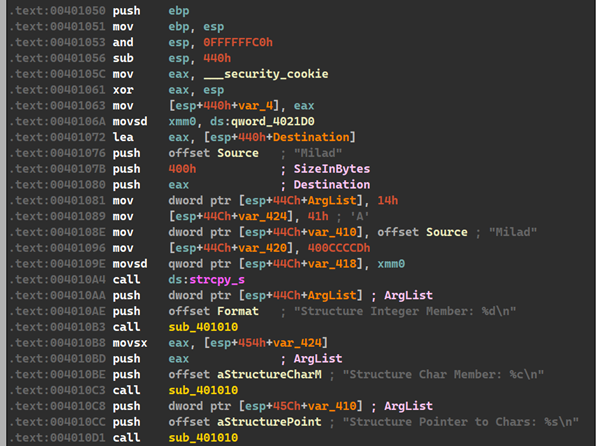
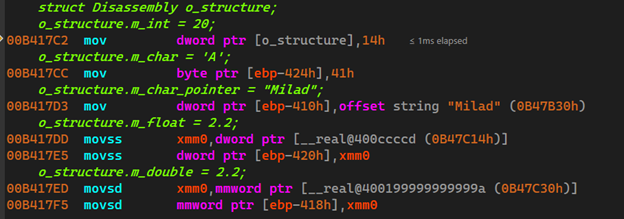
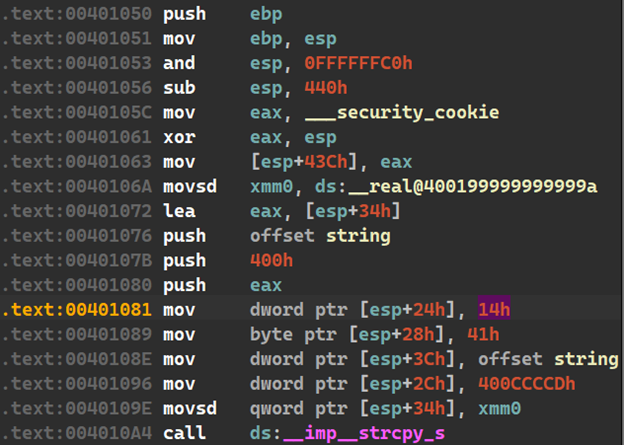
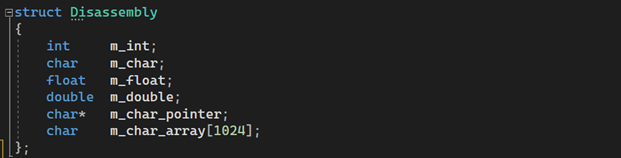
چندی پیش یکی از دوستان درمورد کتابخانهٔ zlib از من سوأل پرسیده بود که جالب شد برایم تا نگاهی بکنم. zlib یک کتابخانهٔ فشردهسازی بر اساس الگوریتم DEFLATE هست که خود این الگوریتم تلفیقی از LZ77 و الگوریتم Huffman هست و عمل فشردهسازیدرحافظه را انجام میدهد، اطلاعات بیشتر درمورد اینا خواستید از اینجا استفاده کنید. این کتابخانه یک قسمت مهم از پلتفرمهای معروفی همچون GNU/Linux , iOS و.. هست.
تستی که با این کتابخانه انجام دادم واقعاً برایم جالب بود، یک فایل متنی ۶۰۰ مگابایتی را به ۱۲۱ مگابایت رسوند در مدّت زمان خیلی کوتاهی با یک پردازندهٔ Intel(R) Core(TM) i7 CPU M 620. خب بریم یک تست بکنیم. اوّل سورس برنامه را از این قسمت بارگیری کنید :
https://www.zlib.net/
توضیحات مفصل را میخواید میتوانید از اینقسمت استفاده کنید. امّا من از یکمثال استفاده میکنم، بعد از اینکه سورسکد را دانلود کردید کافیه که از حالت فشرده خارجش کنید و وارد دایرکتوری مربوطهاش بشید. برای کامپایل شما نیاز به :
-
GCC
-
GNU Make
دارید، اگر نمیدانید GNU Make چی هست، میتوانید در اینقسمت با GNU Make آشنا بشید. خب اگر ابتدا برنامهٔ make را داخل دایرکتوری فراخوانی کنید پیغام زیر را نمایش میدهد :
Please use ./configure first. Thank you.
که مؤدبانه خواهش میکند اوّل اسکریپت configure را اجرا کنیم، بعد از اجرای این اسکریپت چکهای لازم انجام میشود و بعد میتوانید make را اجرا کنید تا کتابخانههای مورد نظر ساخته بشود. بعد اتمام کار، ما فقط نیاز به Shared lib ها و Header File مربوطه داریم. (درصورتیکه نمیدانید Shared Lib چیست، میتوانید در اینقسمت با نحوهٔکار/ساخت آن آشنا شوید). پس بهتر است یک دایرکتوری به اسم lib در ساختار دایرکتوری پروژهٔ خودمان درست کنیم و به اینصورت عمل کنیم :
zlib-1.2.11$> mkdir ../zlibTEST/lib
zlib-1.2.11$> mv libz*so* ../zlibTEST/lib
renamed 'libz.so' -> '../zlibTEST/lib/libz.so'
renamed 'libz.so.1' -> '../zlibTEST/lib/libz.so.1'
renamed 'libz.so.1.2.11' -> '../zlibTEST/lib/libz.so.1.2.11'
zlib-1.2.11$> mv zlib.h ../zlibTEST/header
renamed 'zlib.h' -> '../zlibTEST/header/zlib.h'
در این قسمت، اوّل ما خارجاز دایرکتوری zlib داخل یک دایرکتوری دیگر که پروژهٔ ما درآن قرار دارد یک دایرکتوری به اسم lib ساختیم که shared lib و header file مربوطه را درآن قرار دهیم. سپس تمام فایلهایی که به اسم 'libz*so*' هستند را به آن دایرکتوری انتقال دادیم؛ سه فایل قرار دارد که دو تا از آنها به libz.so.1.2.11 لینک شدهاند.
نقل قول
میدانیم که Shared LIbها فقط یکبار در سیستمعامل قرار میگیرند، و تمام برنامهها به آن لینک میشوند. خب اگر قرار باشد که هر Shared Lib برنامهای یک اسم در هر آپدیت بگیرد. مثلا :
-
lib.so.1.2.11
-
lib.so.1.2.12 ...
مشکلساز میشود، چرا که آنبرنامه دیگر نمیتواند از آخرین نسخهٔ کتابخانه استفاده کند و برای استفاده باید دوباره کامپایل شود، از این رو هر کتابخانه به یک اسم نوشتهمیشود مثلاً libz.so و این فایل به فایلهای اصلی لینک میشود. لکن دیگر شما فقط به libz.so برنامهٔتان را لینک میکنید و توسعهدهندهٔ کتابخانه در هربار آپدیت فقط آن فایلی را کهlibz.so به آن اشاره میکند را تغییر میدهد و برنامههای دیگر همیشه با آخرین آپدیت همراه هستند.
خب بریم سروقت تست خودمان.
اوّل از همه نیاز به هدرفایلهای مربوطه داریم :
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include "zlib.h"
کتابخانهٔ zlib از ثابت CHUNK برای مقداردهی Buffer خودش استفاده میکنه، و ما نیاز داریم که این ثابت را تعریف کنیم :
#define CHUNK 251904
هرچی مقدار بیشتر باشه سیستم کارآمد تر هست، داخل خود اسناد گفته که بهتره از 256k استفاده کنیم درصورتیکه مقدار حافظهٔ موردنیاز رو داریم. حالا باید تابع Compressing خودمان را با استفاده از کتابخانهٔ zlib پیاده کنیم. ما اسم این تابع را compressing میزاریم، این تابع دو stream دریافت میکند که یکی ورودی و یکی خروجی میباشد. یک ورودی دیگر تابع سطح فشردهسازی هست که در ادامه بحث میکنیم :
int
compressing (FILE *source, FILE *dest, int level);
خروجیه تابع میتواند این موارد باشد :
- Z_OK = 0
- Z_STREAM_END = 1
- Z_NEED_DICT = 2
- Z_ERRNO = -1
- Z_STREAM_ERROR = -2
- Z_DATA_ERROR = -3
- Z_MEM_ERROR = -4
- Z_BUF_ERROR = -5
- Z_VERSION_ERROR = -6
از اسامی تقریباً مشخص هست که چه مفهومی دارند و نیازی به توضیح نیست. حال نیاز هست که یک سری متغیرهایمحلی که فقط مورد استفادهٔ خود تابع هست را داخل تابع تعریف کنیم :
int return_;
int flush;
int have;
z_stream stream;
unsigned char input[CHUNK];
unsigned char output[CHUNK];
متغیر اوّل که از اسمش مشخص هست، برای مشخص کردن مقداربازگشتی از تابع هست، و متغیر دوّم برای مشخص کردن وضعیّت flushing برای یکی از توابع zlib هست.
نقل قول
زمانی که شما مقداری را مثلاً میخواهید داخل یک stream بریزید، بلافاصله انجام نمیشود. این مقدار داخل Buffer نگهداری میشود تا زمانی که تابع fflush() صدا زده شود.
متغیر سوّم مقدار اطلاعاتی هست که از یکی از توابع zlib به اسم deflate() بر میگردد. متغیر چهارم هم از نوع یک ساختار داخلیه zlib میباشد :
typedef struct z_stream_s {
z_const Bytef *next_in; /* next input byte */
uInt avail_in; /* number of bytes available at next_in */
uLong total_in; /* total number of input bytes read so far */
Bytef *next_out; /* next output byte will go here */
uInt avail_out; /* remaining free space at next_out */
uLong total_out; /* total number of bytes output so far */
z_const char *msg; /* last error message, NULL if no error */
struct internal_state FAR *state; /* not visible by applications */
alloc_func zalloc; /* used to allocate the internal state */
free_func zfree; /* used to free the internal state */
voidpf opaque; /* private data object passed to zalloc and zfree */
int data_type; /* best guess about the data type: binary or text
for deflate, or the decoding state for inflate */
uLong adler; /* Adler-32 or CRC-32 value of the uncompressed data */
uLong reserved; /* reserved for future use */
} z_stream;
توضیحاتَش داده شده داخل خودzlib.h که این ساختار به چه شکلی هست و هر مقدار برای چه کاری هست. و دو متغیر بعدی بافرهای ورودی و خروجیما میباشد.
کتابخانهٔ zlib از روش تخصیصحافظهٔ به خصوص خود استفاده میکند، از این رو باید ساختاری که ساختهایم را با استفاده از تابع deflateInit() مقداردهی کنیم، قبل از مقداردهی باید یکسری مقادیر را طبق گفتهٔ مستندات برابر Z_NULL قرار بدهیم :
stream.zalloc = Z_NULL;
stream.zfree = Z_NULL;
stream.opaque = Z_NULL;
return_ = deflateInit(&stream, *level);
if (return_ != Z_OK)
return return_;
در اینجا مقدار level میتواند چیزی بین -1 تا 9 باشد، هرچه مقدار کمتر باشد سرعت فشردهسازی بالاتر است و مقدارفشردهسازی کمتر. مقدار صفر هیچ فشردهسازیای انجام نمیشود و صرفاً یک فایل با فرمت zlib درست میشود. ماکروی Z_DEFAULT_COMPRESSION برابر با -1 هست که سرعت و فشرهسازی خوبی را فراهم کند. در تست قبلی خودم مقدار را برابر Z_DEFAULT_COMPRESSION گذاشتم و اینبار میخواهم برابر ۹ بگذارم.
خب حالا باید بریم سراغ فشردهسازی، در این قسمت ما یکdo-while مینویسیم که جریانورودی را تا EOF (انتهای فایل) بخواند :
do{
stream.avail_in = fread(input, 1, CHUNK, source);
if (ferror(source)){
deflateEnd(&stream);
return Z_ERRNO;
}
flush = feof(source) ? Z_FINISH : Z_NO_FLUSH;
stream.next_in = input;
* خب برای دوستانی که با توابع کار با Streamها در سی آشنا هستند، پیشنهاد میکنم که این قسمت رو یهکمی ازش گذر کنند.
اوّل ما از تابع fread استفاده کردیم، این تابع به اینصورت در فایل stdio.h تعریف شده است :
size_t
fread( void *restrict buffer, size_t size, size_t count,
FILE *restrict stream );
و کاری که میکند این است که اوّل یک اشارهگر به جایی که باید دادههای خوانده شده ذخیره بشوند میگیرید که اینجا ما آرایهٔ input را میدهیم، سپس اندازهٔ هر دادهای که قرار است خوانده بشود را دریافت میکند که یک بایت است هر کاراکتر، آرگومان بعدی مقداری است که باید از Stream خوانده شود که ما به اندازهٔ CHUNKتا میخواهیم :). آرگومان آخری نیز که مشخصهست. جریانی است که باید دادهها خوانده شود.
این تابع مقدار دادههایی را که با موفقیت خواندهاست را برمیگرداند. که ما آن را در stream.avail_in نگهداری میکنیم. سپس باید Stream را چک کنیم که خطایی رخ نداده باشد. درصورتیکه این تابع مقداری غیراز صفر برگرداند مشخص است که خطایی رخ نداده. و درصورتیکه خطایی رخ دادهباشد با استفاده از delfateEnd() جریان را پایان میدهیم.
و در انتها باید بررسی کنیم که آیا جریانما به EOF (پایان فایل) رسیدهاست یا خیر. که اینکار با استفاده از تابع feof() در هدرفایل stdio.h صورت میگیرد. درصورتیکه پایانفایل رسیده باشد مقداری غیر از صفر این تابع بر میگرداند.
در انتها طبق گفتهٔ مستندات باید اشارهگری به دادههای خوانده شده در next_in قرار بگیرد. که ما اینکار را در خط آخر انجام دادهایم.
خب در اینقسمت که ما دادهها را از جریان ورودی خواندیم نیاز هست که با استفاده از تابع deflate() عمل فشردهسازی را انجام دهیم. این تابع داخل یک حلقهٔ do-while دیگر فراخوانی میشود. و تا انتهای دادههای خوانده شده ادامه میدهیم :
do{
stream.avail_out = CHUNK;
stream.next_out = output;
مقدار فضای outputما که برای deflate() تهیه شده است توسط avail_out به بایت مشخص میشود و next_out اشارهگری به آن جریان خروجی میباشد که در اینجا آرایهٔ output میباشد.
خب حالا ما باید تابع فشردهسازی deflate() را فراخوانی کنیم. این تابع به اندازهٔ avail_in بایت از next_in پردازش میکند و به اندازهٔ avail_out بایت در next_out مینویسد. که اینجا مقادیر avail_out/in ما برابر با CHUNK میباشد و next_out/in ما به آرایههای input و output اشاره میکند. این حلقهٔ داخلیکه درست کردیم تضمین میکند که تمام دادههای خواندهشده پردازش و نوشته میشوند.
ورودیهای تابع deflate() یک اشارهگر به ساختار z_stream میباشد (همان متغیر stream خودمان) و یک ورودی دیگر که مشخص میکند وضعیت و چگونگی flush کردن دادهها در output. تابع deflate() تا زمانیکه مقدار ورودی flush state برابر Z_NO_FLUSH باشد ادامه میدهد و وقتیکه مقدار flush state برابر Z_FINISH تابع deflate() کار را تمام میکند. این قسمت برای افرادی هست که میخواهند کارهای خاصی با این تابع انجام دهند که بدین منظور بهتر است مستندات فنی کتابخانه را مطالعه کنند.
return_ = deflate(&stream, flush);
assert(return_ != Z_STREAM_ERROR);
در اینجا ما با استفاده از ماکروی assert که در هدرفایل assert.h تعریف شده است یک شرط میگذاریم که درصورتیکه آن شرط حاصلش برابر صفر باشد مقادیری را در stderr چاپ و با استفاده از abort() برنامه را خاتمه میدهد.
خب حالا باید مشخص کنیم که تابع deflate() در آخرین فراخوانی چه مقدار خروجی تولید کردهاست و چه مقدار باقیمانده است. و مقادیر تولید شده را داخل جریان خروجی مینویسیم :
have = CHUNK - stream.avail_out;
if (fwrite(output, 1, have, dest) != have || ferror(dest)) {
deflateEnd (&stream);
return Z_ERRNO;
}
در اینجا ما با استفاده از تابع fwrite (که ورودیهای آن مشابه fread میباشند) مقدار تولید شده را داخل جریان خروجی مینویسیم. این تابع باید تعداد مقادیری که با موفقیت نوشته شدهاند را به بایت بر گرداند. پس بررسی میکنیم که اگر برابر با have نبود یا اینکه برای جریان dest خطایی رخ داده است. برنامه را خاتمه دهد. تابع deflate() تا جایی که بتواند به کارخود ادامه میدهد و زمانی که دیگر دادهای برای پردازش نداشتهباشد مقدار avail_out برابر صفر قرار میگیرد و مقدار Z_BUF_ERROR را بر میگرداند. و ما میتوانیم از حلقهٔ داخلی خارج شویم :
} while (stream.avail_out == 0);
assert(stream.avail_in == 0);
خب ما با بررسی متغیر flsuh میتوانیم وضعیت پایان فایل را متوجه بشویم، درصورتیکه مقدار این متغیر برابر Z_FINISH باشد کار ما تمام شدهاست و میتوانیم از حلقه خارج شویم :
} while (flush != Z_FINISH);
assert(return_ == Z_STREAM_END);
و در انتها کافی است که حافظهای که دریافت شده آزاد شود، و مقدار Z_OK از تابع برگرداننده شود :
deflateEnd(&stream);
return Z_OK;
}
خب تابع compress ما به اتمام رسید، حال باید بریم سروقت تابع decompress، این تابع شباهت بسیار زیادی به تابع قبلی دارد :
int
decompress (FILE *source, FILE *dest);
و حالا متغیرهایمحلی را دوباره تعریف میکنم، اینجا دیگر نیازی به متغیر flush نیست چرا که خود توابع zlib پایان کار را مشخص میکنند :
{
int return_;
unsigned have;
z_stream stream;
unsigned char input[CHUNK];
unsigned char output[CHUNK];
و حال نیاز هست که زمینهٔ تخصیص حافظه را فراهم کنیم :
stream.zalloc = Z_NULL;
stream.zfree = Z_NULL;
stream.opaque = Z_NULL;
stream.avail_in = 0;
stream.next_in = Z_NULL;
return_ = inflateInit(&stream);
if (return_ != Z_OK)
return return_;
اینجا مقدار avail_in برابر صفر و مقدار next_in برابر Z_NULL قرار میگیرد تا مشخص شود که هیچ ورودی فراهم نشده است.
حالا باید حلقهٔ معروف خودمان را درست کنیم و با استفاده از تابع inflate() اقدام به Decompressing کنیم :
do {
stream.avail_in = fread(input, 1, CHUNK, source);
if (ferror(source)){
inflateEnd(&stream);
return Z_ERRNO;
}
if (stream.avail_in == 0)
break;
stream.next_in = input;
خب با توجه به توضیحات تابع قبلی این دستورات نیز عملکردشان مشخص است. حال باید حلقهٔداخلی را بنویسیم :
do {
stream.avail_out = CHUNK;
stream.next_out = output;
حال باید تابع inflate() را برای عمل Decompressing فراخوانی کنیم، دیگر اینجا نیازی به مشخص کردن flush state نداریم چرا که خود zlib به طور خودکار مدیریت میکند. تنها چیزی که مهم است، خروجی تابع inflate() میباشد که درصورتیکه برابر Z_DATA_ERROR باشد به معنی ایناست که در دادههای فشردهشده مشکلی وجود دارد. و خروجی دیگر Z_MEM_ERROR میباشد که مشخصکنندهٔ مشکلی در زمان حافظهگیری برای inflate() میباشد :
return_ = inflate(&stream, Z_NO_FLUSH);
assert(return_ != Z_STREAM_ERROR);
switch (return_){
case Z_NEED_DICT:
return_ = Z_DATA_ERROR;
case Z_DATA_ERROR:
case Z_MEM_ERROR:
inflateEnd(&stream);
return return_;
}
در اینجا خروجی تابع را بررسی کرده و درصورتیکه خطایی باشد جریان برنامه را خاتمه میدهیم.
و انتهای حلقه :
have = CHUNK - stream.avail_out;
if (fwrite(output, 1, have, dest) != have || ferror(dest)) {
inflateEnd(&stream);
return Z_ERRNO;
}
} while (stream.avail_out == 0);
و زمانیکه خروجیه inflate() برابر Z_STREAM_END باشد، یعنی اینکه دیگر کار تمام شده و دادهای برای پردازش نمیباشد :
} while (return_ != Z_STREAM_END);
تا این قسمت دیگر کار استخراج به پایان رسیده است . و کار تابع decompress را تمام میکنیم :
inflateEnd(&stream);
return (return_ == Z_STREAM_END) ? Z_OK : Z_DATA_ERROR;
}
خب تمام شد !. ما دوتابع compress و decompress که مستقیم از zlib استفاده میکنند را به پایان رساندیم. حال بیاید از آنها استفاده کنیم.
در وهلهٔ اوّل نیاز است که تابعی داشتهباشیم تا خروجی این توابع را برای ما مدیریت کنند :
void
zlibError(int return_) {
fprintf(stderr, "ZLIB ERROR: ");
switch (return_) {
case Z_ERRNO:
if (ferror(stdin))
fprintf(stderr, "ERROR READING stdin.\n");
if (ferror(stdout))
fprintf(stderr, "ERROR WRITING stdout.\n");
break;
case Z_STREAM_ERROR:
fprintf(stderr, "INVALID COMPRESSION LEVEL.\n");
break;
case Z_DATA_ERROR:
fprintf(stderr, "INVALID OR INCOMPLETE deflate() DATA.\n");
break;
case Z_MEM_ERROR:
fprintf(stderr, "OUT OF MEMORY.\n");
break;
case Z_VERSION_ERROR:
fprintf(stderr, "zlib VERSION MISMATCH.\n");
}
}
و حال تابع main برنامهٔ ما :
int
main(int argc, char **argv) {
int return_;
if (argc == 1) {
return_ = compress(stdin, stdout, 9);
if (return_ != Z_OK)
zlibError(return_);
return return_;
} else if (argc == 2 && strcmp(argv[1], "-d") == 0) {
return_ = decompress(stdin, stdout);
if (return_ != Z_OK)
zlibError(return_);
return return_;
} else {
fprintf(stderr, "zlib Usage: PROGRAMM [-d] < SOURCE > DEST\n");
return EXIT_FAILURE;
}
return EXIT_FAILURE;
}
و برای کامپایل باید موقعیت کتابخانهٔ zlib را مشخص کنیم :
$> gcc main.c -L. -lz -O3 -o zlib
خب حالا بیاید با هم این برنامه را اجرا کنیم :). قبل از اجرا نیاز است که ما یک فایل حجیم داشتهباشیم، برای اینکار کافیه که به اینصورت یکی درست کنیم :
$> yes "iostram.ir" > huge.file
بهتر از بعد از چند ثانیه با استفاده از Ctrl + C برنامه را خاتمه دهید، برای من بعد از ۱۱ ثانیه برنامهٔ yes فایلی به اندازهٔ ۶۲۹ مگابایت، محتوی iostream.ir درست کرد. حالا بریم برای فشردهسازی :
$> time ./zlib < huge.file > huge.file.comp
real 0m13.560s
user 0m5.785s
sys 0m0.375s
من این برنامه با استفاده از برنامهٔ time اجرا کردم تا زمان مصرفی را مشاهده کنم، که بعد از ۱۳ ثانیه به اتمام رسید. حال بیاید بیبنیم حجم خروجی چقدر است !
$> ls -ltrh
total 631M
-rw-r--r-- 1 ghasem ghasem 94K Jan 15 2017 zlib.h
-rwxr-xr-x 1 ghasem ghasem 119K May 10 10:59 libz.so.1.2.11
lrwxrwxrwx 1 ghasem ghasem 14 May 10 10:59 libz.so.1 -> libz.so.1.2.11
lrwxrwxrwx 1 ghasem ghasem 14 May 10 10:59 libz.so -> libz.so.1.2.11
-rw-r--r-- 1 ghasem ghasem 3.5K May 10 14:39 main.c
-rwxr-xr-x 1 ghasem ghasem 18K May 10 14:40 output
-rwxr-xr-x 1 ghasem ghasem 18K May 10 14:46 zlib
-rw-r--r-- 1 ghasem ghasem 629M May 10 14:46 huge.file
-rw-r--r-- 1 ghasem ghasem 1.3M May 10 14:47 huge.file.comp
واقعاً عالی بود. حجم فایل خروجی برابر با 1.3 مگابایت است. یعنی یک مگابایت و ۳۰۰ کیوبایت. حال بیاید از حالت فشرده خارج کنیم فایل را :
$> time ./zlib -d < huge.file.comp > huge.file.dcomp
real 0m12.556s
user 0m0.818s
sys 0m0.472s
بعد از تنها ۱۳ ثانیه یک فایل ۶۲۹ مگابایتی برایمان درست کرد. که عیناً برابر فایل اوّلی میباشد. باور نمیکنید ؟ خب بیاید sha1sum آنها برررسی کنیم :
$> sha1sum huge.file
3c02d5bd13b91f0e663d63d11ee33a2e71126615 huge.file
$> sha1sum huge.file > huge.file.sha1
$> sha1sum huge.file.dcomp > huge.file.dcomp.sha1
$> cat huge*.sha1
3c02d5bd13b91f0e663d63d11ee33a2e71126615 huge.file.dcomp
3c02d5bd13b91f0e663d63d11ee33a2e71126615 huge.file
سورس کامل برنامه را از اینقسمت میتوانید بارگیری کنید.
- موفقوپیروز باشید