

















قسمت اول معماری CPP: مبحث Overloading و Name Mangling و Template و Auto
هنگامیکه شما برای اولین بار از C به CPP مهاجرت می کنید، یا اصلا برنامه نویسی را قصد دارید با CPP شروع کنید، با مفاهیم متعددی روبرو خواهید شد که شاید برای شما جالب باشند که بدانید، این ایده ها چطور شکل گرفتند، چطور به CPP افزوده شدند و اهمیت آن ها در عمل (هنگام برنامه نویسی و توسعه نرم افزار) چیست. در این پست وبلاگی IOStream، به این خواهیم پرداخت که ایده Overloading و Template و Auto Deduction چطور از CPP سر در آوردند.
همانطور که شما ممکن است تجربه کرده باشید، هنگامیکه برنامه نویسی و توسعه نرم افزاری را با C شروع می کنید، برنامه شما چیزی بیش از یک مجموعه بی انتها از توابع و استراکچرها و متغیرها و اشاره گرها و ... نخواهند بود.
از همین روی شما مجبور هستید مبتنی بر ایده مهندسی نرم افزار و پارادیم برنامه نویسی ساخت یافته، برای هر کاری یک تابع منحصربفرد پیاده سازی کنید. این تابع باید از هر لحاظی از قبیل نام، نوع ورودی ها، نوع خروجی و حتی نوع عملکرد منحصربفرد باشد تا بتواند یک کار را به شکل صحیح کنترل کند که همین مسئله می تواند در پیاده سازی برخی نرم افزارها، انسان را در جهنم داغ و سوزان قرار بدهد. مثلا پیاده سازی یک برنامه محاسباتی مانند ماشین حساب که ممکن است با انواع داده های محاسباتی مانند عدد صحیح (Integer) و عدد اعشاری (Float) رو به رو شود.
از همین روی فرض کنید، ما قرار است یک عمل محاسباتی مانند جمع از برنامه ماشین حساب را پیاده سازی کنیم. برای اینکه برنامه به شکل صحیحی کار کند، باید عمل جمع یا همان Add برای انواع داده های موجود از قبیل عدد صحیح و اعشاری پیاده سازی شود. اگر شما این کار را انجام ندهید، برنامه شما به شکل صحیحی کار نخواهد کرد (یعنی نتایج اشتباه ممکن است برای ما تولید کند). در تصویر زیر، نمونه این برنامه و توابع مرتبط با آن پیاده سازی شده است:
#include <stdio.h>
int AddInt(int arg_a, int arg_b)
{
return arg_a + arg_b;
}
float AddFloat(float arg_a, float arg_b)
{
return arg_a + arg_b;
}
double AddDouble(double arg_a, double arg_b)
{
return arg_a + arg_b;
}
int main(int argc, const char* argv[])
{
int result_int = AddInt(1, 2);
float result_float = AddFloat(10.02f, 21.23f);
double result_double = AddDouble(9.0, 24.3);
printf("Result Integer: %d", result_int);
printf("Result Float: %f", result_float);
printf("Result Double: %lf", result_double);
return 0;
}
به برنامه بالا دقت کنید. ما سه تا تابع Add با نام های منحصربفرد داریم که سه نوع داده مجزا را به عنوان ورودی دریافت می کنند، سه نوع نتیجه مجزا بازگشت می دهند، اگرچه پیاده سازی آن ها کاملا مشابه هم دیگر است و تفاوتی در پیاده سازی این سه تابع وجود ندارد.
ولی به هر صورت، اگر به خروجی دیزاسمبلی برنامه مشاهده کنید، دلیل این مسئله را متوجه خواهید شد که چرا هنگام برنامه نویسی با زبان C، به نام های منحصربفرد نیاز است، چون اگر توابع نام های مشابه با هم داشته باشند، لینکر نمی تواند به دلیل تداخل نام (Name Conflict)، آدرس آن ها را محاسبه یا اصطلاحا Resolve کند.
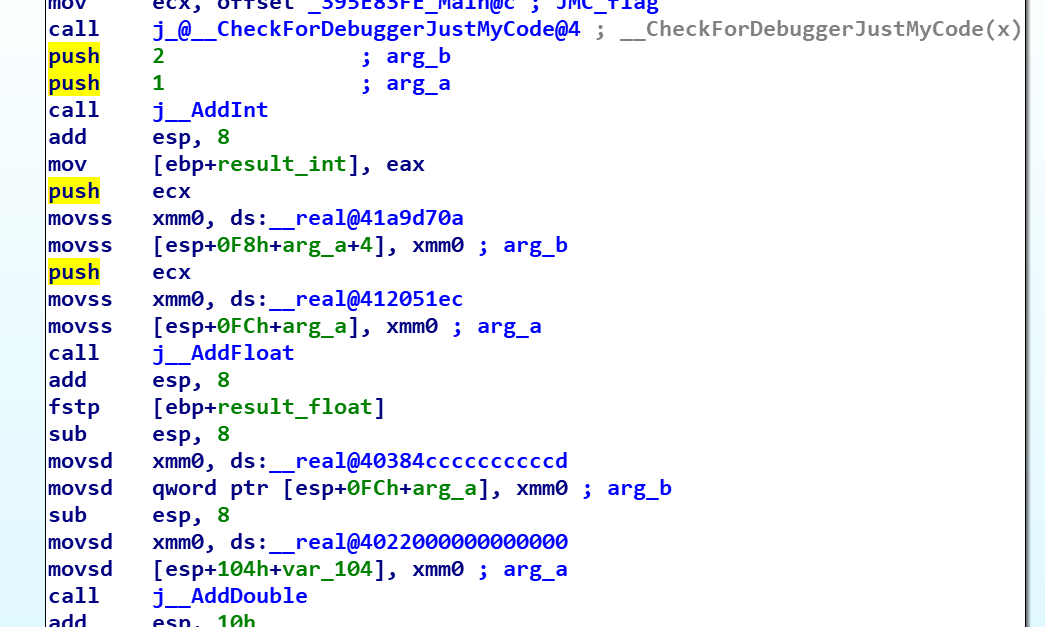
همانطور که در تصویر بالا خروجی دیزاسمبلی برنامه Add را مشاهده می کنید، اگر توابع نام مشابه داشتند، در هنگام فراخوانی (Call) تابع Add تداخل رخ می داد، چون دینامیک لودر سیستم عامل دقیقا نمی داند که کدام تابع را باید فراخوانی کند. برای همین نیاز است وقتی برنامه نوشته می شود، نام توابع در سطح کدهای اسمبلی و ماشین منحصر بفرد باشد.
به هر صورت، به نظر شما آیا راهی وجود دارد که ما پیاده سازی این نوع توابع را ساده تر کنیم یا حداقل بار نامگذاری آن ها را از روی دوش توسعه دهنده و برنامه نویس برداریم؟ بله امکان این کار وجود دارد. مهندسان CPP با افزودن ویژگی Overloading و Name Mangling یا همان بحث Decoration مشکل برنامه نویسان در پیاده سازی توابع با نام های منحصربفرد را حل کردند (البته کاربردهای دیگر هم دارد که فعلا برای بحث ما اهمیت ندارند).
ویژگی اورلودینگ در CPP به ما اجازه خواهد داد یک تابع با عنوان Add پیاده سازی کنیم که تفاوت آن ها فقط در نوع ورودی و نوع خروجی است. به عنوان مثال، در قسمت زیر، کد برنامه Add را مشاهده می کنید که با قواعد CPP بازنویسی شده است.
#include <iostream>
int Add(int arg_a, int arg_b)
{
return arg_a + arg_b;
}
float Add(float arg_a, float arg_b)
{
return arg_a + arg_b;
}
double Add(double arg_a, double arg_b)
{
return arg_a + arg_b;
}
int main(int argc, const char* argv[])
{
int result_int = Add(1, 2);
float result_float = Add(10.02f, 21.23f);
double result_double = Add(9.0, 24.3);
std::cout << "Result Integer: " << result_int << std::endl;
std::cout << "Result Float: " << result_float << std::endl;
std::cout << "Result Double: " << result_double << std::endl;
return 0;
}
همانطور که مشاهده می کنید، ما اکنون سه تابع با نام Add داریم. ولی شاید سوال پرسیده شود که چطور لینکر متوجه تفاوت این توابع با یکدیگر می شود درحالیکه هر سه دارای یک نام واحد هستند. اینجاست که مسئله Name Mangling یا همان Decoration نام آبجکت ها در CPP مطرح می شود. اگر شما برنامه مذکور را دیزاسمبل کنید، متوجه تفاوت کد منبع (Source-code) و کد ماشین/اسمبلی (Machine/Assembly-code) خواهید شد.
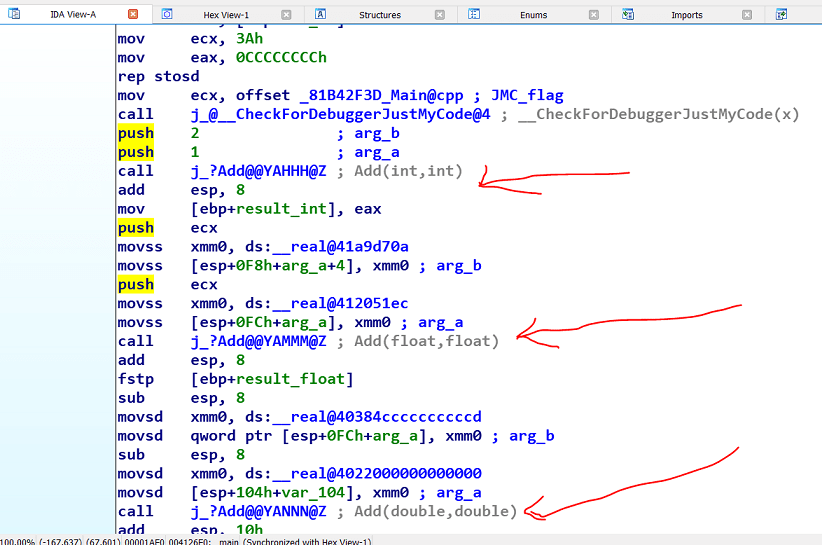
همانطور که در خروجی دیزاسمبلی برنامه اکنون مشاهده می کنید، توابع اگرچه در سطح کد منبع دارای نام مشابه با یکدیگر بودند، اما بعد کامپایل نام آن ها به شکل بالا تبدیل می شود. به این شیوه نام گذاری Name Mangling یا Decoration گویند که قواعد خاصی در هر کامپایلر برای آن وجود دارد.
این ویژگی موجب می شود در ادامه لینکر بتواند تمیز بین انواع توابع Add شود. به عنوان مثال، تابع نامگذاری شده با عنوان j__?Add@YAHH@Z تابعی است که به نوعی از تابع Add اشاره دارد که ورودی هایی از نوع عدد صحیح دریافت می کند. این شیوه نامگذاری خلاصه موجب خواهد شد لینکر بتواند به سادگی بین توابع تمایز قائل شود.
با این حال هنوز یک مشکل باقی است، و آن هم تکرار مجدد یک پیاده سازی برای هر تابع است. به نظر شما آیا راهی وجود دارد که ما از پیاده سازی مجدد توابعی که ساختار مشابه برای انواع ورودی ها دارند، جلوگیری کنیم؟ باید بگوییم، بله. این امکان برای شما به عنوان توسعه دهنده CPP در نظر گرفته شده است.
ویژگی که اکنون به عنوان Templateها در مباحث Metaprogramming یا Generic Programming استفاده می شود، ایجاد شده است تا این مشکل را اساساً برای ما رفع کند. با استفاده از این ویژگی کافی است، طرح یا الگوی یک تابع را پیاده سازی کنید، تا در ادامه خود کامپایلر مبتنی بر ورودی هایی که به الگو عبور می دهید، در Backend، یک نمونه تابع Overload شده مبتنی بر آن الگو برای نوع داده شما ایجاد کند.
#include <iostream>
template <typename Type>
Type Add(Type arg_a, Type arg_b)
{
return arg_a + arg_b;
}
int main(int argc, const char* argv[])
{
int result_int = Add(1, 2);
float result_float = Add(10.02f, 21.23f);
double result_double = Add(9.0, 24.3);
std::cout << "Result Integer: " << result_int << std::endl;
std::cout << "Result Float: " << result_float << std::endl;
std::cout << "Result Double: " << result_double << std::endl;
return 0;
}
به عنوان مثال، در بالا تابع Add را مشاهده می کنید که نوع داده ورودی این تابع و حتی نوع خروجی آن مشخص نشده است و در قالب Typename به کامپایلر معرفی شده است. این یک الگو برای تابع Add است. کامپایلر اکنون می تواند مبتنی بر ورودی هایی که به تابع هنگام فراخوانی یا اصطلاحا Initialization عبور می دهیم، یک نمونه تابع Overload شده از آن الگو ایجاد کند و در ادامه آن را برای استفاده در محیط Runtime فراخوانی کند. حال اگر برنامه بالا را دیزاسمبل کنید، مشاهده خواهید کرد که کامپایلر از همان قاعده Overloading استفاده کرده است تا نمونه ای از تابع Add متناسب با نوع ورودی هایش ایجاد کند.
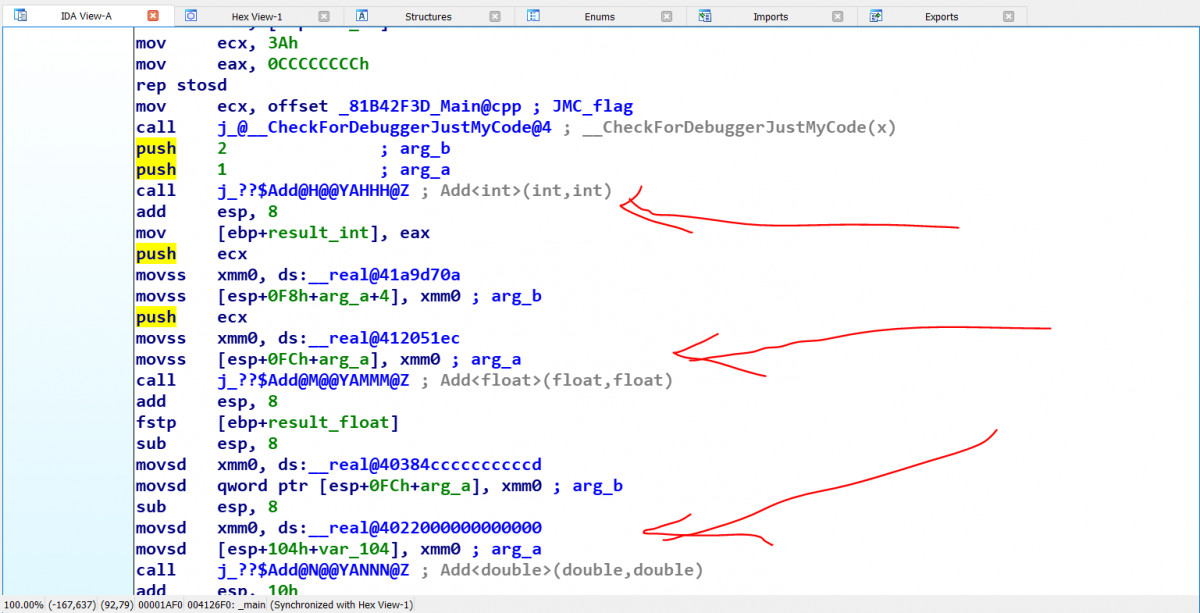
هنوز می توان برنامه نویسی با CPP را جذاب تر و البته ساده تر کرد، اما چطور؟ همانطور که در قطعه کد بالا مشاهده می کنید، هنوز ما باید خود تشخیص دهیم که نوع خروجی تابع قرار است به چه شکل باشد. این مورد خیلی مواقع مشکل ساز خواهد بود.
برای حل این مسئله، در CPP مبحثی در نظر گرفته شده است که آن را به عنوان Auto Deduction می شناسیم که سطح هوشمندی کامپایلر CPP را بالاتر می برد. در این ویژگی خود کامپایلر است که مشخص می کند نوع یک متغیر مبتنی بر خروجی که به آن تخصیص داده می شود، چیست. به عنوان مثال، شما می توانید برنامه بالا را به شکل زیر بازنویسی کنید:
#include <iostream>
template <typename Type>
auto Add(Type arg_a, Type arg_b)
{
return arg_a + arg_b;
}
int main(int argc, const char* argv[])
{
auto result_int = Add(1, 2);
auto result_float = Add(10.02f, 21.23f);
auto result_double = Add(9.0, 24.3);
std::cout << "Result Integer: " << result_int << std::endl;
std::cout << "Result Float: " << result_float << std::endl;
std::cout << "Result Double: " << result_double << std::endl;
return 0;
}
با استفاده از ویژگی Auto Deduction و کلیدواژه Auto در برنامه، خود کامپایلر در ادامه مشخص خواهد کرد که تابع Add چه نوع خروجی دارد و همچنین نوع متغیرها برای ذخیره سازی خروجی Add چه باید باشد. به عبارتی اکنون تابع Add هم Value و هم Data type را مشخص می کند که این موجب می شود برنامه نویسی با CPP خیلی ساده تر از گذشته شود. حال اگر به نمونه برنامه آخر نگاه کنید و آن را با نمونه C مقایسه کنید، متوجه خواهید شد که CPP چقدر کار را برای ما ساده تر کرده است.
در این پست به هر صورت، قصد داشتم به شما نشان دهم که نحوه تحول CPP به صورت گام به گام چطور بوده است و البته اینکه پشت هر ویژگی در CPP چه منطق کلی وجود دارد. امیدوارم این مقاله برای شما مفید بوده باشد. نمونه انگلیسی این مقاله را می توانید در این آدرس (لینک) مطالعه کنید.
میلاد کهساری الهادی
-
 5
5
-
 1
1
-
 3
3
3 دیدگاه
نظرهای پیشنهاد شده