متوجه تفاوت کد منبع (Source-code) و کد ماشین/اسمبلی (Machine/Assembly-code) خواهید شد. همانطور که در خروجی دیزاسمبلی برنامه اکنون مشاهده می کنید، توابع اگرچه در سطح کد منبع دارای نام مشابه با یکدیگر بودند، اما بعد کامپایل نام آن ها به شکل بالا تبدیل می شود. به این شیوه نام گذاری Name Mangling یا Decoration گویند که قواعد خاصی در هر کامپایلر برای آن وجود دارد. این ویژگی موجب می شود در ادامه لینکر بتواند تمیز بین انواع توابع Add شود. به عنوان مثال، تابع نامگذاری شده با عنوان j__?Add@YAHH@Z تابعی است که به نوعی از تابع Add اشاره دارد که ورودی هایی از نوع عدد صحیح دریافت می کند. این شیوه نامگذاری خلاصه موجب خواهد شد لینکر بتواند به سادگی بین توابع تمایز قائل شود. با این حال هنوز یک مشکل باقی است، و آن هم تکرار مجدد یک پیاده سازی برای هر تابع است. به نظر شما آیا راهی وجود دارد که ما از پیاده سازی مجدد توابعی که ساختار مشابه برای انواع ورودی ها دارند، جلوگیری کنیم؟ باید بگوییم، بله. این امکان برای شما به عنوان توسعه دهنده CPP در نظر گرفته شده است. ویژگی که اکنون به عنوان Templateها در مباحث Metaprogramming یا Generic Programming استفاده می شود، ایجاد شده است تا این مشکل را اساساً برای ما رفع کند. با استفاده از این ویژگی کافی است، طرح یا الگوی یک تابع را پیاده سازی کنید، تا در ادامه خود کامپایلر مبتنی بر ورودی هایی که به الگو عبور می دهید، در Backend، یک نمونه تابع Overload شده مبتنی بر آن الگو برای نوع داده شما ایجاد کند. #include <iostream> template <typename Type> Type Add(Type arg_a, Type arg_b) { return arg_a + arg_b; } int main(int argc, const char* argv[]) { int result_int = Add(1, 2); float result_float = Add(10.02f, 21.23f); double result_double = Add(9.0, 24.3); std::cout << "Result Integer: " << result_int << std::endl; std::cout << "Result Float: " << result_float << std::endl; std::cout << "Result Double: " << result_double << std::endl; return 0; } به عنوان مثال، در بالا تابع Add را مشاهده می کنید که نوع داده ورودی این تابع و حتی نوع خروجی آن مشخص نشده است و در قالب Typename به کامپایلر معرفی شده است. این یک الگو برای تابع Add است. کامپایلر اکنون می تواند مبتنی بر ورودی هایی که به تابع هنگام فراخوانی یا اصطلاحا Initialization عبور می دهیم، یک نمونه تابع Overload شده از آن الگو ایجاد کند و در ادامه آن را برای استفاده در محیط Runtime فراخوانی کند. حال اگر برنامه بالا را دیزاسمبل کنید، مشاهده خواهید کرد که کامپایلر از همان قاعده Overloading استفاده کرده است تا نمونه ای از تابع Add متناسب با نوع ورودی هایش ایجاد کند. هنوز می توان برنامه نویسی با CPP را جذاب تر و البته ساده تر کرد، اما چطور؟ همانطور که در قطعه کد بالا مشاهده می کنید، هنوز ما باید خود تشخیص دهیم که نوع خروجی تابع قرار است به چه شکل باشد. این مورد خیلی مواقع مشکل ساز خواهد بود. برای حل این مسئله، در CPP مبحثی در نظر گرفته شده است که آن را به عنوان Auto Deduction می شناسیم که سطح هوشمندی کامپایلر CPP را بالاتر می برد. در این ویژگی خود کامپایلر است که مشخص می کند نوع یک متغیر مبتنی بر خروجی که به آن تخصیص داده می شود، چیست. به عنوان مثال، شما می توانید برنامه بالا را به شکل زیر بازنویسی کنید: #include <iostream> template <typename Type> auto Add(Type arg_a, Type arg_b) { return arg_a + arg_b; } int main(int argc, const char* argv[]) { auto result_int = Add(1, 2); auto result_float = Add(10.02f, 21.23f); auto result_double = Add(9.0, 24.3); std::cout << "Result Integer: " << result_int << std::endl; std::cout << "Result Float: " << result_float << std::endl; std::cout << "Result Double: " << result_double << std::endl; return 0; } با استفاده از ویژگی Auto Deduction و کلیدواژه Auto در برنامه، خود کامپایلر در ادامه مشخص خواهد کرد که تابع Add چه نوع خروجی دارد و همچنین نوع متغیرها برای ذخیره سازی خروجی Add چه باید باشد. به عبارتی اکنون تابع Add هم Value و هم Data type را مشخص می کند که این موجب می شود برنامه نویسی با CPP خیلی ساده تر از گذشته شود. حال اگر به نمونه برنامه آخر نگاه کنید و آن را با نمونه C مقایسه کنید، متوجه خواهید شد که CPP چقدر کار را برای ما ساده تر کرده است. در این پست به هر صورت، قصد داشتم به شما نشان دهم که نحوه تحول CPP به صورت گام به گام چطور بوده است و البته اینکه پشت هر ویژگی در CPP چه منطق کلی وجود دارد. امیدوارم این مقاله برای شما مفید بوده باشد. نمونه انگلیسی این مقاله را می توانید در این آدرس (لینک) مطالعه کنید. میلاد کهساری الهادی -
با توجه به محبوبیت صنعت وِب، سالهاست زبانهای برنامهنویسی در این زمینه پیشرفتها و کاربردهای چشمگیری را داشتهاند، از جمله جاوااسکریپت (JS) به عنوان یک زبان قابل اجرا در داخل مرورگر شناخته میشود. هرچند بسیار محبوب و کاربردی است، اما این زبان قطعاً مشکلات خودش را دارد که برخی از آنها عدم انعطافپذیر بودن، سرعت پایین اجرا و همچنین انواع غیر ایمن آن است که این باعث میشود برای محاسبات و کارهای پیچیده جوابگو نباشد. هرچند گزینههایی مانند CoffeeScript و TypeScript وجود دارند و نسبتاً ایرادات خام جاوااسکریپتی را پوشش میدهند، اما در نهایت کدهای نوشته شده به جاوااسکریپت تبدیل میشود. در این میان میتوان گفت وباسمبلی (WebAssembly) برای حل و مرتب سازی مشکلات جاوااسکریپت معرفی شده است و شدیداً در حال اثبات آن است که یک انقلاب در صنعت وِب را رقم میزند. با این تفاسیر، آیا وباسمبلی زبان برنامهنویسی است؟ این فناوری به خودی خود، یک زبان برنامهنویسی نیست، در واقع برنامهنویسان برنامههای خود را توسط زبانهای سطحبالا مانند C یا ++C و حتی Rust مینویسند و آن را کامپایل و در قالب باینری با پسوند فایل .wasm وارد میکنند. توجه داشته باشید که وباسمبلی جایگزینی برای جاوااسکریپت نیست، درواقع قرار است در کنار جاوااسکریپت اجرا شود. به عنوان مثال شما میتوانید فقط یک کد محاسباتی بالا را در WebAssembly بسازید و آن را در کنار سایر کدهای جاوااسکریپت با وزن سبکتر استفاده کنید. همچنین شما برای بارگذاری ماژول wasm در مرورگر به جاوااسکریپت نیاز دارید. فناوری وباسمبلی (WebAssembly) و یا WA چیست؟ وباسمبلی یا وَسم (Wasm، اغلب به طور مخفف) استانداردی باز است که یک قالب جدید دستورالعملهای باینری را معرفی میکند. این فناوری نوید این را میدهد که برنامهها با کارآیی (پرفرمنس) بومیِ خود در بستر وِب اجرا شوند. به عبارت سادهتر میتوان گفت، این فناوری امکان این را میدهد که کدهای نوشته شده با زبانهای سطح بالاتر مانند C و ++C یا Rust به ماژول Wasm کامپایل شوند که مستقیماً در مرورگرهای مدرن قابل اجرا هستند. معماری وباسمبلی وباسمبلی به گونهای طراحی شده است که بر روی دستگاههای مجازی مبتنی بر پشته (stack-based) اجرا شود. بر خلاف ماشینهای رجیستری که عملوندهای آنها بر روی پردازندهٔ مرکزی قرار دارند و محاسبات در آن بخش اتفاق میافتد، در یک ماشین مبتنی بر پشته، بیشتر دستورالعملها به جای اینکه بر روی رجیستر اعمال شوند، بر روی پشته مینشینند. برای افزودن دو عدد بر روی ماشین مبتنی بر پشته، شمارههای مربوطه را در پشته ارسال میکنید. سپس دستور ADD را فشار میدهید. سپس دو عملگر و دستورالعمل از بالای صفحه ظاهر میشود و نتیجهٔ اضافی در جای خود قرار میگیرد. برخی از این نوع ماشینها عبارتند از .Net، JVM Runtime و غیره. وباسمبلی به معنای سنتی، پشتهای ندارد. درواقع هیچ مفهومی از اپراتورهای جدید ندارد. حتی خبری از GC در آن وجود ندارد. در عوض وباسمبلی دارای یک حافظهٔ خطی است، یعنی حافظه به عنوان طیف پیوسته از بایتهای بدون نوع نمایش داده میشود. در صورت نیاز به فضای بیشتر، ماژول وباسمبلیِ شما میتواند بلوک حافظهٔ خطی را افزایش دهد. نکته: WebAssemble فقط چهار نوع داده دارد: i32، i64، f32، f64 برای اعداد صحیح 32 و 64 بیتی و انواع شمارههای شناور آیندهٔ توسعهٔ وب چگونه میشود؟ اگرچه ممکن است وباسمبلی، جاوا اسکریپت را از بین نبرد، اما قطعاً قصد این را دارد که چهرهٔ front-end توسعهٔ وب را تغییر دهد. البته راه بسیاری در پیش است تا همهٔ تغییرات را تجربه کنیم. اما به اندازهٔ کافی میتوان آیندهٔ وب را پیشبینی کنیم: تنوع از نظر زبانی خیلی سریع موازی تنوع زبانی این فناوری به طور چشمگیری تنوع در استفاده از زبانهای برنامهنویسی را برای ساخت برنامههای تحت وب افزایش میدهد. در حال حاضر لیست زیر زبانهایی است که وباسمبلی از آنها پشتیبانی میکند: C/C++ Rust C#/.Net Java Python Elixir Go سرعت و کارآیی بسیار بالا فناوری WASM باعث میشود عملکرد برنامهها شگفتانگیز شود. در این زمینه مستنداتی وجود دارد که فایرفاکس در یک سری از نمونههای اولیه آن را ثابت میکند. همچنین طبق تجزیه و تحلیل برنامههای کاربردی توسط فیگما منتشر شده است که نشان میدهد پیادهسازیهای صورت گرفت در قالب asm.js که خود از سرعت بسیاربالای به خاطر پشتیبانی از سی++ دارد، با این وجود با فعال بودن ماژول WebAssembly چیزی حدود ۳ برابر بهبود زمان اجرا گرفته است. در این موارد ثابت شده است که با استفاده از ++C و کامپایلر کلنگ (LLVM) سرعت اجرای برنامهها با فعال بودن وباسمبلی بسیار چشمگیر است. موازی سازی طبیعتاً این مورد بسیار قابل بررسی و توجه است، چرا که این مبحث به طور کامل در وِب پیادهسازی نشده است. از آنجایی که تغییر به سمت پردازندههای چند هستهای حدوداً از سال ۲۰۰۵ آغاز شد، این امر به طور فزایندهای اتفاق میافتد که برای دستیابی به عملکرد بیشتر، نرمافزارها به موازی سازی نیاز دارند. با توجه به اینکه جاوااسکریپت از سیستم موازی پشتیبانی نمیکند، تصور کنید که با فعالسازی WASM امکان استفاده از تمامی هستههای پردازنده فراهم شود. من به عنوان نویسندهٔ این مقاله، تصور شما را از این فناوری نمیدانم. اما قطعاً با این تفاسیر این فناوری به عنوان یک انقلاب بزرگ در حوزهٔ وِب محسوب میشود. با توجه به ساختار برنامههای نوشته شده توسط زبانهای قدرتمندی چون ++C میتوان تصور کرد که برنامههای بسیار بهینه و قدرتمندی را در حوزهٔ اجرایی مرورگرها پشتیبانی کند. در حال حاضر ممکن استد شما فکر کنید که چرا کسی باید زبان سادهای مثل جاوااسکریپت را خدشهدار کند و یا به سمت زبانهای پیچیدهای مانند Rust، C و ++C برود. اکنون وباسمبلی کاملاً جدید است و جامعهٔ کافی در اطراف خود ندارد. اما باید توجه داشت وقتی از طریق این فناوری میتوان به ویدئوها، تصاویر و کتابخانههای رمزنگاری، یا استفاده از موتورهای گرافیکی و فیزیکی که از OpenGL استفاده میکنند، و یا حتی کتابخانهها و فریمورکهای قدرتمندی مانند Qt و غیره را میتوان در حوزهٔ وب مورد استفاده قرار داد. بنابراین فناوری وباسمبلی میتواند مسیری را برای رشد صنایع مختلف به خصوص شرکتهای بازیسازی و غیره باز کند. افزایش کارآیی (پرفرمنس) بسیار شدید که توسط وباسمبلی فراهم میشود، همانند اجرای برنامههای دسکتاپی است که میتوان آن را بر روی وب نیز مشاهده کرد. با این روال ممکن است وباسمبلی در سالهای آینده، با نرمافزارهای رومیزیِ بومی برابری کند.
-
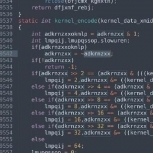
آغازی طوفانی برای پیاده سازی یک پیام رسان ساده بر پایه ++C
Max Base نوشته وبلاگ را ارسال کرد در برنامه نویسی
با سلام وقت بخیر, در این مطلب میخواهیم در مورد روش کارکرد پیام رسان ها بیشتر بدانیم و با یکدیگر کد یک پیام رسان ساده را پیاده و بررسی کنیم. طرز کار کرد پیام رسان در نظر داشته باشید که هر پیام رسانی که بر ساختار ها پیاده شده باشد از دو قسمت تشکیل شده است. نرم افزار اصلی برای مدیریت درخواست ها (سرور) نرم افزار برای کاربران (کاربر) به نرم افزار اولی سمت SERVER خواهیم گفت و به بعدی سمت CLIENT خواهیم گفت. روم یا تالار گفتگو ما تنها یک اتاق برای گفتگو در نظر میگیریم و هر کاربری که به سرور متصل شود را در همان تالار اضافه خواهیم کرد. تالار های گفتگو صرفا برای تقکیک سازی ارسال و دریافت ها و محدود کردن بازه ی کاربران مورد نظر... (ممکن است یک کاربر در چند اتاق بطور همزمان باشد.) سیستم های پیام رسان پیشرفته تر مانند تلگرام و ... تالار های زیادی را شامل می شوند. (هر کاربر خودش در کانال و گروه های مختلفی عضو است که هر کدام از آنها یک کانال متفاوت محسوب می شوند.) * دقت شود که منظور از کانال صرفا یک اتاق یا تالار گفتگو است و منظور کانال ارتباطی و پروتکل نیست. نرم افزار اصلی نرم افزار اصلی وظیفه دارد تا تمام کاربرانی که وارد تالار شده اند را به یاد داشته باشد و هر لحظه اماده دریافت درخواست هایی از طرف کاربرانش باشد. و پیام هایی را که از کاربران دریافت می کند برای تمامی کاربران دیگر هم ارسال کند که بسته به خلاقیت و نیاز می تواند هر یک از این بخش ها متفاوت طراحی شود. نرم افزار اصلی باید از قبل اجرا شده باشد. تا کاربران دیگر با استفاده از نرم افزار مخصوص به خودشان بتوانند به سرور متصل شوند و ارسال و دریافت داشته باشند. در نظر داشته باشید که اگر در نرم افزار اصلی اختلالی پیش بیایید و متوقف بشوند. قطا برای تمام کاربران مشکل پیش می آید. مگر اینکه از پایگاه های داده ی داخلی استفاده کرده باشند. (با خلاقیت می توان به گونه های متفاوتی چنین ساختاری را پیاده کرد) نرم افزار کاربران این نرم افزار جذاب ترین بخش است چرا تمام قابلیت هایی را که در اختیار کاربر قرار می دهیم را مستقیما طراحی می کنیم. در نظر داشته باشید که هر چیزی که در این نرم افزار طراحی می شود باید در نرم افزار اصلی پشتیبانی شوند... بنابراین اگر این دو بخش توسط دو فرد یا دو گروه مجزا طراحی می شوند آنها باید توسط داکیومنت ها و جلساتی به نظرات مشابه ای رسیده باشند. (اگرچه اینها تخصص و وظیفه ی تحلیلگر سیستم است! نه بطور همزمان وظیفه توسعه دهنده و برنامه نویس نرم افزار) پیاده سازی یک نمونه اکنون در نظر داریم تا با استفاده از ساختار کتابخانه BoostAsio پروژه ای را با نام BoostAsioChat ایجاد کنیم که در آن می خواهیم یک پیام رسان با حداقل ترین امکانات پایه طراحی کنیم که بیشتر جنبه شخصی و تفریحی دارد. زیرا از ساختار های استاندارد و ایمن و کاربری کاملا بدور است! (می توانید خودتان توسعه دهید و آنرا جالب تر بسازید) ساختار نرم افزار اصلی و سرور را به این صورت تعریف می کنیم : typedef deque<message> messageQueue; class participant { public: virtual ~participant() {} virtual void deliver(const message& messageItem) = 0; }; typedef shared_ptr<participant> participantPointer; class room { public: void join(participantPointer participant); void deliver(const message& messageItem); void leave(participantPointer participant); private: messageQueue messageRecents; enum { max = 200 }; set<participantPointer> participants; }; class session : public participant, public enable_shared_from_this<session> { public: session(tcp::socket socket, room& room) : socket(move(socket)), room_(room); void start(); void deliver(const message& messageItem); private: void readHeader(); void readBody(); void write(); tcp::socket socket; room& room_; message messageItem; messageQueue Messages; }; class server { public: server(boost::asio::io_context& io_context, const tcp::endpoint& endpoint) : acceptor(io_context, endpoint); private: void do_accept(); tcp::acceptor acceptor; room room_; }; int main(int argc, char* argv[]); ساختار نرم افزار کاربر را هم به این صورت تعریف می کنیم : typedef deque<message> messageQueue; class client { public: client(boost::asio::io_context& context, const tcp::resolver::results_type& endpoints) : context(context), socket(context); void write(const message& messageItem); void close(); private: void connect(const tcp::resolver::results_type& endpoints); void readHeader(); void readBody(); void write(); boost::asio::io_context& context; tcp::socket socket; message readMessage; messageQueue writeMessage; }; int main(int argc, char* argv[]); در نظر داریم تا در این پروژه از thread ها نیز استفاده کنیم... در مورد این مفهوم ها می توانید بصورت مجزا تحقیق کنید. بنابراین روش کامپایل این پروژه به این صورت خواهد بود : $ g++ client.cpp -lpthread -o client $ g++ Server.cpp -lpthread -o server آزمایش همانطور که گفته شد در ابتدا نرم افزار اصلی و سرور باید اجرا شود. در اینجا ما تمام ارتباطات شبکه را بر روی یک سیستم در شبکه داخلی برقرار خواهیم کرد... پس نگرانی در مورد ساختار های درونی شبکه و آی پی / دی ان اس / دامین نخواهیم داشت. بنابراین ای پی را می توانید ای پی داخلی یا localhost در نظر بگیرید. برای آزمایش پورت فرضی 4000 را در نظر میگیریم و نرم افزار اصلی را روی این پورت اجرا میکنیم : $ ./server 4000 در این مرحله متوجه می شوید که نرم افزار اصلی با موفقیت اجرا شده است و همچنان اجرا مانده است. بله درست است... نرم افزار اصلی هر لحظه باید منتظر دستور کاربران باشد. اگر لحظه ای برای نرم افزار اصلی اختلالی پیش آید نخواهد توانست دستورات کاربران را انجام یا پاسخ دهد. بنابراین این پردازش را قطع نکنید و اجازه دهید تا نرم افزار اصلی اجرا بماند. در محیط دیگری نرم افزار سمت کاربر را نیز اجرا کنید. این نرم افزار را می توانید به تعداد دلخواه وارد کنید. (همانطور که ممکن است 6 نفر همزمان به سرور متصل باشند / یا ممکن است هیچ فردی به سرور متصل نشوند) ابتدا یک کاربری را به سرور با پورت 4000 و شبکه داخلی وصل می کنیم : $ ./client localhost 4000 first user: you can type message here... حال در محیط دیگری با کاربر جدیدی نیز وارد می شویم : $ ./client localhost 4000 second user: you can type message here... در این پروژه نمونه از کاربران نام کاربری یا نام نمی پرسیم.. و صرفا وقتی وارد محیط گفتگو می شوند... یا زمانی که به سرور متصل می شوند منتظر هستیم تا انها پیامی را بنویسند... هر پیامی را که بنویسند به سرور ارسال می شود و سرور وظیفه دارد تا آنرا برای تمام کاربران بفرستد. و این روند درون یک حلقه بی نهایت تکرار می شوند. پس این ارتباط دو طرفه خواهد بود و هم کاربران برای سرور اطلاعات ارسال می کنند و هم سرور برای کاربران اطلاعات ارسال خواهد کرد. در نظر داشته باشید که کاربر اول می تواند پیامی را بنویسد و به کاربران دیگر ارسال شود. ممکن است کاربر سومی اصلا تصمیمی به نوشتن پیام نداشته باشد و صرفا تمایل به خواندن پیام دیگران داشته باشند. و این کاملا اختیاری است. و ما کاربران را اجباری نمیکنیم. اگرچه شما می توانید با خلاقیت خودتان اینها را با متغییر های کمکی و دستورات شرطی پیاده کنید. کد ها برای پیام ها یک ساختار در نظر میگیریم و بصورت مشترک در هر دو نرم افزار استفاده خواهیم کرد... بنابراین اینرا در هدر پیاده خواهیم کرد. هدر پیام : (message.hpp) #ifndef message_HPP #define message_HPP #include <cstdio> #include <cstdlib> #include <cstring> using namespace std; class message { public: enum { headerLength = 4 }; enum { maxBodyLength = 512 }; message() : bodyLength_(0) { } const char* data() const { return data_; } char* data() { return data_; } size_t length() const { return headerLength + bodyLength_; } const char* body() const { return data_ + headerLength; } char* body() { return data_ + headerLength; } size_t bodyLength() const { return bodyLength_; } void bodyLength(size_t new_length) { bodyLength_ = new_length; if(bodyLength_ > maxBodyLength) bodyLength_ = maxBodyLength; } bool decodeHeader() { char header[headerLength + 1] = ""; strncat(header, data_, headerLength); bodyLength_ = atoi(header); if(bodyLength_ > maxBodyLength) { bodyLength_ = 0; return false; } return true; } void encodeHeader() { char header[headerLength + 1] = ""; sprintf(header, "%4d", static_cast<int>(bodyLength_)); memcpy(data_, header, headerLength); } private: char data_[headerLength + maxBodyLength]; size_t bodyLength_; }; #endif نرم افزار اصلی و سرور : (server.cpp) #include <iostream> #include <cstdlib> #include <deque> #include <memory> #include <list> #include <set> #include <utility> #include <boost/asio.hpp> #include "message.hpp" using boost::asio::ip::tcp; using namespace std; typedef deque<message> messageQueue; class participant { public: virtual ~participant() {} virtual void deliver(const message& messageItem) = 0; }; typedef shared_ptr<participant> participantPointer; class room { public: void join(participantPointer participant) { participants.insert(participant); for(auto messageItem: messageRecents) participant->deliver(messageItem); } void deliver(const message& messageItem) { messageRecents.push_back(messageItem); while(messageRecents.size() > max) messageRecents.pop_front(); for(auto participant: participants) participant->deliver(messageItem); } void leave(participantPointer participant) { participants.erase(participant); } private: messageQueue messageRecents; enum { max = 200 }; set<participantPointer> participants; }; class session : public participant, public enable_shared_from_this<session> { public: session(tcp::socket socket, room& room) : socket(move(socket)), room_(room) { } void start() { room_.join(shared_from_this()); readHeader(); } void deliver(const message& messageItem) { bool write_in_progress = !Messages.empty(); Messages.push_back(messageItem); if(!write_in_progress) { write(); } } private: void readHeader() { auto self(shared_from_this()); boost::asio::async_read(socket, boost::asio::buffer(messageItem.data(), message::headerLength), [this, self](boost::system::error_code ec, size_t) { if(!ec && messageItem.decodeHeader()) { readBody(); } else { room_.leave(shared_from_this()); } }); } void readBody() { auto self(shared_from_this()); boost::asio::async_read(socket, boost::asio::buffer(messageItem.body(), messageItem.bodyLength()), [this, self](boost::system::error_code ec, size_t) { if(!ec) { room_.deliver(messageItem); readHeader(); } else { room_.leave(shared_from_this()); } }); } void write() { auto self(shared_from_this()); boost::asio::async_write(socket, boost::asio::buffer(Messages.front().data(), Messages.front().length()), [this, self](boost::system::error_code ec, size_t) { if(!ec) { Messages.pop_front(); if(!Messages.empty()) { write(); } } else { room_.leave(shared_from_this()); } }); } tcp::socket socket; room& room_; message messageItem; messageQueue Messages; }; class server { public: server(boost::asio::io_context& io_context, const tcp::endpoint& endpoint) : acceptor(io_context, endpoint) { do_accept(); } private: void do_accept() { acceptor.async_accept([this](boost::system::error_code ec, tcp::socket socket) { if(!ec) { make_shared<session>(move(socket), room_)->start(); } do_accept(); }); } tcp::acceptor acceptor; room room_; }; int main(int argc, char* argv[]) { try { if(argc < 2) { cerr << "Usage: server <port> [<port> ...]\n"; return 1; } boost::asio::io_context io_context; list<server> servers; for(int i = 1; i < argc; ++i) { tcp::endpoint endpoint(tcp::v4(), atoi(argv[i])); servers.emplace_back(io_context, endpoint); } io_context.run(); } catch (exception& e) { cerr << "Exception: " << e.what() << "\n"; } return 0; } نرم افزار دوم و سمت کاربر : (client.cpp) #include <iostream> #include <thread> #include <cstdlib> #include <deque> #include <boost/asio.hpp> #include "message.hpp" using boost::asio::ip::tcp; using namespace std; typedef deque<message> messageQueue; class client { public: client(boost::asio::io_context& context, const tcp::resolver::results_type& endpoints) : context(context), socket(context) { connect(endpoints); } void write(const message& messageItem) { boost::asio::post(context, [this, messageItem]() { bool write_in_progress = !writeMessage.empty(); writeMessage.push_back(messageItem); if(!write_in_progress) { write(); } }); } void close() { boost::asio::post(context, [this]() { socket.close(); }); } private: void connect(const tcp::resolver::results_type& endpoints) { boost::asio::async_connect(socket, endpoints, [this](boost::system::error_code ec, tcp::endpoint) { if(!ec) { readHeader(); } }); } void readHeader() { boost::asio::async_read(socket, boost::asio::buffer(readMessage.data(), message::headerLength), [this](boost::system::error_code ec, size_t) { if(!ec && readMessage.decodeHeader()) { readBody(); } else { socket.close(); } }); } void readBody() { boost::asio::async_read(socket, boost::asio::buffer(readMessage.body(), readMessage.bodyLength()), [this](boost::system::error_code ec, size_t) { if(!ec) { cout.write(readMessage.body(), readMessage.bodyLength()); cout << "\n"; readHeader(); } else { socket.close(); } }); } void write() { boost::asio::async_write(socket, boost::asio::buffer(writeMessage.front().data(), writeMessage.front().length()), [this](boost::system::error_code ec, size_t) { if(!ec) { writeMessage.pop_front(); if(!writeMessage.empty()) { write(); } } else { socket.close(); } }); } boost::asio::io_context& context; tcp::socket socket; message readMessage; messageQueue writeMessage; }; int main(int argc, char* argv[]) { try { if(argc != 3) { cerr << "Usage: client <host> <port>\n"; return 1; } boost::asio::io_context context; tcp::resolver resolver(context); auto endpoints = resolver.resolve(argv[1], argv[2]); client c(context, endpoints); thread t([&context](){ context.run(); }); char line[message::maxBodyLength + 1]; while(cin.getline(line, message::maxBodyLength + 1)) { message messageItem; messageItem.bodyLength(strlen(line)); memcpy(messageItem.body(), line, messageItem.bodyLength()); messageItem.encodeHeader(); c.write(messageItem); } c.close(); t.join(); } catch (exception& e) { cerr << "Exception: " << e.what() << "\n"; } return 0; } این پروژه آزمایشی بصورت رایگان و اوپن سورس در اینترنت بخصوص اینجا وجود دارد و می توانید آنرا مستقیما بصورت کامل دانلود کنید. با تشکر, Max Base / مکس بیس -
با سلام من میخوام چند فایلی که داخل فولدرم دارم رو تغییر نام بدم ، وقتی فایل ها زبانشون انگلیسی باشه مشکلی نیست قشنگ نامشون تغییر میده ولی وقتی به زبان های دیگه ای filename باشه درست تغییر نمیده ممنون میشم راهنمایی کنید . #include <iostream> #include <filesystem> #include <stdio.h> #include <windows.h> #include <thread> using namespace std; #ifdef _MSC_VER std::wstring ToUtf16(std::string str) { std::wstring ret; int len = MultiByteToWideChar(CP_UTF8, 0, str.c_str(), str.length(), NULL, 0); if (len > 0) { ret.resize(len); MultiByteToWideChar(CP_UTF8, 0, str.c_str(), str.length(), &ret[0], len); } return ret; } #endif int main() { const std::filesystem::directory_options options = ( std::filesystem::directory_options::follow_directory_symlink | std::filesystem::directory_options::skip_permission_denied ); try { for (const auto& dirEntry : std::filesystem::recursive_directory_iterator("C:\\folder", std::filesystem::directory_options(options))) { filesystem::path myfile(dirEntry.path().u8string()); string uft8path1 = dirEntry.path().u8string(); string uft8path3 = myfile.parent_path().u8string() + "/" + "renamed-" + myfile.filename().u8string(); _wrename( ToUtf16(uft8path1).c_str() , ToUtf16(uft8path3).c_str() ); std::cout << dirEntry.path().u8string() << std::endl; } } catch (std::filesystem::filesystem_error & fse) { std::cout << fse.what() << std::endl; } system("pause"); }
-
اولین پلتفرم آموزشی چند منظورهٔ بومی اگر شما به دنبال فراگیری مهارت خاصی در زندگی خود هستید، فانوکس بستر مناسبی برای شما است؛ نام فانوکس الهام گرفته از فانوس دریایی است که نماد پیدا کردن مسیر و نور راهنما تا رسیدن به مقصد میباشد. هدف : آموزش و یادگیری هوشمند در هر زمان و هر جا برای بهبود زندگی و کسب و کار این تاپیک برای این منظور ایجاد شده است که پروژه معرفی و بازخوردهای آن در این بخش اعلام و اصلاح شوند. بنابراین تمامی دوستان و علاقهمندانی که بازخوردهایی برای آن دارند میتوانند در این بخش آن را اعلام کنند تا به کمک هم آن را اصلاح و توسعه دهیم. نکته: نسخهٔ ریلیز شده ویژگی ثبت خطاها را دارد که به شما اجازه میدهد کد و پیغام خطا را کپی و در اختیار ما قرار دهید. بنابراین شرط جاری روی مُد User و فلگهای Info، Warning، Failed و Critical نیز تنظیم شدهاند که میتوانید در صورت مشاهده آنها را تقسیم بندی کنید. if(DeveloperMode::IsEnable) { Logger::LoggerModel = Logger::Mode::User; Log("Log Message : " + Event , LoggerType::Info); Log("Log Message : " + Event , LoggerType::Warning); Log("Log Message : " + Event , LoggerType::Failed); Log("Log Message : " + Event , LoggerType::Critical); } پیش اطلاعات فنی انجین : سِل Cell رابط کاربری: JavaScript، QML و فناوری Qt Quick کتابخانهها : STL, OpenSSL, Curl و Qt سمت سرور: Php7.2 و MySQLi MariaDB (در آینده همین بخش رو هم احتمالاً با ++C توسعه بدم). رابطهای برنامهنویسی: Restful Api v.1.0 در قالب JSon نسخهٔ فعلی: ۰.۵ آلفا پلتفرمهای پشتیبانی دسکتاپ : Windows, macOS, Linux پلتفرمهای پشتیبانی موبایل و تبلت : iOS, Android, iPadOS معرفی در آیاواستریم نسخهٔ فعلی توسعه یافته : ۰.۵.۳۴۳.۰ ریلیز شده در سه حالت Normal, OpenGLEs و Software Mode هدف از این روش ریلیز این هست که سیستمهایی که دارای کارت گرافیکی ضعیفتر و یا بدون نصب کارت گرافیک و درایور آن هستند را تحت پوشش دهیم، بنابراین نسخهٔ Software Mode تنها مناسب برای سیستمهای اداری و مشابه آن هستند که عموماً خبری از کارت گرافیکی و یا درایورهای نصب شده بر روی آنها نیست ? دوستان توجه داشته باشند که برای بازخوردها و اعلام نظرات توسعه حتماً از مُد اجرای برنامهٔ خودشون و نوع سیستمعامل و شرایط سختافزاریشون مطلع باشند تا بتونیم به درستی مشکلات احتمالی را حل کنیم. در ادامه بعد از نظر نسخهٔ آلفا شروع به بررسی و حل مشکلات احتمالی در مسیر توسعه خواهیم کرد.
-
ابزار Android NDK به عنوان مجموعهاز ابزارهایی است که به شما امکان آن را میدهد تا بخشی از برنامههای خود را به صورت بومی تحت زبان C و ++C توسعه دهید. بنابراین NDK از چندین کتابخانهی در زمان اجرای ++C پشتیبانی میکند؛ در این پست در رابطه با آخرین تغییرات مرتبط با NDK اطلاع رسانی میشود. public class MyActivity extends Activity { /** * Native method implemented in C/C++ */ public native void computeFoo(); } بر اساس آخرین تغییرات کتابخانههای استاندارد libstdc++ به libc++ بهروز رسانی و تمامی ویژگیهای استاندارد C++17 پشتیبانی میشود که از نسخهی R18 به بعد در دسترس قرار گرفته است. برخی از تغییرات مهم که لازم است به آنها توجه شود به صورت زیر میباشند: تغییرات اساسی از نسخهی NDK R17 آغاز شده است که در آن یکی از مهمترین و تکان دهندهترین تغیرات حذف GCC است که قرار بر این بود در نسخههای جدید NDK R18 پشتیبانی از GCC به صورت کامل حذف و Clang جایگزین آن شود. در نسخهی R18 پشتیبانی از gnustl, gabi++و stlport حذف شده است. پشتیبانی از ICS از اندرویدهای ۱۴ و ۱۵ به بعد حذف شده است. بر اساس قوانی جدید گوگل، بارگذاری اپلیکیشن از تاریخ آگوست ۲۰۱۹ به بعد در فروشگاه گوگل پلی (Play Store) نیازمند نسخهی معماری ۶۴ بیتی میباشد. پشتیبانی از C++17 در نسخهی R18 به بعد تایید نهایی و قابل استفاده شده است و همچنین در نسخههای R19 استفاده از تمامی استانداردهای منسوخ شده پیشنهاد نمیشود. کلمات کلیدی new و delete در استاندارد جدید ++C از نسخهی R18 منسوخ و در نسخهی R19 به طور کامل حذف خواهند شد. پشتیبانی از مدیریتهای استثناء (RTTI) در NDK به صورت پیشفرض غیر فعال میشود. مانند استثنائات، RTTI در libc++ پشتیبانی میشود، اما به صورت پیشفرض در android-build غیرفعال شده است که برای فعالسازی آن میتوانید از cmake و دیگر ابزارها استفاده کنید. هیچ محدودیتی در رابطه با هِدرهای سیپلاسپلاس در اندروید وجود ندارد. برای فعال سازی RTTI در برنامهی شما در ndk-build کد زیر را در application.mk اضافه کنید: APP_CPPFLAGS := -frtti همچنین برای فعال سازی آن برای یک ماژول خاص در ndk-build کد دستوری زیر را استفاده کنید: LOCAL_CPP_FEATURES := rtti روش دیگر به صورت زیر است: LOCAL_CPPFLAGS := -frtti نکته: تحت این سند ویژگیهای سیستمی STL در آینده حذف خواهند شد. توجه: libc++ یک کتابخانهی سیستمی نیست. در صورتی که از libc++_shared.so استفاده میکنید باید آن را در داخل فایل apk خود قرار دهید. در صورتی که از Gradle استفاده میکنید این کار به صورت خودکار انجام میشود.
-
نگارش 2.0.1
17 دریافت
QCustomPlot یک کتابخانه ویجت کیوت سی پلاس پلاس است که هیچ پیشنیاز بیشتری ندارد و به خوبی مستند شده است. این کتابخانه تمرکز بر انتشار گراف و نمودارهای دو بعدی سنگین دارد و با بهرهوری عالی خود انتخاب خوبی برای مجسمسازی بیدرنگ است. نگاهی به آموزش راه اندازی و آموزش مقدماتی نمودار بندازید.رایگان
-
با سلام. در حال یادگیرQt و Thread ها بودم که به مشکل دسترسی به متغیر در Thread بر خوردم. کلاس زیر از QThread مشتق شده است : #ifndef MYTHREAD_H #define MYTHREAD_H #include <QObject> #include <QWidget> #include <QThread> #include <QMutex> class MyThread : public QThread { Q_OBJECT public: explicit MyThread(QObject *parent = nullptr); void run() override; bool Stop; signals: void NumberChanged(int); }; #endif // MYTHREAD_H #include "mythread.h" MyThread::MyThread(QObject *parent) : QThread (parent) { } void MyThread::run() { for(int i=0; i<100000000 ; ++i){ QMutex mutex; mutex.lock(); if (this->Stop) break; mutex.unlock(); emit NumberChanged(i); this->msleep(100); } } داخل فرم خودم دو QPushBotton و یک QLabel دارم. که یکی از دکمهها (QPushButton) وظیفه اجرای یک QThread را دارد و یکی دیگه باعث متوقف کردن کار QThread ایجاد شده : #include "dialog.h" #include "ui_dialog.h" Dialog::Dialog(QWidget *parent) : QDialog(parent), ui(new Ui::Dialog){ ui->setupUi(this); mThread = new MyThread(this); connect(mThread,SIGNAL(NumberChanged(int)),this,SLOT(onNumberChanged (int))); } Dialog::~Dialog(){ delete ui; } void Dialog::onNumberChanged(int Number){ ui->label->setText(QString::number(Number)); } void Dialog::on_pushButton_clicked(){ mThread->start(); } void Dialog::on_pushButton_2_clicked(){ mThread->Stop = false; } در کد بالا زمانیکه on_pushButton_clicked فراخوانی شد. QThread را اجرا میکند. و در مقابل زمانیکه on_pushButton_2_clicked فراخوانی شد. متغیر bool MyThread::Stop را برابر مقدار false میگذارد که باعث از بین رفتن عملیات QThread ایجاد شده میشود. اما در اصل هیچ تفاوتی ایجاد نمیکند ؟ و زمان بستن برنامه با خطای لاگ زیر برخورد میکنم : 21:39:20: Starting /tmp/untitled/build-untitled-Desktop_Clang_7_0_0-Debug/untitled... QThread: Destroyed while thread is still running 21:39:32: The program has unexpectedly finished. 21:39:32: The process was ended forcefully. 21:39:32: /tmp/untitled/build-untitled-Desktop_Clang_7_0_0-Debug/untitled crashed. کجای کار اشتباه شده است ؟
-
با سلام. درحال بررسی کدهای کتابخانههای استاندارد سیپلاسپلاس بودم ، که متوجه موردی شدم ؛ تقریبا بیشتر توابع و کلاسهایی که از کتابخانههای استاندارد استفاده میکنیم دارای مقدار زیادی وابستگی به توابع و فایلهای دیگر دارند. برای مثال تابع std::swap که برای جابهجایی دو نوع استفاده میشود به اینصورت میباشد : template<typename _Tp, size_t _Nm> inline typename std::enable_if<__is_swappable<_Tp>::value>::type swap(_Tp (&__a)[_Nm], _Tp (&__b)[_Nm]) noexcept(std::__is_nothrow_swappable<_Tp>::value) { for (size_t __n = 0; __n < _Nm; ++__n) swap(__a[__n], __b[__n]); } که برای کامپایل نیاز به این موارد در دو فایل move.h و type_traits دارند : template<typename _Tp, _Tp __v> struct integral_constant { static constexpr _Tp value = __v; typedef _Tp value_type; typedef integral_constant<_Tp, __v> type; constexpr operator value_type() const noexcept { return value; } #if __cplusplus > 201103L #define __cpp_lib_integral_constant_callable 201304 constexpr value_type operator()() const noexcept { return value; } #endif }; template<bool __v> using __bool_constant = integral_constant<bool, __v>; typedef integral_constant<bool, true> true_type; typedef integral_constant<bool, false> false_type; template<bool, typename _Tp = void> struct enable_if { }; namespace __swappable_details { using std::swap; struct __do_is_swappable_impl { template<typename _Tp, typename = decltype(swap(std::declval<_Tp&>(), std::declval<_Tp&>()))> static true_type __test(int); template<typename> static false_type __test(...); }; struct __do_is_nothrow_swappable_impl { template<typename _Tp> static __bool_constant< noexcept(swap(std::declval<_Tp&>(), std::declval<_Tp&>())) > __test(int); template<typename> static false_type __test(...); }; } template<typename _Tp> struct __is_swappable_impl : public __swappable_details::__do_is_swappable_impl { typedef decltype(__test<_Tp>(0)) type; }; template<typename _Tp> struct __is_swappable : public __is_swappable_impl<_Tp>::type { }; template<typename _Tp> struct __is_nothrow_swappable_impl : public __swappable_details::__do_is_nothrow_swappable_impl { typedef decltype(__test<_Tp>(0)) type; }; template<typename _Tp> struct __is_nothrow_swappable : public __is_nothrow_swappable_impl<_Tp>::type { }; خب ! سوال اول بنده اینجاس که در چنین مواردی ، بهتر نیست که تابعstd::swap را با توجه به نیازی که داریم خودمان پیادهسازی کنیم ؟ و اینکه آیا این حجم از کد و استفاده از template ها هزینه پِرفُورْمَنْس زیادی ندارد ؟ و سوال دوم : تمام این کدها در دو فایل move.h و type_traits قرار دارد (که مسلماً این فایل ها هم وابستگیهای دیگری به دیگر فایلها دارند). آیا ما نمیتوانیم مثلا فقط تابع std::swap را در برنامهی خود فراخوانی کنیم که این حجم از کد احتیاج به کامپایل نداشته باشد ؟ برای نمونه در زبان برنامهنویسی پایتون ، با استفاده از دستور import ما یک ماژول را وارد برنامه میکنیم : import time در این روش تمام ماژول time به فایلما اضافه خواهند شد. درصورتی که ما فقط از ماژول time نیاز به تابع sleep داشته باشیم کافی است که از قابلت from ... import ... استفاده کنیم : from time import sleep آیا این حرکت در C++ نیز امکانپذیر هست ؟
-
با سلام ! آیا برنامه ها به صورت خودکار در حالت Multi Threading اجرا میشوند ؟ بنده قطعه کد زیر را کامپایل و اجرا گرفته ام : main.cpp #include <iostream> int main(void){ constexpr double long AnotherIndex = 999999999999999999; for(double long index=0;index <= AnotherIndex;++index){ std::cout << index << std::endl; } return 0x0000; } بعد از اجرا ، خروجی برنامه ی htop به اینصورت بود : 1 [|||||||||||||||||||||| 71.9% ] Tasks: 166, 738 thr; 4 running 2 [||||||||||||||||||| 60.30%] Load average: 2.94 1.88 1.61 3 [||||||||||||||||||||||| 74.1% ] Uptime: 04:50:24 4 [|||||||||||||||||| 56.6% ] Mem[||||||||||||||||||||||||2.76G/3.71G] Swp[||| 790M/7.99G] PID USER PRI NI VIRT PES SHR S CPU% MEM% TIME+ Command 18991 ghasem 20 0 5616 1692 1544 R 89.1 0.0 1:13.01 /tmp/Opt/main یعنی زمان اجرای این برنامه هر چهار هسته ی پردازنده درگیر خواهد شد ! ... آیا کامپایلر به صورت خودکار متناسب با پردازش Multi Threading کد را کامپایل میکند ؟ یا اینکه اینکار به عهده سیستم عامل میباشد ؟
-
با سلام. بنده خروجی کد اسمبلی تولید شده Struct و Class را بررسی کردم ظاهرا که خروجی یکسانی دارند ! آیا واقعا دیگر تفاوتی بین کلمهکلیدی struct و class در سیپلاسپلاس نیست ؟ struct.cpp struct AnotherType{ public : int StructType; }; int main(){ AnotherType Object; return 0; } class.cpp class AnotherType{ public : int ClassType; }; int main(){ AnotherType Object; return 0; } و خروجی های اسمبلی تولید شده : struct.cpp [ghasem@clibcore test]$ g++ -S struct.cpp -o Struct && cat Struct .file "struct.cpp" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (GNU) 8.2.1 20181105 (Red Hat 8.2.1-5)" .section .note.GNU-stack,"",@progbits class.cpp [ghasem@clibcore test]$ g++ -S class.cpp -o Class && cat Class .file "class.cpp" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (GNU) 8.2.1 20181105 (Red Hat 8.2.1-5)" .section .note.GNU-stack,"",@progbits و برای اطمینان خروجی حاصل از دستور diff Struct Class : [ghasem@clibcore test]$ diff Struct Class 1c1 < .file "struct.cpp" --- > .file "class.cpp"
-
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #e62f3d; color: #ffffff;" >برنامه نویسی در C و ++C</span>
مراحل ساخت برنامه در زبان سیپلاسپلاس پیش نویس ۰.۶ قبل از هر چیز به اینفوگرافی زیر توجه کنید که مراحل ساخت برنامه در سیپلاسپلاس را نشان میدهد. مقدمهای بر همگردانی (کامپایل) و اتصال (لینک کردن) این سند مرور مختصری در رابطه با مراحل را برای شما فراهم میکند تا به شما در درک دستورات مختلف برای تبدیل و اجرای برنامهٔ خودتان کمک کند. تبدیل مجموعهای از فایلهای منبع و هدر در سیپلاسپلاس به یک فایل خروجی و اجرایی در چندین گام (به طور معمول در چهار گام) پیشپردازنده (Preprocessors)، کامپایل و گردآوری (Compilation)، اسمبلر (Assmbler) و پیوند دهنده (Linker) تقسیم میشود. قبل از هر چیز اگر در محیط توسعهٔ Qt Creator داخل فایل .pro مقدار زیر را وارد کنید، تا بتوانید فایلهای ساخته شدهٔ موقت در زمان کامپایل را مشاهده کنید. QMAKE_CXXFLAGS += -save-temps این دستور اجازهٔ آن را خواهد داد تا فایلهایی با پسوند .ii و .s در شاخهٔ بیلد پروژه تولید شوند که در ادامه به آنها اشاره شده است. تعریف پیشپردازنده پیشپردازندهها (Preprocessors) درواقع دستوراتی هستند که اجازه میدهند تا کامپایلر قبل از آغاز کردن مراحل کامپایل دستوراتی را دریافت کند. پیشپردازندهها توسط هشتگ (#) مشخص میشوند این نماد در سی++ مشخص میکند که دستور فوق از نوع پیشپردازنده میباشد که نتیجهٔ آن در قالب ماکرو (Macro) در دسترس خواهد بود. برای مثال ماکروی __DATE__ توسط پیشپردازندهها از قبل تعریف شده است که مقدار تاریخ و زمان را بازگشت میدهد. بنابراین هرکجا که از آن استفاده شود کامپایلر آن را جایگزین متن خواهد کرد. در شکل زیر مرحلهای که از پیشپردازندهها استفاده میشود آمده است: پیشپردازنده، کامپایل (گردآوری کردن)، لینک (پیوند کردن) و ساخت برنامه اجرایی فرایند تبدیل مجموعهای از فایلهای متنی هِدر و سورس سی++ را «ساخت» یا همان Building میگویند. از آنجایی که ممکن است کُد پروژه در بسیاری از فایلها هدر و سورس سی++ توسعه و گسترش یابدمراحل ساخت در چند گام کوچک صورت میگیرد. یکی از رایجترین موارد در مراحل گردآوری (ترجمهٔ یک کد سیپلاسپلاس به دستورالعملهای قابل فهم ماشین) است. اما گامهای دیگری نیز وجود دارد، پیشپردازنده و لینک (پیوندها) این بخش به طور خلاصه توضیح میدهد که چه اتفاقی در هر یک از مراحل رُخ میدهد. یک کامپایلر یک برنامهٔ خاص است که پردازش اظهارات (دستورات) نوشته شده در یک زبان برنامهنویسی خاص را به یک زبان ماشین که قابل فهم برای پردازنده میباشد تبدیل کند. به طور معمول یک برنامهنویس با استفاده از یک ویرایشگر که به محیط توسعهٔ یکپارچهٔ نرمافزار (IDE) مشهور است توسط زبان برنامهنویسی مانند ++C دستورات (اظهارات) را مینویسد. فایل ایجاد شده با نام (filename.cpp در زبان برنامهنویسی سیپلاسپلاس) شامل محتوایی است که معمولاً به عنوان دستورات برنامهنویسی سطح بالا نامیده میشود. سپس برنامهنویس کامپایلرِ مناسب برای زبان برنامهنویسی مانند سی++ را اجرا میکند و نام فایلهایی که حاوی دستورات هستند را برای کامپایل مشخص میکند که این انتخاب و مشخص سازی توسط IDE به راحتی قابل مدیریت است. پس از آن، کار کامپایلر این است که فایلهای منبع .cpp را جمع آوری کرده و پیشپردازندهها را بررسی کند تا دستورات احتمالی را اجرا نماید که نتیجهٔ این مرحله در فایلی با پسوند .ii ر قالب filename.ii تولید میشود که در این فرایند نیز خط به خط کُدهای موجود در آنها را بررسی میکند تا خطاهای احتمالی نحو (سینتکس - Syntax) بررسی میشود و آنها را به طور ترتیبی به دستورالعملهای سطح ماشین تبدیل کند. توجه داشته باشید که هر نوع پردازندهٔ کامپیوتر دارای مجموعهای از دستورالعملهایِ ماشین خودش است. بنابراین کامپایلر تنها برای سی++ نیست، بلکه برای اهداف و مقاصد خاص هر پلتفرم است. پس کدهایی که توسط پیشپردازنده سیپلاسپلاس به زبان اسمبلی برای معماری مورد نظر در پلتفرم مقصدترجمه شدهاند نتایج آن در فایلی با پسوند .ss در قالب filename.ss قابل نمایش هستند که در حالت عادی قابل رویت نیست. توجه داشته باشید که باید در این مرحله باید مشخص شود برنامه قرار است توسط چه نوع پردازندهای تحتِ چه نوع معماری مونتاژ (اسمبل) شود. برای مثال پردازندهها با انواع معماریهای مختلف وجود دارند که برخی از آنها به صورت x86-x64، x64، ARMv7، aarch64 غیره ... میباشند. شکل یک (کامپایل یک فایل منبع ++C) مرحلهٔ سوم را در نظر داشته باشید که عمل کامپایل فایل سیپلاسپلاس در دو مرحله قبلی یک فایل اجرایی را تولید نمیکند. برنامهای که توصیف شده است، احتمالاً توابعی را در رابطهای برنامهنویسی (API) و یا توابع ریاضی یا توابع مرتبط با I/O را فراخوانی کند که ممکن است شامل فایلهای هدر مانند iostream یا fstream و حتی ماژولهای دیگری که در زبان تعبیه شدهاند را داشته باشد که فایل تولید شده توسط کامپایلر در این مرحله یک فایل شیء نامیده میشود که با پسوند .o به صورت filename.o تولید خواهد شد که علاوه بر دستورالعملهای تبدیل شده به کد ماشین، شامل توابع و دستورالعملهای خارجی نیز میباشد. هرچند در این مرحله دستورات تبدیل به دستورالعملهای قابل فهم توسط پردازنده شدهاند اما فعلاً قابل اجرا نیستند چرا که باید این توابع خارجی افزوده شده را به آن لینک کرد که در مرحلهٔ بعد یعنی مرحلهٔ چهارم اتفاق میافتد. در نهایت مرحلهٔ چهارم فایل با پسوند .o که شامل کدهای تولید شده توسط کامپایلر به زبان ماشین است که پردازندهها میتوانند این دستورات را درک کنند که همراه با کدهای تولید شدهٔ هر کتابخانهٔ دیگری که مورد نیاز است توسط لینکر (لینک شده) و در نهایت جهت تولید یک فایل اجرایی مورد استفاده قرار میگیرند که نوع آن فایل از نوع اجرایی یا در واقع Executable File خواهد بود. شرح کامل فرایند ساخت فایل اجرایی اکثر پروژهها دارای مجموعهای از فایلهای هدر سی++ هستند، که امکان ماژولار شدن در آن را فراهم میکند و مجموعهای از آن میتواند به عنوان بخشهای کوچکی از برنامه محسوب شوند. برای ساخت چنین پروژههایی هر فایل سیپلاسپلاس باید کامپایل شود و سپس فایلهای ساخته شده در قالب شیء (آبجکت) باید همراه توابع و کتابخانههای دیگر لینک (پیوند) شوند. البته هر گام از مراحل کامپایل شامل یک مرحله پیشپردازنده است که دستورالعمل # عمل تغییرات و اصلاحیهها را در فایل متن اعمال میکند. شکل زیر فرایند ساخت چند فایل به صورت همزمان را نشان میدهد: در ادامهٔ این مقاله، مطلبی مرتبط با تنظیمات بیشتر از کامپایلر آمده است که میتوانید آن را مورد مطالعه قرار دهید. -
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #e62f3d; color: #ffffff;" >برنامه نویسی در C و ++C</span>
با توجه به وجود کتابخانههای متعدد در سیپلاسپلاس در این پُست قصد داریم آموزشهایی در رابطه با نحوهٔ راه اندازی انواع کتابخانهها را در سیپلاسپلاس توضیح دهیم. محیطهای توسعه جهت نصب Visual Studio و Qt Creator خواهند بود. در صورتی که نیاز است کتابخانهای را به صورت سفارشی کامپایل کنید نکاتی را باید مورد توجه قرار دهید که در ادامه آمدهاند. قبل از هر چیز نیاز است توضیحاتی در رابطه با انواع کتابخانهها داده شود. کتابخانهها برای اینکه در پروژه مورد استفاده قرار بگیرند نیاز است آنها از سمت منبع خود کامپایل و ساخته شوند. البته در این فرآیند باید توجه داشته باشید که نوع معماری در پیکربندی یک کتابخانه بسیار مهم است. برای مثال اگر قرار است کتابخانهای را بر روی یک پروژهای که تحت معماری x64 پیکربندی شده است و در وضعیت release منتشر شود، در این صورت حتماً باید کتابخانه مورد نظر تحت همین پیکربندی کامپایل شود. کتابخانهها ممکن است خودشان وابستهٔ کتابخانههای دیگری باشند. برای مثال بخشی از ماژول کتابخانه Boost و Poco وابستهٔ کتابخانهٔ OpenSSL میباشد. و یا بخشی از کتابخانهٔ MySQL وابستهٔ کتابخانهٔ Boost میباشد. بنابراین قبل از پیکربندی پروژه تحت هر کتابخانهای مطمئن شوید که پیش نیازات آن را در اختیار داشته باشید. توجه داشته باشید که حتماً راهنمای کتابخانهٔ مورد نظر خود را جهت نحوهٔ پیکربندی مطالعه نمایید، زیرا هیچ روش عامیانهای وجود ندارد که بر روی تمامی کتابخانهها صادق باشد. با توجه به نکات بالا آموزش لازم جهت پیکربندی و راه اندازی کتابخانهها را تحت دو گزینهٔ Boost و MFSL ادامه میدهیم: نسخهٔ مورد نظر کتابخانهٔ مورد نظر را از این بخش دریافت کنید. فایل دریافت شده را استخراج و در یک مسیر مشخصی مانند C://کتابخانهٔ شماکپی کنید. محیط کنسول در سیستم عامل را باز کنید، پیشنهاد میشود از Visual Studio Cross Tools Command Prompt استفاده کنید. به مسیر کتابخانه تحت دستور cd رفته و وارد آن شوید. در این مرحله نیاز است تا قبل از ساخت کتابخانه آن را پیکربندی کنید، بنابراین دستور زیر را اجرا خواهیم کرد: ./configure دقت کنید که این مرحله معمولاً در کتابخانهها متفاوت میباشد، برای مثال در کتابخانهٔ Boost فایلی به نام bootstrap.bat متخص ویندوز و فایل bootstrap.sh برای محیطهای یونیکس موجود است که وظیفهٔ پیکربندی و تولید فایل ساخت را بر عهده دارد. البته در نظر داشته باشید که این چنین پیکربندی در کتابخانههای خاص ممکن است و در بیشتر آنها باید با دستورات configure و فلگهای موجود در هر یک از آنها اقدام به پیکربندی کنید. بنابراین با توجه این مورد میتوانید آموزش لازم را در این بخش پیگیری نمایید. بعد از پیکربندی دستور make، nmake، cmake و یا qmake متناسب با نوع ابزار سازنده باید اجرا شود تا کتابخانه بر اساس پیکربندی تنظیم شده شروع به کامپایل و ساخت کند. این مرحله معمولاً بر اساس قدرت پردازشی سیستم شما زمان متغیری خواهد داشت. بعد از به اتمام رسیدن زمان کامپایل کتابخانهٔ مورد نظر فایلهای lib را تحت پسوندهای .dll در ویندوز و .lib و .so در لینوکس و یونیکس تولید خواهد کرد که بهتر است مسیر include برای هدرهای کتابخانه و lib برای فایلهای کامپایل شده مشخص شود. طبق شرایط ذکر شده برای مثال ما از کتابخانهٔ SDL در این بخش استفاده خواهیم کرد. نسخهٔ از پیش کامپایل شده مربوط به آن را از این بخش دریافت و استخراج نمایید. قست اول (نصب و راه اندازی تحت محیط Visual Studio) وارد محیط ویژوال استودیو شده و بعد از ایجاد پروژه بر روی پروژه راست کلیک و گزینهٔ Properties را انتخاب کنید، به زبانه C/C++ رفته و زبانه General گزینهٔ Additional Include Directories را انتخاب کنید. در ادامه مسیر include را از کتابخانهٔ SDL به پروژه معرفی کنید. مرحله کنونی را تایید کنید، و به زبانهٔ Linker و سپس General بروید، در این بخش گزینهٔ Additional Linker Library را انتخاب و مسیر Lib را از کتابخانهٔ SDL معرفی کنید. در این مرحله فایلهای کتابخانه معرفی شدهاند. به زبانهٔ General و Input برگشته و در بخش Additional Dependences فایلهای SDL2.lib و SDL2_image.lib و SDL2main.lib و SDL2_ttf.lib را معرفی کنید. در نهایت فایلهای dll موجود در پوشهٔ lib کتابخانه را در کنار فایل اجرایی کپی کنید. قست دوم (نصب و راه اندازی تحت محیط Qt Creator) پروژه خود را ایجاد و بر روی نام پروژه راست کلیک کنید. گزینهٔ Add Library و سپس External Library را بزنید. طبق شرایط قبل گزینههای lib را همراه با include به پروژهٔ خود اضافه نمایید. کد مربوط به فایل .pro به صورت زیر خواهد بود win32: LIBS += -L$$PWD/../../../../SDL2-2.0.8/lib/x86/ -lSDL2 -lSDL2main -lSDL2_ttf INCLUDEPATH += $$PWD/../../../../SDL2-2.0.8/lib/x86 DEPENDPATH += $$PWD/../../../../SDL2-2.0.8/lib/x86 طبق روش کامپایل برنامه را کامپایل کنید و قبل از اجرا فایلهای dll یا lib را نسبت به پلتفرم خود در کنار فایل اجرایی پروژه قرار دهید. https://iostream.ir/forums/topic/33-روش-افزودن-کتابخانههای-دیگر-به-محیط-qt-creator/ روش فوق در بیشتر کتابخانهها قابل انجام است. -
همانطور که میدانید کتابخانهی بوست یکی از بهترین کتابخانههای Non-STL برای سیپلاسپلاس میباشد. در این پُست قصد داریم در رابطه با ساخت و استفاده کتابخانهی بوست توضیح دهیم. ابتدا کتابخانه را از اینجا دریافت کنید. فایلهای دریافتی را در یک مسیر مشخص استخراج کنید. راه اندازی در پلتفرم ویندوز برای مثال در این آموزش ما فایلهای مورد نظر خود را در مسیر C:/Boost استخراج کردهایم. در کنسول به مسیر فوق رفته و دستور زیر را اجرا کنید. bootstrap.bat این دستور تحت ابزار مخصوص بوست فایل کانفیگ ساخت آن را ارزیابی و اجرا میکند. بنابراین دستور بعدی به صورت زیر خواهد بود: b2 toolset=msvc-14.0 --build-type=complete --abbreviate-paths architecture=x86 address-model=64 install -j4 گزینهی toolset برای مشخص کردن کامپایلر و نسخهی آن میباشد که در اینجا آن را msvc-14.0 قرار داده ایم. گزینهی architecture جهت مشخص کردن معماری پردازنده است که به صورت پیش فرض بهتر است بر روی x86 تنظیم شود تا بر روی هر دو معماری ۶۴ و ۳۲ بیتی اجرا شود. گزینهی address-model جهت مشخص سازی نوع پردازندهای که پلتفرم اجرایی دارا میباشد را مشخص میسازد. برای مثال ما بر روی ویندوز ۶۴ بیتی و پردازنده ۶۴ بیتی گزینه x64 را انتخاب کرده ایم. گزینهی -j برای مشخص کردن تعداد هستههای قابل استفاده در زمان کامپایل میباشد. که به صورت پیشفرض بر روی ۴ تنظیم شده است (۴ هسته قابل اجرا به صورت هم زمان). بعد از اجرای دستور فوق چیزی حدود ۳۰ دقیقه (کمتر و یا بیشتر) متناسب با قدرت پردازشی سیستم شما نیاز خواهد بود تا کتابخانهی بوست کامپایل شود. توجه داشته باشید که بخشی از کتابخانههای موجود در بوست به صورت پیش فرض کامپایل نمیشوند و در صورت نیاز شما باید آنها را به صورت سفارشی تحت دستور --with-libraryname مشخص نمایید. کد زیر را اجرا نموده و نتیجه را مشاهده کنید: #include <boost/scoped_ptr.hpp> #include <iostream> int main() { boost::scoped_ptr<int> p{new int{1}}; std::cout << *p << '\n'; p.reset(new int{2}); std::cout << *p.get() << '\n'; p.reset(); std::cout << std::boolalpha << static_cast<bool>(p) << '\n'; } این آموزش برای پیکربندی کتابخانههای chrono, thread, filesystem, regex و...بر روی پلتفرمهای macOS و Linux ادامه خواهد داشت...
-
خلاصه تعریفی از زبان برنامه نویسی سیپلاسپلاس (++C) با توجه به پیشرفت و توسعهٔ زبانهای برنامهنویسی، به ویژه ظهور زبانهای جدید که جهت حل مشکلات زبانهای موجود و یا با هدف ایجاد انقلاب و یا سهولت برنامهنویسی، یکی از سوألاتی که مدام به ذهن میآید این است که چه زبانی را باید انتخاب کرد که از لحاظ بُعد علمی، اقتصادی و فنی بهترین انتخاب باشد تا با یک خیال راحت به یادگیری آن بپردازیم. در این مقاله به مزایای این زبان نسبت به دیگر زبانها و همچنین چشماندازی از آیندهٔ زبان اشاره شده است؛ سیپلاسپلاس به عنوان قدرتمندترین زبان برنامهنویسی تا به کنون است که به جرأت میتوان گفت به عنوان یک زبان برنامهنویسیِ غالب بر دیگر زبانهای برنامهنویسی لقب «هیولای زبانهای برنامهنویسی» را به خود اختصاص میدهد. با توجه به ساختار و نقشهٔ راه توسعهٔ خود، هنوز هم به عنوان یکی از پر طرفدارترین و پر کاربردترین زبانهای برنامهنویسی ساخت دست بشر به شمار میرود. آیا تا به حال فکر کردهاید که یک جهان پیشرفتهٔ متکی به فناوری امروز، وابستهٔ چه چیزهایی است و موتور نامرئی آن چیست؟ اخیراً دانشمند بزرگ، همچنین سازندهٔ زبان سی++ «بیارنه استراس تروپ» در یک سخنرانی ۱ دقیقهای به معرفی موتور نامرئی جهان پرداخته است که در این لینک میتوانید از زبان او بشنوید. سیپلاسپلاس با قابلیتهای انواع داده ایستا، نوشتار آزاد، چندمدلی، معمولاً زبان ترجمه شده با پشتیبانی از برنامهنویسی ساختیافته، برنامهنویسی شیءگرا، برنامهنویسی جنریک است. C++ به همراه جد خود C از پرطرفدارترین زبانهای برنامهنویسی تجاری هستند بنا بر این در زیر فلسفهای از این زبان را بیان می کنیم: زبان ++C طراحی شدهاست تا یک زبان عمومی با کنترل نوع ایستا و همانند C قابل حمل و پربازده باشد. زبان ++C طراحی شدهاست تا مستقیماً و بصورت جامع از چندین شیوه برنامهنویسی (برنامهنویسی ساختیافته، برنامهنویسی شیگرا، انتزاع داده، و برنامهنویسی جنریک) زبان ++C طراحی شده است تا به برنامهنویس امکان انتخاب دهد حتی اگر این انتخاب اشتباه باشد. زبان ++C طراحی شده است تا حداکثر تطابق با C وجود داشته باشد و یک انتقال راحت از C را ممکن سازد. زبان ++C از بکاربردن ویژگیهای خاص که مانع از عمومی شدن است خودداری مینماید. زبان ++C از ویژگیهایی که بکار برده نمیشوند استفاده نمیکند. زبان ++C طراحی شدهاست تا بدون یک محیط پیچیده عمل نماید. زبان ++C مورد انتخاب برای ساخت نرمافزارهایی با کارآیی بالا است که به طور «مستقیم» به منابع یا تجهیزات و ابزارهای سیستمعامل دسترسی دارند. بنابراین علاوه بر ویژگی سطحِ بالای این زبان شما را قادر میسازد تا به سطوح پایینتر از یک سیستمعامل دسترسی داشته باشید و این امر موجب میشود از قدرت بسیار بالایی در برنامهنویسی بهره ببرید ، لذا در مقایسه با سایر زبانهای برنامهنویسی شما باید از جزئیات بیشتری اطلاع داشته باشید تا بتوانید برنامهٔ فوق حرفهای خود را تولید کنید. کتابخانهها چه چیزی هستند و در این زبان چگونه است؟ به مجموعههای یکپارچهای از کلاسهای پیاده سازی شده (به صورت فایلهای سرآیند با پیاده سازیهای کد یا اشیای زبان ماشین) که برای برنامهنویسی به کار میروند، یک کتابخانه C++ گفته میشود و یکی از ویژگیهای بارز آن تولید و دسترسی به کتابخانههای بیشمار است. لیستی از این کتابخانههای همراه با توضیحات در لینک زیر آمده است : A list of open source C++ libraries - cppreference.com لیست کامل انواع کامپایلرها : List of compilers - Wikipedia ویژگیهای جدید در ویرایش ۱۱، ۱۴، ۱۷ و ۲۰ چیست؟ زبان C++11 (معروف به C++0x) یک نسخه استاندارد از زبان ++C است که در ۱۲ آگوست ۲۰۱۱ منتشر و توسط ISO جایگزین C++03 شد این نسخه دارای نشان ISO/IEC 14882:2011 می باشد و در تاریخ ۱۸ آگوست ۲۰۱۴ نسخه جدید آن یعنی C++14 منتشر و جایگزین C++11 شد. امکانات اضافه شده به هسته C++ : یکی از وظایف کمیته استاندارد سازی توسعه هسته زبان است.در توسعه فعلی چندین بخش از زبان بهبود یافته که شامل چندنخی (multithreading) ، پشتیبانی از برنامهنویسی عمومی، مقدار دهی اولیه یکنواخت و پیشرفت عملکرد میباشد. ویژگیهای هسته زبان و تغییرات آن به چهار بخش کلی دسته بندی شداند: 1. پیشرفت در عملکرد زمان اجرا (Run-Time) 2. پیشرفت در عملکرد زمان ساخت (Build-Time) 3. پیشرفت در ویژگی ها (قابلیت استفاده) 4. و قابلیت های جدید ویرایش C++ 14 بر روی اشکالزدائی و بهبودهای جزیی استاندارد قبلی یعنی C++11 تمرکز کرده است؛ این زبان در تاریخ ۱۵ می ۲۰۱۳ منتشر و در ۱۵ آگوست ۲۰۱۴ بعد از رای گیری و انجام تغییراتی جزئی استاندارد این زبان منتشر شد. بدلیل این که عموماً تاریخ انتشار این زبان بطور قابل ملاحظهای دیر هنگام بوده است به C++14 گاهی C++1y نیز گفته میشود. همانند استاندارد C++11 که به آن C++0x گفته میشده و قرار بر این بوده که قبل از ۲۰۱۰ منتشر شود (البته تا سال ۲۰۱۱ انتشار به تعویق افتاد). گرچه تمامی کامپایلرها درحال کاربروی C++14 هستند اما هنوز تمامی آن ها از C++14 پشتیبانی نمیکنند. در C++11 و C++14 توابع جدیدی به هسته اصلی زبان و کتابخانه استاندارد آن اضافه شده است که شامل بسیاری از کتابخانههای C++TR1 به استثنای کتابخانهٔ توابع ریاضی ویژه میباشد. ویژگیهای اضافه شده کتابخانه در ویرایش ۱۱ std::move std::forward std::to_string type traits smart pointers std::chrono tuples std::tie std::array unordered containers std::make_shared memory model ویژگیهای اضافه شده به زبان در ویرایش ۱۱ move semantics variadic templates rvalue references initializer lists static assertions auto lambda expressions decltype template aliases nullptr strongly-typed enums attributes constexpr delegating constructors user-defined literals explicit virtual overrides final specifier default functions deleted functions range-based for loops special member functions for move semantics converting constructors explicit conversion functions inline-namespaces non-static data member initializers right angle brackets ویژگیهای اضافه شده به کتابخانه در ویرایش ۱۴ user-defined literals for standard library types compile-time integer sequences std::make_unique ویژگیهای اضافه شده به زبان در ویرایش ۱۴ binary literals generic lambda expressions lambda capture initializers return type deduction decltype(auto) relaxing constraints on constexpr functions variable templates ویژکیهای اضافه شده به کتابخانه در ویرایش ۱۷ std::variant std::optional std::any std::string_view std::invoke std::apply splicing for maps and sets ویژگیهای اضافه شده به زبان در ویرایش ۱۷ template argument deduction for class templates declaring non-type template parameters with auto folding expressions new rules for auto deduction from braced-init-list constexpr lambda lambda capture this by value inline variables nested namespaces structured bindings selection statements with initializer constexpr if utf-8 character literals direct-list-initialization of enums ویژگیهای اضافه شده به زبان در ویرایش ۲۰ concepts designated initializers (based on the C99 feature) [=, this] as a lambda capture template parameter lists on lambdas three-way comparison using the "spaceship operator", operator <=> initialization of an additional variable within a range-based for statement lambdas in unevaluated contexts default constructible and assignable stateless lambdas allow pack expansions in lambda init-capture string literals as template parameters atomic smart pointers (such as std::atomic<shared_ptr<T>> and std::atomic<weak_ptr<T>>) removing the need for typename in certain circumstances new standard attributes [[no_unique_address]] [[likely]] and [[unlikely]] calendar and time-zone additions to <chrono> std::span, providing a view to a contiguous array (analogous to std::string_view but span can mutate the referenced sequence) <version> header feature test macros bit-casting of object representations, with less verbosity than memcpy() and more ability to exploit compiler internals conditional explicit, allowing the explicit modifier to be contingent on a boolean expression constexpr virtual functions ranges (The One Ranges Proposal) concept terse syntax constexpr union, try and catch dynamic_cast and typeid, std::pointer_traits various constexpr library bits immediate functions using the new consteval keyword signed integers are now defined to be represented using two's complement (signed integer overflow remains undefined behavior) a revised memory model coroutines – already experimentally supported in Clang 5 modules – experimentally supported in Clang 5 and Visual Studio 2015 Update 1 as well as GCC various improvements to structured bindings (interaction with lambda captures, static and thread_local storage duration) contracts have been removed (see list of features deferred to a later standard) use of comma operator in subscript expressions has been deprecated constexpr additions (trivial default initialization, unevaluated inline-assembly) using scoped enums various changes to the spaceship-operator DR: minor changes to modules constinit keyword changes to concepts (removal of -> Type return-type-requirements) (most of) volatile has been deprecated DR: [[nodiscard]] effects on constructors The new standard library concepts will not use PascalCase (rather standard_case, as rest of standard library) text formatting (chrono integration, corner case fixes) bit operations constexpr INVOKE math constants consistency additions to atomics (std::atomic_ref<T>, std::atomic<std::shared_ptr<T>>) add the spaceship (<=>) operator to the standard library header units for the standard library synchronization facilities (merged from: Efficient atomic waiting and semaphores, latches and barriers, Improving atomic_flag, Don't Make C++ Unimplementable On Small CPUs) std::source_location constexpr containers (std::string, std::vector) std::stop_token and joining thread (std::jthread) Many new keywords added (and the new "spaceship operator", operator <=>), such as concept, constinit, consteval, co_await, co_return, co_yield, requires (plus changed meaning for export), and char8_t. And explicit can take an expression since C++20. (Most of) the use for the volatile keyword has been deprecated. C++ has added a number of attributes over the years, including new in C++20, [[likely]] and [[unlikely]]; and [[no_unique_address]]. etc... کتابخانههای استاندارد چیست و در نسخههای جدید چگونه در دسترس هستند؟ در زبان برنامهنویسی ++C کتابخانهٔ استاندارد سی++ مجموعهای از کلاسها و رویهها است که در هسته زبان نوشته شدهاند و قسمتی از استاندارد ISO سی++ میباشند. در سال ۱۹۹۸ استاندارد ++C شامل دو بخش هسته زبان و کتابخانه استاندارد ++C است. این کتابخانه شامل بیشتر بخشهای STL و کتابخانه استاندارد C است. بیشتر کتابخانههای ++C در استاندارد وجود ندارند و یا استفاده از تعریف قابلیت پیوند کتابخانهها را میتوان در زبانهایی مانند فرترن، C، پاسکال، بیسیک نوشته شوند. البته با توجه به ویژگیهای کامپایلر مشخص خواهد شد که کدام زبان را میتوان استفاده نمود. کتابخانهٔ استاندارد ++C شامل کتابخانه استاندارد C با یک سری تغییرات برای بهبود عملکرد است. بخش بزرگ بعدی این کتابخانه STL است. STL شامل ابزار بسیار قدرتمندی مانند نگهدارندهها (مانند vector و list)، تکرارکنندهها (اشارهگرهای عمومی شده) برای شبیهسازی دسترسی مانند آرایه الگوریتمهایی برای جستجو و مرتبسازی در آنها وجود دارند. نقشهها (نقشههای چندگانه) (آرایه شرکتپذیر) و مجموعهها (مجموعههای چندگانه) واسطهای عمومی فراهم میسازند. در نتیجه با استفاده از قالب تابع، الگوریتمهای جنریک با هر نگهدارنده و دارای تکرارکننده عمل نماید. همانند C ویژگیهای کتابخانه را میتوان با استفاده از شبه دستور include# شامل یک سرآیند استاندارد اضافه نمود. C دارای ۶۹ کتابخانه استاندارد است که ۱۹ تا از آنها نامناسب تشخیص داده شدهاند. استفاده از کتابخانهٔ استاندارد - مانندstd::vector یا std::string به جای آرایههای C موجب ایجاد برنامههای مطمئن تر شده است. STL در آغاز محصولی جداگانه از HP و سپس SGL پیش از ادغام در کتابخانه استاندارد ++C بودهاست. استاندارد عبارت STL را بکار نمیبرد بلکه آن را بخشی از کتابخانه میداند اما مردم هنوز هم آن را برای جداسازی بخشهای مختلف کتابخانه با این نام بکار میبرند. (جریانهای ورودی/خروجی، جهانیسازی، تشخیص، زیرمجموعه کتابخانه C) بیشتر کامپایلرها کتابخانه استاندارد و STL را پیادهسازی مینماید. پیادهسازیهای مستقلی نیز همانند STLport نیر وجود دارند. پروژههای دیگر نیز پیادهسازیهای خود را از STL با توجه به اهداف خود بوجود میآورند. روش جدیدی جناب بیجارن در نظر گرفته که کتابخانه های استاندارد ++C علاوه بر اینکه توسط خود کامپایلرها در دسترس و قابل استفاده هستش بلکه توسط کتابخانه STL و Boost نیز می توان دسترسی به مجموع عظیمی از کتابخانه ها استاندارد ISO داشت. ساختار فایلها در این زبان چگونه است؟ در رابطه با ساختار برنامه های نوشته شده توسط ++C بدانید که منظور از ساختار در اینجا انواع فایل های موجود در زبان سیپلاسپلاس است، در این رابطه باید اینگونه اشاره کنیم که در این زبان ما می توانیم از فایل های زیر برای برنامه نویسی استفاده کنیم. فایل با پسوند .c این فایل منبعی برای کد هایی از نوع زبان C هستند. فایل با پسوند .c++ منبعی برای کد هایی از نوع زبان C و ++C هستند ضعف این نوع فایل در قابل حمل نبودن و عدم شناسایی توسط فایل سیستم ها می باشد. فایل با پسوند .cxx منبعی برای کد هایی از نوع زبان C و ++C هستند با تفاوت اینکه نسبت به فایل .c++ قابل حمل تر است. فایل با پسوند .cpp منبعی برای کد هایی از نوع زبان C و ++C هستند یعنی در هر دو نیز قابل استفاده می باشند. این پسوند با تمامی سیستم ها سازگاری دارد و بسیار رایج است. فایل با پسوند .hxx معمولا فایل با عنوان (هدر/سرصفحه) یاد می شوند و معمولا فقط حاوی اعلان ها میباشند. فایل با پسوند .hpp معمولا فایل با عنوان (هدر/سرصفحه) یاد می شوند و معمولا فقط حاوی اعلان ها میباشند. این فرمت توسط مارس دیجیتال استفاده می شود. همچنین بورلند و دیگر کامپایلر های سی++ از آن پشتیبانی میکنند. ممکن است در این فایل متغیر ها، ثوابت و توایعی که در فایل منبع اصلی به آن ها اشاره شده است اعلام شود. فایل با پسوند .h معمولا فایل با عنوان (هدر/سر صفحه) یاد میشوند و معمولا فقط حاوی اعلان ها میباشند این نوع بسیار رایج است و تقریبا با تمامی سیستم ها سازگاری دارد. فایل با پسوند .hh در این زبان: فایل با عنوان (هدر/سر صفحه) یاد می شوند و معمولا فقط حاوی اعلان ها میباشند. فایل با پسوند .h++ در این زبان: این نوع فایل ها معمولا فایل با عنوان (هدر/سرصفحه) یاد میشوند و معمولاً فقط حاوی اعلان ها میباشند. ضعف این نوع فایل در قابل حمل نبودن و عدم شناسایی توسط فایل سیستم ها میباشد. فایل با پسوند .ixx در استانداردهای جدید جهت تعریف سند ماژول (اختصاصاً برای کامپایلرهای MSVC) معرفی شده است. همچنین فایل با پسوندهای cppm، ccm، mxx، cxxm و c++m به عنوان پسوندهای جدیدی در رابطه با خاصیت ماژول از استانداردهای جدید برای کامپایلرهای مدرن هستند. یک فایل سرآیند با پسوند (.h, .hpp و ...) میتواند شامل محتوای زیر باشد: تعریف کلاس تعریف توابع درون خطی (Inline) اعلام تابع اعلام شیء مثال: #ifndef CPPFILES_H #define CPPFILES_H extern int status; class CPPFiles { public: CPPFiles(); void myFunction(); inline int safe(int i); }; #endif // CPPFILES_H یک فایل منبع - سورس با پسوند (.c, .hpp، .cxx و ...) میتواند شامل محتوای زیر باشد: تعریف کلاس تعریف توابع اعلام شیء مثال : #include "cppfiles.h" int status = 1; CPPFiles::CPPFiles() { } void CPPFiles::myFunction() { //Do somthing... } int CPPFiles::safe(/*@Param*/) { return /*Somthing...*/; } انواع فایل هایی که به آنها اشاره شد بسیار است ولی متناسب با محبویت و پشتیبانی کامپایلر ها از این فایل ها در این زبان برای انتخاب آنها مهم است بنا بر این در طی آموزش و تمامی مراحل ما فقط از فایل های .h برای هدر و فایل های .cpp برای منابع استفاده خواهیم کرد. چرا و چه زمانی باید از فایل های hpp. و چه زمانی از فایل های cpp. استفاده کنیم؟ توجه داشته باشید که سیپلاسپلاس از تمامی پسوند فایلهای مذکور پشتیبانی میکند، معمولاً استفاده از فایلهای hpp و h جهت اعلان و تعریفهای اولیهٔ کدها مناسب است و در زمان تعریف کامل عملکرد کد مورد نظر فایل با پسوند cpp پیشنهاد میشود. هرچند استفادهٔ غیر استاندارد نیز پشتیبانی میشود اما باید توجه داشت جهت حفظ ساختار استاندارد روشهای اصولی منطقی و صحیح هستند. کاربرد این زبان در کجاست؟ معمولاً تمامی برنامهها و نرمافزارهایی که به صورت روزمره در زندگی مدرن امروزی مشاهده میکنیم بدون شک توسط زبان های اساسی نوشته شدهاند. به عنوان مثال انواع صنایع موجود در کشورها از قبیل صنعت خودروسازی، صنعت فضایی، سیستمهای معماری و بانکی ، تجهیزات مدرن و سختافزارهای رباتیک، سیستمهای کامپیوتری و یا کنسول هایبازی ، سیستمهای خانگی و یا هوش مصنوعی، تجهیزات مجهز به انواع حسگرها، پزشکی، فضایی، زبانهای برنامهنویسی، سیستمعاملها و بسیاری از موارد دیگری که میتوان نام برد بدون شک توسط این زبان پیاده سازی شدهاند. چگونه C++ میتواند در لایه های زیرین (سطح پایین) و بالا (سطح بالا) مورد استفاده قرار بگیرد؟ به نقل از سازندهٔ آن، این زبان هر دو ویژگی سطح بالا و سطح پایین را ارائه میکند. سیپلاسپلاس دارای بخشهای سطح پایین است، مانند اشارهگرها، آرایهها و کستها. این ویژگیها تقریباً مشابه همان ویژگی C هستند که ارائه شده است و برای کار با کارهای سختافزاری ضروری هستند. بنابراین اگر میخواهید به امکانات سطح پایین زبان دسترسی داشته باشید، بله سیپلاسپلاس مجموعهای از این امکانات را در اختیار شما قرار میدهد. با این حال، اگر نمیخواهید از ویژگیهای سطح پایین استفاده کنید، نیازی به استفاده از آنها به صورت مستقیم در این زبان نیست. در عوض میتوانید از امکانات سطح بالا از جمله کتابخانههای آن را مورد استفاده قرار دهید. به عنوان مثال اگر نمیخواهید از اشارهگرها و آرایهها استفاده کنید میتوانید از رشتهها و نگهدارندههای استاندارد استفاده کنید که به مراتب گزینههای بهتری هستند. آیا سیستم عامل ها و نرم افزار های مطرح دنیا توسط این زبان نوشته شده اند؟ دلیل آن چیست؟ همانگونه که مشخص است بسیاری از سیستم عامل ها از ابتدا توسط خانواده اسمبل ، C نوشته شده اند که به صورت زیر به تعدادی از آن ها اشاره میکنیم: DragonFlyBSD,FreeBSD,OpenBSD,NetBSD HP-UX Centos,Debian,Fedora,OpenSUSE,RedHat,Ubuntu OSX,iOS,Darwin OracleSolaris,OpenIndiana Cygwin Android Windows Phone BlackBerry WindowsXP,Vista,7,8,10 دلیل آن که از زبان هایی مانند C و ++C برای نوشتن سیستمعامل استفاده میشود قابلیت های مهم آن است به عنوان مثال: کارآیی بالا ، مستقل از سکو، زبان پاسه و غالب بودن و عدم وابستگی آن به زبان های دیگر، ارتباط با سختافزار و تمامی دیوایسها، مدیریت هوشمندانه و همچنین برنامهنویسی آزادانه ، دسترسی به لیست عظیمی از کتابخانهها که میتوان توسط آن ها هر چیزی را که در رویاهای خود به آن فکر میکنید در واقعیت خلق کنید. انواع سخت افزارهایی که این زبان پشتیبانی میکند: زبان برنامهنویسی سیپلاسپلاس با استفاده از کامپایلرهای قدرتمندی چون GCC، Clang و غیره، طیف گستردهای از سختافزارها و معماریها را پشتیبانی میکند. مدل ماشین هایی که پشتیبانی میشود : PowerPC , Oracle,Fujitsu,Sun, IBM,Freescale , AMD,Intel مدل پردازندهها: Athlon,Atom,Core,Core2,Corei3/i5/i7,Opteron,Pentium,Phenom,Sempron,Turion,etc Itanium,Itanium2,Itanium29000/9100/9300,etc PowerPC,POWER1/2/3/4/5/6/7,G1,G2,G3,G4,G5,etc UltraSPARCI/II/III/IV/T1/T2,SPARCT3/T4,etc کاربرد این زبان در زمینه وب چگونه است؟ در این زمینه معمولاً به دلیل وجود چهارچوبها و زبانهای سادهتری نسبت به سی++ در حوزهٔ وب مانند Php و غیره...، معمولاً فرصت نشده است تا به شناخت کتابخانهها و مزایای این زبان در این حوزه پرداخته شود. با توجه به توسعههای اخیر صنعت وب دانشمندان به این نتیجه رسیدهاند که جهت افزایش کارایی در زمینهٔ وب و از بین بردن محدودیتهای وابسته به مرورگرهای اینترنتی، از فناوریهای بهتری مانند wasm نیز پرده برداری شود که در این فناوری سی++ گزینهٔ پشت پردهای از این فناوری محسوب میشود که اجازه میدهد با اجرای کدها و دسترسی به رابطهای برنامهنویسی پیشرفته یک دنیای جدیدی از فناوری وب را ارائه کند. این فناوری با عنوان Web Assembly شناخته میشود که اجازه میدهد برنامههای نوشته شده توسط سی++ در مرورگر به عنوان یک پلتفرم جدید اجرا شوند. البته این تنها روش نیست، سی++ به لطف کتابخانههای عظیم خودش قادر است هر چیزی را در اختیار برنامهنویس قرار دهد. به عنوان مثال دسترسی به کتابخانههای عظیم Qt، Wt این امکان را فراهم میکنند که به راحتی یک سیستم ابر پیشرفتهٔ تحت وب را به کمک این زبان پیاده سازی کنید که هیچ نوع سیستم موجود در وب قابل رقابت و مقایسه با ویژگیها و نتایج خارقالعادهٔ آن نخواهد داشت. در مثال زیر یک سیستم مدیریت محتوا به صورت آزمایشی پیاده سازی شده است که میتوانید نتایج خارقالعادهٔ آن را مشاهده کنید. همچنین توجه کنید که این تنها کاربرد سی++ در وب نیست، حقیقت آن است که وبسایتهای بزرگی همچون فیسبوک، گوگل و غیره هستهٔ وبسایتهای خود را توسط این زبان توسعه دادهاند که دلایل آنها مصرف بهینهٔ تجهیزان سختافزاری و دسترسی به ویژگیهای سیستمی بسیار زیاد و امنیت بسیار بالا است. احتمالاً در رابطه با موتور قدرتمند v8 Engine شنیدهاید، این یک موتور اساسی برای محصولات گوگل است که کاملاً تحت سی++ توسعه یافته است. برخی از محیطهای برنامهنویسی مانند Node.JS تحت آن قدرت گرفتهاند. برخی از محصولات اساسی و معروف که بخش عمده و یا به صورت کامل توسط سیپلاسپلاس نوشته شدهاند (این لیست تنها شامل برجستهترین محصولات است) : سیستمعاملها ویندوز مکینتاش لینوکس آیاواس اندروید مرورگرها اُپرا فایرفاکس گوگل کروم مایکروسافت اِدج اپل سافاری نرمافزارهای کاربردی و مهندسی تمامی محصولات قدرتمند Adobe مانند فوتوشاپ، افترافکت و غیره... تمامی محصولات Autodesk مانند Maya، 3dsMax و Autocad مجازیسازها مانند Virtual Box و VMware محصولات مایکروسافت مانند Visual Studio و Office محصولات اپل مانند iTunes، Xcode و غیره... بازیها و صنایع مرتبط توسعهٔ کنسولهای بازی Playstation و Xbox اکثر بازیهای خارقالعاده در سطح AAA پیامرسانها تلگرام اسکایپ موتورهای دیتابیس مانند MySQL و غیره... کتابخانهها و ابزارهای پیشرفتهٔ توسعه ابزارهای مرتبط با فناوریهای روز مانند Blockchain و غیره... زبانهای برنامهنویسی مانند Swift و غیره... راهاندازها و ابزارهای قدرتمند AMD، Intel و NVIDIA Geforce و پلتفرمهایی مانند Cuda. و هزاران و میلیونها ابزار و برنامههایی که در زندگی روزمره با آنها سرو کار داریم. اشاره ای بر انواع موتور های دیتابیس که توسط ++C پشتیبانی میشوند : SQL NoSQL SQLite MySQL Sybase Adaptive Server SQL Server Oracle PostgreSQL IBASE : Borland IBM DB2 متأسفانه به دلیل عدم اطلاع و شناخت کافی از حقایق این زبان، توصیه برای یادگیری زبانهایی مانند Java و #C و مشابه آنها ممکن است بر اساس علاقههای فردی و تعصب باشد. بنابراین توصیه میشود حتماً در مورد تفاوتهای ساختاری و مزایای زبانها حتماً تحقیق شود. چگونه باید طراحی رابط کاربری را انجام دهیم؟ برای طراحی رابط گرافیکی ابتدا باید ذهن خود را از محیط VS و همچنین کنسول کنار بکشید لذا برای این کار کتابخانه های مخصوصی در نظر گرفته شده است به صورت زیر: FLTK nana WxWidgets OWLNext GTK+ glibmm gtkmm goocanvasmm libglademm libgnomecanvasmm webkitgtk flowcanvas evince Qt libdbusmenu-qt توسط این کتابخانه های میتوان محیطهای کاربری را فراهم ساخت. در این میان دو کتابخانهٔ wxWidgets و Qt بسیار قدرتمند عمل کردهاند که بین این دو نیز Qt با قدرت بسیار زیادی از رقیب خود یعنی wxWidgets پیشی گرفته است و معمولاً پروژههایی که در آن رابطکاربری خلاقانه (Creative) و مدرن مطرح است حرف از Qt به گوش میرسد (کیوت یک چهارچوب جامع جهت طراحی رابطهای کاربری قدرتمند است). پیشنهادات ما استفاده از مقالات خارجی و منابع رسمی میباشد: http://en.cppreference.com/w Learn C++ https://www.learn-cpp.org Learn C++ (Introduction and Tutorials to C++ Programming) http://www.cplusplus.com نگاهی به کاربرد این زبان در بین فناوریهای جدید! سیپلاسپلاس همچنین به عنوان یکی از قدرتمندترین و محبوبترین زبانهای برنامهنویسی در دنیای فناوری شناخته میشود و در صنعت بلاکچین نیز یک قدرت غالب است. زبان شیءگرایی برای توسعه بلاکچین مناسب است، زیرا از همان اصول کپسولهسازی، انتزاع، چندریختی و مخفی کردن دادهها استفاده میکند. به عنوان مثال بلاکچین از ویرایشهای ناخواسته از دادهها جولوگیری میکند که به عنوان یکی از چهار زبان برنامهنویسی آینده دار میتوان به آن اشاره کرد. همچنین توجه داشته باشید که فناوریهای دیگری مانند مباحث Cross-Platform و رشد بسیار شدید فناوری IoT این زبان به عنوان یک زبان پیشتاز در این حوزه است که در کنار بسیاری از کاربردهای اساسی خود میتوان به عنوان یک ابزار اساسی و کاربردی به آن در آیندهای که از همین حالا شروع شده است اشاره داشت. آیا با ++C میتوان برنامههای موبایلی مانند Android , iOS و غیره را تولید کرد؟ پاسخ، بله! متأسفانه این مورد هم مانند حوزهٔ وب به خاطر عدم شناخت و تبلیغات کافی از ذهن بسیاری از افراد به یک گزینهٔ بی اهمیت تبدیل شده است، اما با توجه به رشد روز افزون و ایجاد ابزارهای ضعیف، نیاز به شناخت این زبان و ابزارهای واقعی و قدرتمند آن الزامی شده است. برای مثال در حوزهٔ موبایل ابزارهایی مانند Xamarin و یا Flutter این روزها سرو صدای بسیاری کردهاند، اما واقعیت این است، آنها هیچگاه نتیجهٔ واقعی و مشابه به زبانهای پیشفرض پلتفرمهای توسعه را ندارند و نخواهند داشت. فناوری چند-سکویی به معنای واقعی تنها در ابزارهایی مانند Qt Framework و سی++ خلاصه میشود که به شما اجازهٔ تولید و توسعهٔ کدهای خود را به صورت بومی در پلتفرم هدف فراهم میکند. پیشنهاد ما در رابطه نحوه شروع برای یادگیری و آشنایی با زبان و انواع کتابخانه ها به صورت زیر است: قبل از هر چیز هدف خود را در رابطه با منابع مشخص نمایید، اگر زبان انگلیسی شما خوب است میتوانید در همین قدم اول از منابع رسمی و استاندارد که بی نقص هستند استفاده کنید. سعی کنید اگر قرار است این زبان را یاد بگیرید عملا با آن درگیر شوید. از مقدمات برنامه نویسی شروع کنید و حتما در رابطه با تاریخچه زبان و اهداف آن تحقیق کنید. شرکت و سازمان های بزرگ و موفق را الگو قرار دهید. اگر هدف شما سریع رسیدن به پول بدون در نظر داشتن کیفیت و اهداف بزرگ از پروژه هستش به هیچ عنوان سراغ این زبان نروید زیرا C++ برنامه نویس مشتاق به حرفهای شدن را میطلبد نه برنامهنویس راحت طلب. حتماً سیپلاسپلاس مدرن را بیآموزید. استانداردهای مدرن شامل نسخههای ۱۱، ۱۴، ۱۷ و ۲۰ هستند. برای استفاده و کار با کتابخانههای این زبان بهتر است کتابخانههای پیشفرض STL را به خوبی یاد بگیرید. برای توسعه هرچه بیشتر پروژه و استفاده از انواع قابلیتها توسط این زبان میبایست از کتابخانههای دیگر استفاده کنیم که در این میان در رابطه با بخش طراحی و رابط کاربریQt، GTK, MFC, SDL , wxWidgetsمناسب است که پیشنهاد ما در میان این لیست (Qt) خواهد بود که تحت آن میتوان مدرنترین طراحی ها را خلق نمود. برای کار با شبکه کتابخانههای Curl, Poco, Qt, RakNet, ReplicaNet, SDL موجود هستند و در بین اینها Curl بهترین گزینه میتواند باشد. برای کار با 3D بعدی کتابخانه مخصوص OpenGL یا باز همان Qt را که بر پایه موتور OpenGL است پیشنهاد میکنیم و یا میتوانید از کتابخانه های مخصوص DirectX و OpenGL و حتی نسخههای توسعهٔافته به نام Vulkan را به صورت تخصصی استفاده یاد بگیرید. در رابطه با 2D نیز از OpenGL، Direct2D, GDI و GDI+ میتوان استفاده کرد. در مورد Sound از کتابخانه های مطرح OpenAL, Fmod و Bass استفاده کنید. در مورد بحث فیزیک کتابخانه های Nvidia Physix, Nvidia Apex, Bullet, Box2D, ODE, Open Dynamics در رابطه با هوش مصنوعی کتابخانه های OpenAI, FEAR, OpenSteer, PathLib مطرح هستند. برای کار با پردازش تصویری OpenCV, OpenNI پیشنهاد میشود. برای کار با پردازش موازی OpenCL, OpenML, CUDA مناسب است. برای اسکریپت نویسی Lua, LuaPlus, Phyton برای کار با ورودی ها از OpenInput, Qt, SDL, SFML میتوان استفاده کرد. برای بازی سازی کتابخانه های Unreal Engine, OGRE, Irrlicht, KGE مناسب هستند که در بین اینها Unreal Engine بسیار قدرتمند عمل میکند. برای طراحی و اجرای وب سایت کتابخانه های WebKit, ClearSilver, Teng مناسب هستند. برای توسعهٔ ابزارهای مرتبط با فناوری بلاکچین، میتوان به کتابخانههای قدرتمند و خارقالعادهای به نام EOS اشاره کرد. لازم بذکر است اینها نمونهای از کتابخانههای بیشمار سی++ هستند و میتوان به کتابخانههای بسیاری اشاره کرد که خارج از گنجایش این مقاله است. منابع فارسی برای یادگیری سیپلاسپلاس مدرن چیست؟ متأسفانه منابع فارسی برای این زبان معمولاً متعلق به مباحث دانشگاهی و مفاهیم مرتبط به سیپلاسپلاس سنتی است (مربوط به ۳۰ سال پیش)! یادگیری این مباحث هیچ مزیتی برای شما نخواهد داشت و به شدت پیشنهاد میشود جهت یادگیری این زبان حتماً به سراغ آموزشهای مدرن بروید. تنها بسترهای آموزشی مربوط به سیپلاسپلاس جدید در ایران (به زبان فارسی) مرجع آیاواستریم است.






