جستجو در تالارهای گفتگو
در حال نمایش نتایج برای برچسب های 'آموزش'.
30 نتیجه پیدا شد
-
فایل صوتیِ عدم توانایی تصمیم گیری در مسیرِ یادگیری و رسیدن به موفقیت. زمان اختصاص یافته شده : ۷ دقیقه و ۳۱ ثانیه. Podcast-04.mp3
-
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #7a75ff; color: #ffffff;" >پادکستهای آموزشی</span>
فایل صوتیِ مربوط به نحوهٔ آموزش صحیح و روش یادگیری اصولی. زمان اختصاص یافته شده : ۲۶ دقیقه. Teaching-Learning.mp3 -
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #e62f3d; color: #ffffff;" >برنامه نویسی در C و ++C</span>
همانطور که میدانید در زبانهای برنامهنویسی از نوع کامپایلری، گزینهها و تنظیماتی وجود دارند که به شما امکان این را میدهد تا رفتار کامپایلر (همگردان) را تا حدی سفارشی سازی کنید. این امکان به کمک تنظیمات پرچمها (فلگها) و برخی از گزینهها قابل انجام است و انتخاب پرچمهای مناسب برای کامپایلر میتواند مورد توجه قرار بگیرد. با توجه به دو مقالهای که با عناوین زیر ارائه شده است، در این مقاله به جزئیات بیشتری نسبت به تنظیمات کامپایلر (همگردان یا مترجم) میپردازیم که البته توصیه میکنم در صورت عدم آشنایی با تعاریف مربوطه و به خصوص روند ترجمهٔ کدها و ساختار برنامههای نوشته شده توسط سیپلاسپلاس، بهتر است آنها را بررسی کنید. در مثال زیر، نسخهٔ کامپایلر همراه با اطلاعات مربوط به آن، توسط گزینهٔ option در خط فرمان قابل دریافت است: gcc --version خروجی مربوطه میتواند نسبت به نسخهٔ کامپایلر به صورت زیر باشد: gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0 Copyright (C) 2019 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. در حالت پیشفرض تنظیمات کامپایلر به صورت خودکار انجام میشود. اما در صورتی که نیاز باشد برخی از درخواستها توسط کامپایلر مورد توجه قرار بگیرد و یا برای دیگران آن را گوشزد کند، از این ویژگیها استفاده میشود. در چنین شرایطی میتواند به کامپایلر بگوید که کاربر میخواهد کد را برای اشکالزدائی بهینه کند یا اینکه کاربر نمیخواهد هیچ بهینهسازی خاصی برای آن فعال شود. این عمل معمولاً در سراسر خط فرمان قابل استفاده است و به عنوان مکانیزمی برای دستورالعمل برنامه برای انجام عملیاتی یا رفتاری به روش خاص عمل میکند. به طورکلی، گزینهٔ کامپایلر به عنوان یک عبارت بسیار حساس، برای خط فرمان است که برای تغییر عملکرد پیشفرض کامپایلر استفاده میشود. در اصل این گزینهها برای کامپایل برنامهٔ شما اجبار نیستند، اما برای کمک به کنترل نبههای مختلف برنامه بسیار مفید خواهند بود. از جمله: تولید کد بهینهسازی فایل خروجی (نوع، نام، مکان) خواص پیوند-دهنده اندازه فایل اجرائی سرعت اجرایی اینکه نیاز باشد کدی را بهینهسازی کنید، و یا مسائلی را برای دیگران گوشزد کنید کاملاً سلیقهای است و شما در روند توسعهٔ حرفهای خود میتوانید از این تکنیک استفاده کنید. سادهترین کاربرد این تکنیک میتواند وادار کردن استفادهٔ کامپایلر از یک استاندارد مشخص شده باشد که در صورت پشتیبانی از آن چه به صورت عقبگرد و چه به صورت سوئیچ به استانداردهای اخیر کاربرد خواهد داشت. برای مثال، پرچم std نسخه یا استاندارد ایزو از سیپلاسپلاس را کامپایلرهای رایجی مانند Clang و GCC مشخص میکند که به صورت زیر تعریف میشوند: -std=c++11 (ISO C++11) -std=c++14 (ISO C++14) -std=c++1z (ISO C++17) -std=c++20 (C++20 experimental) -std=gnu++ (ISO C++ with GNU extensions) معادل پرچم استاندارد در کامپایلر MSVC به صورت زیر است: /std:c++14 /std:c++17 /std:c++latest /std:c11 /std:c17 نکته، گزینهٔ /std از نسخهٔ ۲۰۱۷ به بعد از کامپایلر مایکروسافت در دسترس است. به صورت پیشفرض در این نسخه از کامپایلر این گزینه بر روی استاندارد ۱۴ تنظیم شده است. در صورت نیاز به ارتقاء آن به نسخهٔ ۱۷ طبق نمونه عمل کنید. همچنین طبق قوائد مایکروسافت استاندارد نهایی شده از آخرین ویژگیها در کامپایلر تحت /std:c++latest قابل دسترس میباشد که در این لحظه شامل استاندارد ۲۰ میشود. گزینهٔ Verbosity به عنوان اِسم یا Verbose از نوعِ صِفَت به معنای درازنویسی (بهتر است به معنای ارائهکنندهٔ اطلاعات بیشتر به آن توجه شود)، با کاراکتر W که به عنوان مخففی از Warning محسوب میشود قابل تنظیم است. بنابراین، پرچمهای زیر برای اهداف مشخصی در نظر گرفته میشوند که توضیحات هر یک را در مقابل آن آوردهایم: پرچم -Wall با فعال شدن، تعداد زیادی از پرچمهای هشدار دهندهٔ کامپایلر را به طور خاص و باهم روشن میکند که لیست آن به صورت زیر است: -Waddress -Warray-bounds=1 (only with -O2) -Warray-parameter=2 (C and Objective-C only) -Wbool-compare -Wbool-operation -Wc++11-compat -Wc++14-compat -Wcatch-value (C++ and Objective-C++ only) -Wchar-subscripts -Wcomment -Wduplicate-decl-specifier (C and Objective-C only) -Wenum-compare (in C/ObjC; this is on by default in C++) -Wenum-conversion in C/ObjC; -Wformat -Wformat-overflow -Wformat-truncation -Wint-in-bool-context -Wimplicit (C and Objective-C only) -Wimplicit-int (C and Objective-C only) -Wimplicit-function-declaration (C and Objective-C only) -Winit-self (only for C++) -Wlogical-not-parentheses -Wmain (only for C/ObjC and unless -ffreestanding) -Wmaybe-uninitialized -Wmemset-elt-size -Wmemset-transposed-args -Wmisleading-indentation (only for C/C++) -Wmissing-attributes -Wmissing-braces (only for C/ObjC) -Wmultistatement-macros -Wnarrowing (only for C++) -Wnonnull -Wnonnull-compare -Wopenmp-simd -Wparentheses -Wpessimizing-move (only for C++) -Wpointer-sign -Wrange-loop-construct (only for C++) -Wreorder -Wrestrict -Wreturn-type -Wsequence-point -Wsign-compare (only in C++) -Wsizeof-pointer-div -Wsizeof-pointer-memaccess -Wstrict-aliasing -Wstrict-overflow=1 -Wswitch -Wtautological-compare -Wtrigraphs -Wuninitialized -Wunknown-pragmas -Wunused-function -Wunused-label -Wunused-value -Wunused-variable -Wvla-parameter (C and Objective-C only) -Wvolatile-register-var -Wzero-length-bounds برای مثال، با فعالسازی پرچم -Werror، هرگونه هشدار را به خطای تلفیقی تبدیل میکند. این کار باعث میشود خطاهای مربوط به کدهای خطرناک را به گونهای جلوه دهید که از کامپایل آنها جلوگیری شود. کارهای مشابه این مورد، به صورت پیشفرض در زبانهای مانند Rust انجام میشود که از کدهای دارای خطا و خطرناک برای کامپایل جلوگیری میکند. به کار گیری چنین پرچمهایی در کامپایلر سی++ میتواند خطاهای شامل هشدار رو به خطاهای غیر قابل کامپایل تبدیل کند. جهت تنظیم این پرچم در پروژهٔ خود کافی است در ابزار ساخت مورد نظر آن را اعمال کنید، به عنوان مثال در سیمیک (CMake) به صورت زیر عمل کنید: SET (CMAKE_CXX_FLAGS "-Werror") و یا در QMake به شیوهٔ زیر میتوانید این ویژگی را فعال کنید: QMAKE_CXXFLAGS += -Werror برای مثال، کد زیر در صورت فعال بودن این پرچم، کامپایل نخواهد شد. int myFunction() { //no return! } auto main() -> int { return 0; } خروجی این پیام به صورت زیر خواهد بود: error: no return statement in function returning non-void [-Werror=return-type] به معنای این که هیچ بیانیهای به عنوان عبارت بازگشتی در تابع مربوطه که از نوع غیر-باطل (non-void) است، وجود ندارد. بسیاری از این گزینهها برای هدف خاصی در نظر گرفته میشوند که میتوانید جزئیات بیشتر آن را در این لینک پیدا کنید. برخی از پرچمهای رایج برای کتابخانهها گزینهٔ پرچم -lm امکان کامپایل کتابخانههای libm نوع سوم را به همراه کتابخانههای ریاضیاتی که عموماً به زبان سی هستند را میدهد. گزینهٔ پرچم -lpthread امکان کامپایل کتابخانههای مشترک از استاندارد پازیکس (Posix) را ارائه میکند. گزینهٔ پرچم -lstdc++fs امکان کامپایل و لینک شدن به کتابخانهٔ فایلسیستم را در استاندارد ۱۷ به بعد میدهد. پرچمهای بهینهسازی تحت کامپایلر با فعالسازی و اعمال پرچم-O0 هیچ گونه بهینهسازی بر روی کدها انجام نمیشود، در اصل امکان بهینهسازی کاملاً غیرفعال میشود. زمان کامپایل و همگردانی کدها سریعتر میشود و برای ابزارهای اشکالزدائی بهترین عملکرد را دارد. با فعالسازی و اعمال پرچم-O2 سطح بالاتری از بهینهسازی صورت میگیرد، ترکیبی از حالت بهینهسازی و سطح قبلی را اعمال میکند و طبیعتاً زمان بیشتری صرف کامپایل میشود و گزینهٔ بهتری برای ساخت یک محصول بهتر است. با فعالسازی و اعمال پرچم-O3 سطح بالاتری نسبت به سطح دوم از بهینهسازی صورت میگیرد، طبیعتاً زمان بیشتری صرف کامپایل میشود و گزینهٔ بهتری برای ساخت یک محصول بهتر است. از طرفی حجم باینری بیشتری را تولید کرده و زمان کامپایل طولانیتری را تحمیل میکند. با فعالسازی و اعمال پرچم-OFast سطح بالاتری نسبت به سطح سوم از بهینهسازی صورت میگیرد، طبیعتاً زمان بیشتری صرف کامپایل میشود و گزینهٔ بسیار بیشتری مانند -ffloat-store, -ffsast-math, -ffinite-math-only, -O3 را فعال میکند و برای ساخت یک محصول بهتر است. با فعالسازی و اعمال پرچم -OS امکان سطح دوم از بهینهسازی فعال میشود، با تفاوت اینکه برخی از پرچمها با هدف کاهش اندازهٔ فایل کدِ شیء (object-code) غیرفعال میشوند. با فعالسازی و اعمال پرچم-Oz سطح بالاتری نسبت به سطح -OS برای کاهش اندازهٔ فایل صورت میگیرد. این گزینه مختصِ Clang است. توضیحات و مراجع دقیق و بیشتر در رابطه با عملیات مربوط به پرچمهای بهینه سازی در کامپایلرهای مختلف به صورت زیر است: کامپایلر GCC کامپایلر Clang کامپایلر MSVC دقت کنید که نوع پرچمها نسبت به کامپایلرها متفاوت است، برای مثال پرچم -Od به معنای غیرفعالسازی تمامی بهینهسازیها و جمعآوری و کامپایل سریع کدها و در نهایت اشکالزدائی بهتر است که در Clang و MSVC پشتیبانی میشود و یا پرچمِ -OS صرفاً بر روی کامپایلر کلنگ قابل استفاده است. -
در این مقاله نیاز است بدانید که، کتابخانهٔ توابع ویژه ریاضی در اصل بخشی از کتابخانه TR1 ISO / IEC TR 19768: 2007 بود، سپس به عنوان یک استاندارد ISO مستقل، ISO / IEC 29124: 2010 منتشر شد و در نهایت از C++ 17 به استاندارد ایزو ادغام شد. برای استفاده از توابع ریاضیاتی مانند هرمیتی، بسل و غیره کافی است فایل سرآیند <cmath> را فراخوانی کنید. به عنوان مثال توابع چندجملهای لگر به صورت زیر میتوانند مورد استفاده قرار گیرند: #include <cmath> #include <iostream> double L1(unsigned m, double x) { return -x + m + 1; } double L2(unsigned m, double x) { return 0.5*(x*x-2*(m+2)*x+(m+1)*(m+2)); } int main() { // spot-checks std::cout << std::assoc_laguerre(1, 10, 0.5) << '=' << L1(10, 0.5) << '\n' << std::assoc_laguerre(2, 10, 0.5) << '=' << L2(10, 0.5) << '\n'; } مثالی از کاربرد توابع چندجملهایهای لژاندر : #include <cmath> #include <iostream> double P20(double x) { return 0.5*(3*x*x-1); } double P21(double x) { return 3.0*x*std::sqrt(1-x*x); } double P22(double x) { return 3*(1-x*x); } int main() { // spot-checks std::cout << std::assoc_legendre(2, 0, 0.5) << '=' << P20(0.5) << '\n' << std::assoc_legendre(2, 1, 0.5) << '=' << P21(0.5) << '\n' << std::assoc_legendre(2, 2, 0.5) << '=' << P22(0.5) << '\n'; } نحوهٔ استفاده از توابع بتا #include <cmath> #include <string> #include <iostream> #include <iomanip> double binom(int n, int k) { return 1/((n+1)*std::beta(n-k+1,k+1)); } int main() { std::cout << "Pascal's triangle:\n"; for(int n = 1; n < 10; ++n) { std::cout << std::string(20-n*2, ' '); for(int k = 1; k < n; ++k) std::cout << std::setw(3) << binom(n,k) << ' '; std::cout << '\n'; } } اطلاعات بیشتر از این تابع، در این لینک. نحوهٔ استفاده از توابع انتگرال بیضوی نوع اول : #include <cmath> #include <iostream> int main() { double hpi = std::acos(-1)/2; std::cout << "K(0) = " << std::comp_ellint_1(0) << '\n' << "π/2 = " << hpi << '\n' << "K(0.5) = " << std::comp_ellint_1(0.5) << '\n' << "F(0.5, π/2) = " << std::ellint_1(0.5, hpi) << '\n'; std::cout << "Period of a pendulum length 1 m at 90° initial angle is " << 4*std::sqrt(1/9.80665)* std::comp_ellint_1(std::pow(std::sin(hpi/2),2)) << " s\n"; } اطلاعات بیشتر از این تابع، در این لینک. نحوهٔ استفاده از توابع انتگرال بیضوی نوع دوم : #include <cmath> #include <iostream> int main() { double hpi = std::acos(-1)/2; std::cout << "E(0) = " << std::comp_ellint_2(0) << '\n' << "π/2 = " << hpi << '\n' << "E(1) = " << std::comp_ellint_2(1) << '\n' << "E(1, π/2) = " << std::ellint_2(1, hpi) << '\n'; } اطلاعات بیشتر از این تابع، در این لینک. نحوهٔ استفاده از توابع انتگرال بیضوی نوع سوم : #include <cmath> #include <iostream> int main() { std::cout << std::fixed << "Π(0.5,0) = " << std::comp_ellint_3(0.5, 0) << '\n' << "K(0.5) = " << std::comp_ellint_1(0.5) << '\n' << "Π(0,0) = " << std::comp_ellint_3(0, 0) << '\n' << "π/2 = " << std::acos(-1)/2 << '\n' << "Π(0.5,1) = " << std::comp_ellint_3(0.5, 1) << '\n'; } اطلاعات بیشتر از این تابع، در این لینک. نحوهٔ استفاده از توابع بسل نوع اول : #include <cmath> #include <iostream> int main() { // spot check for ν == 0 double x = 1.2345; std::cout << "I_0(" << x << ") = " << std::cyl_bessel_i(0, x) << '\n'; // series expansion for I_0 double fct = 1; double sum = 0; for(int k = 0; k < 5; fct*=++k) { sum += std::pow((x/2),2*k) / std::pow(fct,2); std::cout << "sum = " << sum << '\n'; } } اطلاعات بیشتر از این تابع، در این لینک. نحوهٔ استفاده از توابع بسل نوع دوم : #include <cmath> #include <iostream> int main() { // spot check for ν == 0 double x = 1.2345; std::cout << "J_0(" << x << ") = " << std::cyl_bessel_j(0, x) << '\n'; // series expansion for J_0 double fct = 1; double sum = 0; for(int k = 0; k < 6; fct*=++k) { sum += std::pow(-1, k)*std::pow((x/2),2*k) / std::pow(fct,2); std::cout << "sum = " << sum << '\n'; } } اطلاعات بیشتر از این تابع، در این لینک. همچنین در مورد توابع دیگر مانند هرمیتی و غیره میتوانید از مرجع آن استفاده کنید.
-
اگرچه که زبان برنامهنویسی سیپلاسپلاس به عنوان یک زبان بسیار قدرتمند و قدیمی شناخته شده است، اما کتابخانهٔ استاندارد و پیشفرض آن برخی از موارد واقعاً مهم را به تازگی تعبیه کرده است. ویژگیهایی که در زبانهایی مثل جاوا و یا سیشارپ داتنت سالهاست وجود دارند. به هر حال این ویژگیها در سی++ ۱۷ موجود شدهاند و این یک بهبود و پیشرفت بسیار خوب است. برای مثال ما الآن فایلسیستم استانداردی را در اختیار داریم. این ویژگی به عنوان یک کتابخانه، امکان برای انجام عملیات بر روی سیستمفایلها و اجزای آنها مانند، مسیرها، فایلها و پوشهها را فراهم میکند. کتابخانهٔ فایلسیستم در فایل سرآیند <filesystem> قرار گرفته است که توسط فضای نام مخصوص خود std::filesystem قابل فراخوانی است. به مثال زیر توجه کنید: namespace fs = std::filesystem; استفاده از این کتابخانه بسیار ساده و کاربردی است، بنابراین اگر بخواهیم به سادگی مسیری از یک ریشه را به دست آوریم، کد آن به صورت زیر خواهد بود: #include <iostream> #include <filesystem> namespace fs = std::filesystem; int main() { fs::path p = fs::current_path(); std::cout << "The current path " << p << " decomposes into:\n" << "root name " << p.root_name() << '\n' << "root directory " << p.root_directory() << '\n' << "relative path " << p.relative_path() << '\n'; } فراخوانی کتابخانه، نمونهسازی از کلاس current_path و سپس چاپ نام، ریشه و مسیر مربوطهٔ آن صورت گرفته است. بنابراین این کتابخانه دارای کلاسهای زیر است که توضیح و کاربرد هر کدام را آوردهایم: کلاس path، این کلاس امکان کار با مسیرها را فراهم میکند، در واقع برای نمایش یا مشاهدهٔ یک مسیر از این کلاس استفاده خواهیم کرد. کلاس filesystem_error یک شیء استثناء در اثر سربارگذاری بیشاز حد کتابخانهٔ فایلسیستم ایجاد میکند، در واقع برای مدیریت خطاها کاربردی خواهد بود. کلاس directory_entry برای کنترل ورودی یک مسیر استفاده میشود، برای مثال بررسی وجود یا عدم وجود در زیر مجموعههای این کلاس امکانپذیر است. کلاس directory_iterator یک تکرار کننده از محتوای یک مسیر (دایرکتوری) را ارائه میکند. کلاس recursive_directory_iterator یک تکرار کننده از محتوایت یک مسیر یا زیر مسیرهای آن را ارائه میکند. کلاس file_status نوع فایل و مجوزهای آن را ارائه میکند. کلاس space_info اطلاعات مربوط به فضای آزاد و موجود در سیستمفایل را ارائه میکند. کلاس file_type اطلاعات مربوط به نوع فایل را ارائه میکند. کلاس perms مجوزهای سیستمفایل را شناسایی میکند. کلاس perm_options معانی هر یک از عملیات مرتبط با مجوزها را ارائه میکند. کلاس copy_options معانی عملیات کپی را مشخص میکند. کلاس directory_options معانی عملیات مربوط به مسیر (دایرکتوری) را مشخص میکند. کلاس file_time_type مقادیر زمانی مربوط به فایل را ارائه میکند. هر یک از کلاسهای فوق دارای متدها و توابعی هستند که در مدیریت فایلسیستم بسیار کاربردی و مفید خواهد بود. در کلاس path شما میتوانید با متدهای مفیدی کار کنید، برای مثال کد زیر پسوند یک فایل موجود که در مسیر به آن اشاره میشود را، در صورت وجود ارائه خواهد کرد. fs::path("/foo/bar.txt").extension(); اگر مسیر فوق دارای فایل ذکر شده باشد، مقدار برگشتی آن .txt خواهد بود. و یا اگر نیاز باشد نام فایل را ارائه کند کافی است از متد file_name آن استفاده کنید! به مثالهای زیر توجه کنید: #include <iostream> #include <filesystem> namespace fs = std::filesystem; int main() { std::cout << fs::path("/foo/bar.txt").filename() << '\n' << fs::path("/foo/.bar").filename() << '\n' << fs::path("/foo/bar/").filename() << '\n' << fs::path("/foo/.").filename() << '\n' << fs::path("/foo/..").filename() << '\n' << fs::path(".").filename() << '\n' << fs::path("..").filename() << '\n' << fs::path("/").filename() << '\n' << fs::path("//host").filename() << '\n'; } همچنین جهت مدیریت خطا و دریافت یک کد یا پیغام خطا به کد زیر توجه کنید: try { cout << fs::file_size("path&file"); } catch (fs::filesystem_error &e) { cout << "Error Message = " << e.what() << " with Code : " << e.code(); } در صورتی که خطایی رخ دهد، کد خطا ساطع خواهد شد، جهت نمایش پیام خطا از تابع what و دریافت کد خطا از تابع code استفاده میشود. این مقاله ادامه دارد...
-
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #4f67ff; color: #ffffff;" >ابزار CMake</span>
بارها شده است که شما به این فکر کنید برنامهای بنویسید که تحت کامپایلرها و سیستمعاملهای مختلف اجرا شود. بنابراین شما باید از ویژگیهای خاص این روش مراقب باشید چرا که هر سیستمعامل نسبت به خود ساختار و عملکرد متفاوتی را دارد. برای مثال بین رابطهای برنامهنویسی Windows و لینوکس تفاوت بسیار است. یا نوع سیستمعاملهای FreeBSD یا Linux تفاوتهای بسیاری دارند که نباید کدهای شما در همهٔ آنها یکسان باشد. در این بخش من قصد دارم در رابطه با برخی از پرکاربردترین متغیرهای CMake اشارهای داشته باشم. بنابراین متغیرهای زیر را در نظر بگیرید: متغیر UNIX: تمامی سیستمعاملهای شبه-یونیکس مانند macOS را شامل میشود. درواقع زمانی true است که پلتفرم آن مک یا شبه-یونیکس باشد. متغیر WIN32: زمانی true خواهد بود که پلتفرم مقصد و توسعه ویندوز باشد. متغیر MINGW: پلتفرم ویندوز را بر پایهٔ MinGW شامل میشود و زمانی true خواهد بود که پلتفرم ویندوز همراه با کامپایلر Mingw پیکربندی شده باشد. متغیر MSVC: زمانی برابر true خواهد بود که پلتفرم ویندوز همراه با کامپایلر MSVC پیکربندی شده باشد. برای مثال اگر بخواهیم کاری انجام دهیم که صرفاً در پلتفرم ویندوز اعمال شود، باید آن را در دامنهٔ چنین شرطی قرار دهیم: if(WIN32) # for Windows operating system in general endif() شما میتوانید در بین این کد متغیری تعریف کنید، مسیر کتابخانهای را شناسایی کنید و یا هر کاری که نیاز است مختص پلتفرم ویندوز اعمال شود را تنظیم نمایید. مثال برای شناسایی محصولات شرکت اپل، تحتِ سیستمعاملهای macOS، iOS و حتی watchOS , tvOS if(APPLE) # for MacOS X or iOS, watchOS, tvOS (since 3.10.3) endif() مثال برای بررسی نوع سیستمعاملهای یونیکس و لینوکس به غیر از محصولات اپل if(UNIX AND NOT APPLE) # for Linux, BSD, Solaris, Minix endif() یک شرط نسبتاً کاملتر به صورت زیر خواهد بود: if(APPLE) # for MacOS X or iOS, watchOS, tvOS (since 3.10.3) MESSAGE("Current platform is macOS!") elseif(Linux AND NOT APPLE) # for Linux and not Unix base such as macOS! MESSAGE("Current platform is Linux!") elseif(WIN32) # for Windows only! MESSAGE("Current platform is Windows!") elseif(UNIX AND NOT APPLE) # for Linux, Unix base Free-BSD, Solaris, Minix MESSAGE("Current platform is Unix!") elseif(ANDROID) # for Linux base, Android only! MESSAGE("Current platform is Android!") endif() مثال برای تشخیص بر اساس نوع کامپایلر، مختص پلتفرم ویندوز تحت Mingw، MSys و MSVC if(MSVC OR MSYS OR MINGW) # for detecting Windows compilers endif() روشهای دیگری نیز برای مقایسه صریح دیگری وجود دارد، برای مثال عملگر STREQUAL میتواند گزینهٔ خوبی در تشخیص و اعمال شرط باشد. مثل مقایسهای، در صورتی که نوع کامپایلر Clang باشد یا گزینههای دیگر: if (CMAKE_CXX_COMPILER_ID STREQUAL "Clang") # using Clang elseif (CMAKE_CXX_COMPILER_ID STREQUAL "GNU") # using GCC elseif (CMAKE_CXX_COMPILER_ID STREQUAL "Intel") # using Intel C++ elseif (CMAKE_CXX_COMPILER_ID STREQUAL "MSVC") # using Visual Studio C++ endif() در این صورت میتوان بر اساس تشخیص شناسهٔ کامپایلر عملیات مورد نظر را اعمال کرد. همچنین میتوان از عملگر MATCHES در بررسی شرط استفاده کرد: if (CMAKE_CXX_COMPILER_ID MATCHES "MSVC") MESSAGE("MSVC") endif() این مقاله ادامه خواهد داشت... -
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #e62f3d; color: #ffffff;" >برنامه نویسی در C و ++C</span>
با توجه به عنوان مقاله، شباهتهای بسیاری بین std::string_view و std::span وجود دارد، در واقع، string_view و span اشیاءای هستند که به یک ترتیبِ به هم پیوسته از عناصری اشاره دارند که نقطهٔ آغازین آنها از موقعیت صفر است؛ و همچنین عملیات استاندارد نگهدارندهها (ظرف) را ارائه میکنند. هر دو نوع شیء از نوع easy-to-copy (کپی آسان) هستند که دارای یک اشارهگر و یک عنصر اندازه هستند. از نظر مفهومی، آنها دیدگاههای غیر صاحب یک آرایه (یا دنبالهٔ پیوسته) هستند که رابط استاندارد غنیای را ارائه میکنند. در مورد تفاوتها (اختلافات) بین این دو، <std::span<T یک الگوی نمایش آرایهای با هدف کلی است، در حالی که std::string_view یک نمایش تخصصیتر در یک دنبالهکاراکتر یا رشته است. در زیر شرح مختصری از این تفاوتها آورده شده است: شیء span یک قالب (Template) است، اما string_view خیر! شیء span، الگویی است که با هر نوعِ تعریف شده توسط کاربر کار میکند، در حالی که string_view به طور خاص نمای یک آرایهٔ مشخص پیوسته است. از نظر سطحی یک string_view معادل <span <char است. char buff[] = "Hello World"; auto sp = std::span<char>(&buff[0], 5); auto sv = std::string_view(&buff[6], 5); for(auto c : sp) std::cout << c; //Hello std::cout << " "; for(auto c : sv) std::cout << c; //World اما، ویژگیهای string_view بیشتر از این مورد میتواند باشد. شیء string_view یک نوع فقط خواندنی برای نمایش است. یکی از ویژگیهای برجستهٔ string_view این است که این شیء فقط یک نمایش فقط خواندنی است. بنابراین، ما نمیتوانیم یک آرایهٔ زیرین را از طریق یک string_view تغییر دهیم، در حالی که این امکان از طریق span ممکن است: char str[] = "hello"; //Change str to uppercase through span auto sp = std::span<char>(str,strlen(str)); std::transform(sp.begin(), sp.end(), sp.begin(), [](char c) { return std::toupper(c); }); //str is now HELLO //Back to lowercase via string_view is not possible. auto sv = std::string_view(str); std::transform(sv.begin(), sv.end(), sv.begin(), [](char c) { return std::tolower(c); }); //ERROR! اگر string_view فقط خواندنی باشد، طول آن به اندازهٔ کافی انعطافپذیر است که از طریق <span <const T به یک نمایش فقط خواندنی تبدیل میشود. بنابراین یک string_view به یک <span <const char نزدیکتر است. البته یک ویژگی وجود دارد که string_view را تضمین میکند. شیء string_view از عملیات std::string-like پشتیبانی میکند. شیء span دارای چندین عملیات متوالی پیوسته است، به عنوان مثال: front, back, begin و operator[]. با این حال، string_view چندین روش دیگر مانند std::string دارد، به عنوان مثال: substr, find, compare سربارگذاری اپراتورها (مانند == و < یا >). بنابراین، string_view میتواند نیازِ به std::string را در مواردی که فضای زیرین آن مهم نیست را از بین ببرد. -
سلام میخواستم بدون کجا میشه پروژه ها و برنامه هایی در ابعاد کوچیک و آزاد رو پیدا کرد و سورسشونو دید و ازشون یادگرفت؟ بیشتر چون ایده ای برای برنامه نویسی توی ذهنم نیست دنبال این هستم برنامه های نوشته شده توسط افراد دیگه رو ببینم و یاد بگیرم که چطوری این کارو میکنن بعد از یادگیری قواعد برنامه نویسی . با تشکر
-
با سلام و درود، همانطور که میدانید ویژگیهای اخیر در استانداردهای ۱۷ و ۲۰ بسیار عظیم و کاربردی هستند. هدف ما در مرجع آیاواستریم این است که با توجه به بهروزرسانیهای زبان سیپلاسپلاس مهمترین مواردی که نیاز است معرفی کنیم. بنابراین در این بخش به یکی از کاربردیترین موارد مرتبط در استاندارد ۱۷ با عنوان صفتهای ویژه اشاره میشود که در ادامه به تعریف هر یک از آنها میپردازیم. با توجه به استانداردهای ۱۱ و ۱۴ که در آن صفتهایی همچون [[deprecated]] و [[noreturn]] معرفی شدهاند که وظیفهٔ آن به ترتیب نمایش وضعیت منسوخ شدن یک عملکرد و یا وضعیت بازگشتی یک تابع از نوع void است. چنین صفاتی میتوانند در زمان اعلان و تعریف متغیرها و یا توابع مورد استفاده قرار گیرند. به عنوان مثال اگر کدی به صورت زیر داشته باشیم: [[deprecated]] void print(const std::string &message) { std::cout << message << std::endl; } در صورتی که تابع print در بخشی از برنامه مورد استفاده قرار بگیرد، پیغامی از سمت کامپایلر از نوع اخطار (warning) ساطع میشود، مبنی بر آن که تابع مربوطه به عنوان منسوخ شده یاد شده است. warning: 'print' is deprecated این ویژگی میتواند در ساخت و توسعهٔ کتابخانهها، موتورها، چهارچوب (فریمورک) و برنامههایی که قرار است دیگر برنامهنویسان از آنها استفاده کنند بسیار میتواند کاربردی باشد؛ چرا که با اعمال چنین خاصیتهایی در کدهای شما برای توسعهدهندگان یادآوری خواهد شد که کد مربوطه در نسخهٔ جدید یا نسخههای بعدی امکان حذف و یا تغییر را خواهد داشت. #include <iostream> #include <string> [[deprecated]] void print(const std::string &message) { std::cout << message << std::endl; } int main() { print("Hello, World!"); return 0; } در مثال بالا اخطار پیشفرض از سمت کامپایلر ساطع میشود، اما در بعضی از مواقع لازم است پیغام سفارشی جهت راهنمایی بیشتر کاربر اعمال شود که در این صورت صفت میتواند پیغام از نوع رشته را دریافت و در هنگام ساطع شدن، آن را نمایش دهد. برای این کار کافی است متن مورد نظر را به صورت زیر در صفت خود تعیین کنیم. [[deprecated("Use printView with print instead, this function will be removed in the next release")]] برای مثال یک تابع جایگزین و بهینه شده را به صورت زیر در نظر بگیرید، کامپالر اخطار مروبطه و سفارشی شده را نسبت به آن ساطع خواهد کرد. #include <iostream> #include <string> [[deprecated]] void print(const std::string &message) { std::cout << message << std::endl; } void printView(std::string_view message) { std::cout << message << std::endl; } int main() { printView("Hello, World!"); return 0; } همچنین در رابطه با صفت [[noreturn]] که در استاندارد ۱۱ معرفی شده است، باید در نظر داشت این صفت جهت بهینهسازی کامپایلر در رابطه با تولید هشدارهای بهتر و همچنین اعلام اینکه تابع مربوطه قابل دسترسی نیست مورد استفاده قرار میگیرد. مثال: #include <iostream> [[noreturn]] void myFunction() { std::cout << "Hello, World!" << std::endl; throw "error"; } void print() { std::cout << "Print Now!"; } int main() { myFunction(); print(); return 0; } در کد فوق، در زمان همگردانی (کامپایل) پیغام زیر ساطع میشود: warning: code will never be executed بنابراین در زمان اجرا تابع print(); اجرا نخواهد شد، زیرا به عنوان یک کد غیر قابل دسترس بعد از myFunction توسط کامپایلر یاد میشود. چرا که این امر اجازه میدهد تا کامپایلر بهینهسازیهای مختلفی را انجام دهد - نیازی به ذخیرهسازی و بازیابی هرگونه حالتهای ناپایدار در اطراف صدا زننده (Caller) نیست. بنابراین میتواند کدهای غیر قابل دسترس را از بین ببرد. با توجه به نیازهای این چنینی، در استاندارد ۱۷ صفتهای جدیدتر و کاربردیتری نیز ارائه شده است که به معرفی هر یک از آنها در بخش اول از این مقاله میپردازیم. صفتهای معرفی شده در استاندارد 1z یا همان ۱۷ به صورت زیر هستند: [[fallthrough]] [[maybe_unused]] [[nodiscard]] معرفی صفت [[fallthrough]] به طور معمول در برنامهنویسی، هر وقت که مرحلهٔ مربوط به case در دستور switch به انتهای خود میرسد، کد مربوطِ به دستورِ case بعدی اجرا خواهد شد. طبیعتاً عبارت break میتواند از این امر جلوگیری کند. اما از آنجایی که این رفتار را به اصطلاح fall-through میشناسیم، ممکن است در صورت عدم معرفی اشکالاتی را فراهم کند، در این حالت چندین کامپایلر و ابزارهای آنالیز کننده خطای مرتبط به آن را هشدار میدهند تا کاربر در جریان قرار بگیرد. با توجه به این موضوع که ممکن است بعضاً این مورد چشم پوشی شود، در سیپلاسپلاس ۱۷ به بعد یک صفت استاندارد معرفی شد تا توسعهدهنده بتواند با قرار دادن آن در مکان سقوط (fall-through) به کامپایلر اعلام کند که هشداری در آن بخش لازم نیست. کامپایلرها میتوانند هشدارهای مطمئنی را در زمانی که یک عبارت case بدون اجرای دستور break به انتهای خود میرسند و یا سقوط (fall-through) میکند، حداقل با یک جملهٔ مربوطِ به آن را ساطع کند. برای مثال به کد زیر توجه کنید: #include <iostream> int main() { int number { 2017 }; int standard = {0}; switch(number) { case 2011: case 2014: case 2017: std::cout << "Using modern C++" << std::endl; case 1998: case 2003: standard = number; } return 0; } در کد فوق، در زمان اجرای دستور case سوم با مقدار ۲۰۱۷، کامپایلر هشداری به صورت زیر را اعمال خواهد کرد. warning: unannotated fall-through between switch labels در این حالت برای از بین بردن (چشمپوشی کردن) از این خطا در صورتی که نیاز نباشد موارد دیگر مورد بررسی قرار بگیرد قرار دادن دستور break بعد از آن میتواند منطقی باشد. اما با توجه به انتظاری که میرود تا دستورات بدون توقف بین آنها اجرا شود، قراردادن دستور [[fallthrough]]; بعد از آن میتواند راه حل بسیار مناسبی باشد. #include <iostream> int main() { int number { 2017 }; int standard = {0}; switch(number) { case 2011: case 2014: case 2017: std::cout << "Using modern C++" << std::endl; [[fallthrough]]; // > No warning case 1998: case 2003: standard = number; } return 0; } در این حالت، کامپایلر بدون ساطع کردن خطا آن را همگردانی خواهد کرد. معرفی صفت [[maybe_unused]] صفت [[maybe_unused]] برای نشان دادن کد ایجاد شدهای است که ممکن است از منطق قطعی استفاده نکند. این مورد ممکن است اغلب در لینک شدن با پیشپردازندهها مورد استفاده قرار بگیرد یا نگیرد. از آنجایی که کامپایلر (همگردانها) میتوانند نسبت به متغیرهای بلا استفاده هشدار ساطع کنند، این صفت روش بسیار خوبی برای سرکوب آنها خواهد بود. استفاده از این ویژگی میتواند در بخشهای مهمی مفید باشد، فرض کنید کتابخانهای نوشتهایم که قرار است به صورت چند-سکویی دارای ویژگیهای یکسان در بسترهای مختلف باشد. برای مثال ساخت یک فایل در مسیر مشخصی از سیستمعامل مورد نظر جهت اعمال تنظیمات نرمافزار. namespace FileSystem::Configuration { [[maybe_unused]] std::string createWindowsConfigFilePath(const std::string &relativePath); [[maybe_unused]] std::string createMacOSConfigFilePath(const std::string &relativePath); [[maybe_unused]] std::string createLinuxConfigFilePath(const std::string &relativePath); [[maybe_unused]] std::string createiOSConfigFilePath(const std::string &relativePath); [[maybe_unused]] std::string createAndroidConfigFilePath(const std::string &relativePath); } به کد بالا توجه کنید، در صورتی که شما در محیط کدنویسی در حال استفاده از یک دستور مورد نظر از بین دستورات بالا هستید، طبیعتاً کامپایلر به بقیهٔ دستوراتی که از آنها استفاده نمیکنید پیغامی مبنی بر آن که دستور مربوطه بلااستفاده مانده است را ساطع میکند. جهت جلوگیری از این هشدارها کافی است صفت [[maybe_unused]] را قبل از آنها اعمال کنید. معرفی صفت [[nodiscard]] در صورتی که از [[nodiscard]] استفاده شود، کامپایلر میتواند درک کند توابعی که مقدار بازگشتی دارند نمیتوانند مقدار بازگشت داده شدهٔ آنها را دور انداخت و یا از آنها در زمان صدا زدن صرف نظر کرد. بنابراین با تعریف این صفت در توابع از نوع بازگشتی میتوان پیغامی به صورت زیر را ساطع کند. مثال: #include <iostream> [[nodiscard]] int myFunction() { return 17; } int main() { myFunction(); return 0; } در مثال فوق تابع myFunction در زمان فراخوانی که مقدار بازگشتی آن بی نتیجه مانده است از سمت کامپایلر هشدار مورد نظر را دریافت خواهد کرد. این پیغام در صورتی که مقدار بازگشتی تابع به متغیری از هم نوعِ خودش ارسال شود، ساطع نخواهد شد. #include <iostream> [[nodiscard]] int myFunction() { return 17; } int main() { int func; func = myFunction(); return 0; }
-
معمولاً در سیپلاسپلاس برای چاپ اطلاعات مربوط به کد منبع از ماکروها استفاده میشود. ماکروها به عنوان یکی از ویژگیهای بسیار قدرتمند زبان C محسوب میشوند که در C++ نیز از آنها پشتیبانی میشود. برای مثال ماکروهای __LINE__ و __FILE__ اطلاعات مربوط به شماره خط، فایل و نام آن را بر میگردانند. در استاندارد جدید یعنی 2a یا همان نسخهٔ ۲۰ زبان، کلاس source_location معرفی شده است که در فایل سرآیند <source_location> تعبیه شده است. با دسترسی به فیلدهای line، column، filename و function_name میتوان تحت این کلاس مشخصات مورد نیاز را از کد منبع چاپ کرد. مثال : #include <iostream> #include <string_view> #include <source_location> void log(std::string_view message, const std::source_location& location = std::source_location::current()) { std::cout << "info:" << location.file_name() << ":" << location.line() << " " << message << '\n'; } int main() { log("Hello world!"); } خروجی کد مربوطه به صورت زیر است. info:main.cpp:15 Hello world! منبع در مرجع سیپلاسپلاس
-
اولین پلتفرم آموزشی چند منظورهٔ بومی اگر شما به دنبال فراگیری مهارت خاصی در زندگی خود هستید، فانوکس بستر مناسبی برای شما است؛ نام فانوکس الهام گرفته از فانوس دریایی است که نماد پیدا کردن مسیر و نور راهنما تا رسیدن به مقصد میباشد. هدف : آموزش و یادگیری هوشمند در هر زمان و هر جا برای بهبود زندگی و کسب و کار این تاپیک برای این منظور ایجاد شده است که پروژه معرفی و بازخوردهای آن در این بخش اعلام و اصلاح شوند. بنابراین تمامی دوستان و علاقهمندانی که بازخوردهایی برای آن دارند میتوانند در این بخش آن را اعلام کنند تا به کمک هم آن را اصلاح و توسعه دهیم. نکته: نسخهٔ ریلیز شده ویژگی ثبت خطاها را دارد که به شما اجازه میدهد کد و پیغام خطا را کپی و در اختیار ما قرار دهید. بنابراین شرط جاری روی مُد User و فلگهای Info، Warning، Failed و Critical نیز تنظیم شدهاند که میتوانید در صورت مشاهده آنها را تقسیم بندی کنید. if(DeveloperMode::IsEnable) { Logger::LoggerModel = Logger::Mode::User; Log("Log Message : " + Event , LoggerType::Info); Log("Log Message : " + Event , LoggerType::Warning); Log("Log Message : " + Event , LoggerType::Failed); Log("Log Message : " + Event , LoggerType::Critical); } پیش اطلاعات فنی انجین : سِل Cell رابط کاربری: JavaScript، QML و فناوری Qt Quick کتابخانهها : STL, OpenSSL, Curl و Qt سمت سرور: Php7.2 و MySQLi MariaDB (در آینده همین بخش رو هم احتمالاً با ++C توسعه بدم). رابطهای برنامهنویسی: Restful Api v.1.0 در قالب JSon نسخهٔ فعلی: ۰.۵ آلفا پلتفرمهای پشتیبانی دسکتاپ : Windows, macOS, Linux پلتفرمهای پشتیبانی موبایل و تبلت : iOS, Android, iPadOS معرفی در آیاواستریم نسخهٔ فعلی توسعه یافته : ۰.۵.۳۴۳.۰ ریلیز شده در سه حالت Normal, OpenGLEs و Software Mode هدف از این روش ریلیز این هست که سیستمهایی که دارای کارت گرافیکی ضعیفتر و یا بدون نصب کارت گرافیک و درایور آن هستند را تحت پوشش دهیم، بنابراین نسخهٔ Software Mode تنها مناسب برای سیستمهای اداری و مشابه آن هستند که عموماً خبری از کارت گرافیکی و یا درایورهای نصب شده بر روی آنها نیست ? دوستان توجه داشته باشند که برای بازخوردها و اعلام نظرات توسعه حتماً از مُد اجرای برنامهٔ خودشون و نوع سیستمعامل و شرایط سختافزاریشون مطلع باشند تا بتونیم به درستی مشکلات احتمالی را حل کنیم. در ادامه بعد از نظر نسخهٔ آلفا شروع به بررسی و حل مشکلات احتمالی در مسیر توسعه خواهیم کرد.
-
آغازی طوفانی برای پیاده سازی یک پیام رسان ساده بر پایه ++C
Max Base نوشته وبلاگ را ارسال کرد در برنامه نویسی
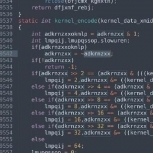
با سلام وقت بخیر, در این مطلب میخواهیم در مورد روش کارکرد پیام رسان ها بیشتر بدانیم و با یکدیگر کد یک پیام رسان ساده را پیاده و بررسی کنیم. طرز کار کرد پیام رسان در نظر داشته باشید که هر پیام رسانی که بر ساختار ها پیاده شده باشد از دو قسمت تشکیل شده است. نرم افزار اصلی برای مدیریت درخواست ها (سرور) نرم افزار برای کاربران (کاربر) به نرم افزار اولی سمت SERVER خواهیم گفت و به بعدی سمت CLIENT خواهیم گفت. روم یا تالار گفتگو ما تنها یک اتاق برای گفتگو در نظر میگیریم و هر کاربری که به سرور متصل شود را در همان تالار اضافه خواهیم کرد. تالار های گفتگو صرفا برای تقکیک سازی ارسال و دریافت ها و محدود کردن بازه ی کاربران مورد نظر... (ممکن است یک کاربر در چند اتاق بطور همزمان باشد.) سیستم های پیام رسان پیشرفته تر مانند تلگرام و ... تالار های زیادی را شامل می شوند. (هر کاربر خودش در کانال و گروه های مختلفی عضو است که هر کدام از آنها یک کانال متفاوت محسوب می شوند.) * دقت شود که منظور از کانال صرفا یک اتاق یا تالار گفتگو است و منظور کانال ارتباطی و پروتکل نیست. نرم افزار اصلی نرم افزار اصلی وظیفه دارد تا تمام کاربرانی که وارد تالار شده اند را به یاد داشته باشد و هر لحظه اماده دریافت درخواست هایی از طرف کاربرانش باشد. و پیام هایی را که از کاربران دریافت می کند برای تمامی کاربران دیگر هم ارسال کند که بسته به خلاقیت و نیاز می تواند هر یک از این بخش ها متفاوت طراحی شود. نرم افزار اصلی باید از قبل اجرا شده باشد. تا کاربران دیگر با استفاده از نرم افزار مخصوص به خودشان بتوانند به سرور متصل شوند و ارسال و دریافت داشته باشند. در نظر داشته باشید که اگر در نرم افزار اصلی اختلالی پیش بیایید و متوقف بشوند. قطا برای تمام کاربران مشکل پیش می آید. مگر اینکه از پایگاه های داده ی داخلی استفاده کرده باشند. (با خلاقیت می توان به گونه های متفاوتی چنین ساختاری را پیاده کرد) نرم افزار کاربران این نرم افزار جذاب ترین بخش است چرا تمام قابلیت هایی را که در اختیار کاربر قرار می دهیم را مستقیما طراحی می کنیم. در نظر داشته باشید که هر چیزی که در این نرم افزار طراحی می شود باید در نرم افزار اصلی پشتیبانی شوند... بنابراین اگر این دو بخش توسط دو فرد یا دو گروه مجزا طراحی می شوند آنها باید توسط داکیومنت ها و جلساتی به نظرات مشابه ای رسیده باشند. (اگرچه اینها تخصص و وظیفه ی تحلیلگر سیستم است! نه بطور همزمان وظیفه توسعه دهنده و برنامه نویس نرم افزار) پیاده سازی یک نمونه اکنون در نظر داریم تا با استفاده از ساختار کتابخانه BoostAsio پروژه ای را با نام BoostAsioChat ایجاد کنیم که در آن می خواهیم یک پیام رسان با حداقل ترین امکانات پایه طراحی کنیم که بیشتر جنبه شخصی و تفریحی دارد. زیرا از ساختار های استاندارد و ایمن و کاربری کاملا بدور است! (می توانید خودتان توسعه دهید و آنرا جالب تر بسازید) ساختار نرم افزار اصلی و سرور را به این صورت تعریف می کنیم : typedef deque<message> messageQueue; class participant { public: virtual ~participant() {} virtual void deliver(const message& messageItem) = 0; }; typedef shared_ptr<participant> participantPointer; class room { public: void join(participantPointer participant); void deliver(const message& messageItem); void leave(participantPointer participant); private: messageQueue messageRecents; enum { max = 200 }; set<participantPointer> participants; }; class session : public participant, public enable_shared_from_this<session> { public: session(tcp::socket socket, room& room) : socket(move(socket)), room_(room); void start(); void deliver(const message& messageItem); private: void readHeader(); void readBody(); void write(); tcp::socket socket; room& room_; message messageItem; messageQueue Messages; }; class server { public: server(boost::asio::io_context& io_context, const tcp::endpoint& endpoint) : acceptor(io_context, endpoint); private: void do_accept(); tcp::acceptor acceptor; room room_; }; int main(int argc, char* argv[]); ساختار نرم افزار کاربر را هم به این صورت تعریف می کنیم : typedef deque<message> messageQueue; class client { public: client(boost::asio::io_context& context, const tcp::resolver::results_type& endpoints) : context(context), socket(context); void write(const message& messageItem); void close(); private: void connect(const tcp::resolver::results_type& endpoints); void readHeader(); void readBody(); void write(); boost::asio::io_context& context; tcp::socket socket; message readMessage; messageQueue writeMessage; }; int main(int argc, char* argv[]); در نظر داریم تا در این پروژه از thread ها نیز استفاده کنیم... در مورد این مفهوم ها می توانید بصورت مجزا تحقیق کنید. بنابراین روش کامپایل این پروژه به این صورت خواهد بود : $ g++ client.cpp -lpthread -o client $ g++ Server.cpp -lpthread -o server آزمایش همانطور که گفته شد در ابتدا نرم افزار اصلی و سرور باید اجرا شود. در اینجا ما تمام ارتباطات شبکه را بر روی یک سیستم در شبکه داخلی برقرار خواهیم کرد... پس نگرانی در مورد ساختار های درونی شبکه و آی پی / دی ان اس / دامین نخواهیم داشت. بنابراین ای پی را می توانید ای پی داخلی یا localhost در نظر بگیرید. برای آزمایش پورت فرضی 4000 را در نظر میگیریم و نرم افزار اصلی را روی این پورت اجرا میکنیم : $ ./server 4000 در این مرحله متوجه می شوید که نرم افزار اصلی با موفقیت اجرا شده است و همچنان اجرا مانده است. بله درست است... نرم افزار اصلی هر لحظه باید منتظر دستور کاربران باشد. اگر لحظه ای برای نرم افزار اصلی اختلالی پیش آید نخواهد توانست دستورات کاربران را انجام یا پاسخ دهد. بنابراین این پردازش را قطع نکنید و اجازه دهید تا نرم افزار اصلی اجرا بماند. در محیط دیگری نرم افزار سمت کاربر را نیز اجرا کنید. این نرم افزار را می توانید به تعداد دلخواه وارد کنید. (همانطور که ممکن است 6 نفر همزمان به سرور متصل باشند / یا ممکن است هیچ فردی به سرور متصل نشوند) ابتدا یک کاربری را به سرور با پورت 4000 و شبکه داخلی وصل می کنیم : $ ./client localhost 4000 first user: you can type message here... حال در محیط دیگری با کاربر جدیدی نیز وارد می شویم : $ ./client localhost 4000 second user: you can type message here... در این پروژه نمونه از کاربران نام کاربری یا نام نمی پرسیم.. و صرفا وقتی وارد محیط گفتگو می شوند... یا زمانی که به سرور متصل می شوند منتظر هستیم تا انها پیامی را بنویسند... هر پیامی را که بنویسند به سرور ارسال می شود و سرور وظیفه دارد تا آنرا برای تمام کاربران بفرستد. و این روند درون یک حلقه بی نهایت تکرار می شوند. پس این ارتباط دو طرفه خواهد بود و هم کاربران برای سرور اطلاعات ارسال می کنند و هم سرور برای کاربران اطلاعات ارسال خواهد کرد. در نظر داشته باشید که کاربر اول می تواند پیامی را بنویسد و به کاربران دیگر ارسال شود. ممکن است کاربر سومی اصلا تصمیمی به نوشتن پیام نداشته باشد و صرفا تمایل به خواندن پیام دیگران داشته باشند. و این کاملا اختیاری است. و ما کاربران را اجباری نمیکنیم. اگرچه شما می توانید با خلاقیت خودتان اینها را با متغییر های کمکی و دستورات شرطی پیاده کنید. کد ها برای پیام ها یک ساختار در نظر میگیریم و بصورت مشترک در هر دو نرم افزار استفاده خواهیم کرد... بنابراین اینرا در هدر پیاده خواهیم کرد. هدر پیام : (message.hpp) #ifndef message_HPP #define message_HPP #include <cstdio> #include <cstdlib> #include <cstring> using namespace std; class message { public: enum { headerLength = 4 }; enum { maxBodyLength = 512 }; message() : bodyLength_(0) { } const char* data() const { return data_; } char* data() { return data_; } size_t length() const { return headerLength + bodyLength_; } const char* body() const { return data_ + headerLength; } char* body() { return data_ + headerLength; } size_t bodyLength() const { return bodyLength_; } void bodyLength(size_t new_length) { bodyLength_ = new_length; if(bodyLength_ > maxBodyLength) bodyLength_ = maxBodyLength; } bool decodeHeader() { char header[headerLength + 1] = ""; strncat(header, data_, headerLength); bodyLength_ = atoi(header); if(bodyLength_ > maxBodyLength) { bodyLength_ = 0; return false; } return true; } void encodeHeader() { char header[headerLength + 1] = ""; sprintf(header, "%4d", static_cast<int>(bodyLength_)); memcpy(data_, header, headerLength); } private: char data_[headerLength + maxBodyLength]; size_t bodyLength_; }; #endif نرم افزار اصلی و سرور : (server.cpp) #include <iostream> #include <cstdlib> #include <deque> #include <memory> #include <list> #include <set> #include <utility> #include <boost/asio.hpp> #include "message.hpp" using boost::asio::ip::tcp; using namespace std; typedef deque<message> messageQueue; class participant { public: virtual ~participant() {} virtual void deliver(const message& messageItem) = 0; }; typedef shared_ptr<participant> participantPointer; class room { public: void join(participantPointer participant) { participants.insert(participant); for(auto messageItem: messageRecents) participant->deliver(messageItem); } void deliver(const message& messageItem) { messageRecents.push_back(messageItem); while(messageRecents.size() > max) messageRecents.pop_front(); for(auto participant: participants) participant->deliver(messageItem); } void leave(participantPointer participant) { participants.erase(participant); } private: messageQueue messageRecents; enum { max = 200 }; set<participantPointer> participants; }; class session : public participant, public enable_shared_from_this<session> { public: session(tcp::socket socket, room& room) : socket(move(socket)), room_(room) { } void start() { room_.join(shared_from_this()); readHeader(); } void deliver(const message& messageItem) { bool write_in_progress = !Messages.empty(); Messages.push_back(messageItem); if(!write_in_progress) { write(); } } private: void readHeader() { auto self(shared_from_this()); boost::asio::async_read(socket, boost::asio::buffer(messageItem.data(), message::headerLength), [this, self](boost::system::error_code ec, size_t) { if(!ec && messageItem.decodeHeader()) { readBody(); } else { room_.leave(shared_from_this()); } }); } void readBody() { auto self(shared_from_this()); boost::asio::async_read(socket, boost::asio::buffer(messageItem.body(), messageItem.bodyLength()), [this, self](boost::system::error_code ec, size_t) { if(!ec) { room_.deliver(messageItem); readHeader(); } else { room_.leave(shared_from_this()); } }); } void write() { auto self(shared_from_this()); boost::asio::async_write(socket, boost::asio::buffer(Messages.front().data(), Messages.front().length()), [this, self](boost::system::error_code ec, size_t) { if(!ec) { Messages.pop_front(); if(!Messages.empty()) { write(); } } else { room_.leave(shared_from_this()); } }); } tcp::socket socket; room& room_; message messageItem; messageQueue Messages; }; class server { public: server(boost::asio::io_context& io_context, const tcp::endpoint& endpoint) : acceptor(io_context, endpoint) { do_accept(); } private: void do_accept() { acceptor.async_accept([this](boost::system::error_code ec, tcp::socket socket) { if(!ec) { make_shared<session>(move(socket), room_)->start(); } do_accept(); }); } tcp::acceptor acceptor; room room_; }; int main(int argc, char* argv[]) { try { if(argc < 2) { cerr << "Usage: server <port> [<port> ...]\n"; return 1; } boost::asio::io_context io_context; list<server> servers; for(int i = 1; i < argc; ++i) { tcp::endpoint endpoint(tcp::v4(), atoi(argv[i])); servers.emplace_back(io_context, endpoint); } io_context.run(); } catch (exception& e) { cerr << "Exception: " << e.what() << "\n"; } return 0; } نرم افزار دوم و سمت کاربر : (client.cpp) #include <iostream> #include <thread> #include <cstdlib> #include <deque> #include <boost/asio.hpp> #include "message.hpp" using boost::asio::ip::tcp; using namespace std; typedef deque<message> messageQueue; class client { public: client(boost::asio::io_context& context, const tcp::resolver::results_type& endpoints) : context(context), socket(context) { connect(endpoints); } void write(const message& messageItem) { boost::asio::post(context, [this, messageItem]() { bool write_in_progress = !writeMessage.empty(); writeMessage.push_back(messageItem); if(!write_in_progress) { write(); } }); } void close() { boost::asio::post(context, [this]() { socket.close(); }); } private: void connect(const tcp::resolver::results_type& endpoints) { boost::asio::async_connect(socket, endpoints, [this](boost::system::error_code ec, tcp::endpoint) { if(!ec) { readHeader(); } }); } void readHeader() { boost::asio::async_read(socket, boost::asio::buffer(readMessage.data(), message::headerLength), [this](boost::system::error_code ec, size_t) { if(!ec && readMessage.decodeHeader()) { readBody(); } else { socket.close(); } }); } void readBody() { boost::asio::async_read(socket, boost::asio::buffer(readMessage.body(), readMessage.bodyLength()), [this](boost::system::error_code ec, size_t) { if(!ec) { cout.write(readMessage.body(), readMessage.bodyLength()); cout << "\n"; readHeader(); } else { socket.close(); } }); } void write() { boost::asio::async_write(socket, boost::asio::buffer(writeMessage.front().data(), writeMessage.front().length()), [this](boost::system::error_code ec, size_t) { if(!ec) { writeMessage.pop_front(); if(!writeMessage.empty()) { write(); } } else { socket.close(); } }); } boost::asio::io_context& context; tcp::socket socket; message readMessage; messageQueue writeMessage; }; int main(int argc, char* argv[]) { try { if(argc != 3) { cerr << "Usage: client <host> <port>\n"; return 1; } boost::asio::io_context context; tcp::resolver resolver(context); auto endpoints = resolver.resolve(argv[1], argv[2]); client c(context, endpoints); thread t([&context](){ context.run(); }); char line[message::maxBodyLength + 1]; while(cin.getline(line, message::maxBodyLength + 1)) { message messageItem; messageItem.bodyLength(strlen(line)); memcpy(messageItem.body(), line, messageItem.bodyLength()); messageItem.encodeHeader(); c.write(messageItem); } c.close(); t.join(); } catch (exception& e) { cerr << "Exception: " << e.what() << "\n"; } return 0; } این پروژه آزمایشی بصورت رایگان و اوپن سورس در اینترنت بخصوص اینجا وجود دارد و می توانید آنرا مستقیما بصورت کامل دانلود کنید. با تشکر, Max Base / مکس بیس -
منتور چیست؟ منتور (Mentor) به افرادی میگویند که در یک زمینهٔ خاصی تخصص، تسلط و تجربه دارند و در آن زمینه کارشناس و صاحب نظر هستند و میتوانند به دیگران در یادگیری آن کار کمک کنند. منتور یک رابطه ارگانیک و دوستانه با افراد جوانتر تحت سرپرستی خود برقرار میکند و نه تنها در مورد دروس دانشگاهی بلکه در خصوص مشاغل و مشکلات فرهنگی، اجتماعی و روحی و روانی آنان را یاری می دهد. همهٔ ما در زندگیمان فردی را ملاقات کردهایم که هم نشینی و هم صحبتی با او برای زندگی ما اهمیت داشته است. برای مثال، این فرد میتواند یکی از معلمهای ما و یا یکی از اعضای خانواده باشد. چنین فردی را می توان منتور نامید. خصوصیات و وظایفی که منتور دارد سابقه کار قابل توجه علاقهمند به آموزش و انتقال تجربیات خود به دیگران دارای تجربهٔ شکست و موفقیت دارای ارتباطات قابل توجه سابقهٔ کار در تیمهای استارتآپی آگاه به مسائل استارتآپی اهل دانش دانش و تجربیات زندگی خود را به اشتراک میگذارد توصیه میکند و مشاوره میدهد گوش میدهد الهام میبخشد تشویق میکند با علاقه به سؤالات و نگرانیهای فرد پاسخ میدهد صادق و انتقادپذیر است راجع به هدفگذاری بحث میکند در مورد رشد شغلی و حرفهای مشاوره میدهد منابع را شناسایی میکند به رشد مهارتهای مدیریت و رهبری کمک میکند برای رشد فرهنگ سازمانی تلاش میکند میتواند باعث شفافیت در سازمان شود رزومهها را بررسی میکند نکتههای کلیدی برای مصاحبه را تعیین میکند حمایت کننده است ممکن است فرد را به اشخاص کاربلد دیگری ارجاع دهد فرد را به چالش میکشد تا از حوزهٔ امن خودش بیرون بیاید یک محیط یادگیری ایمن برای ریسک کردن ایجاد میکند روی رشد همهجانبهٔ فرد تمرکز دارد مزایایی که یک منتور میتواند داشته باشد پژوهشها نشان داده است که کسانی که از وجود منتور بهره بردهاند، احساس رضایت بیشتری نسبت به شغل خود دارند. علاوه براین، این افراد اغلب اوقات عملکرد بالاتری پیدا کردهاند، حقوق بالاتری میگیرند و روند پیشرفتشان در شغل سریعتر است. او بازار را به خوبی میشناسد و رفتار با مشتری را به شما میآموزد. او چشماندازی بزرگ دارد و صحبت با او چشمانداز شما را بهبود میدهد. راه و چاه را از هم شناخته و شما را با برخی اشتباهات فاحشی آشنا میکند که نبایدانجام دهید. او شبکهای بزرگ از کارآفرینان، سرمایهگذاران و مسوولین دارد که میتوانید واقعاً روی آن حساب کنید. خود او شاید در مقام یک فرشته کسبوکار روی کسبوکار شما سرمایهگذاری کند. شما گاهاً درگیر امور اجرایی جزئی میشوید و از بحثهای کلانی مثل استراتژی کسبوکارتان دور میشوید. او کسبوکار را از بیرون میبیند و مسیر نادرست را گوشزد میکند. او فردی موفق است و باانگیزه. پس در مراحل سخت و خشن راهاندازی کسبوکار در ایران به شما روحیه و انگیزه مضاعف میدهد. به طور کلی، حوزهٔ فعالیتهای منتورها را در دو گروه میتوان دستهبندی کرد؛ حوزهٔ شغلی (حرفهای) و حوزهٔ روانشناختی. در حوزهٔ حرفهای، منتور تلاش میکند تا به عنوان یک مربی به فرد توصیههایی داشته باشد و رشد و عملکرد حرفهای او را بالا ببرد. در حوزهٔ روانشناختی، منتور به عنوان یک الگو ایفای نقش میکند و به عنصر الهامبخش تبدیل میشود. این دو حوزه معمولاً همزمان اتفاق میافتند و به فرد این امکان را میدهند تا علاوه بر پیشرفت در حوزهٔ شغلی، توازنی مناسب بین شغل و زندگی شخصی برقرار سازد. دانش، توصیه و منابعی که منتور با فرد در میان میگذارد بستگی به اهداف رابطهٔ منتورینگ دارد. ممکن است منتور اطلاعاتی را راجع به مسیر شغلی خود به فرد بدهد یا بیشتر به دنبال پشتیبانی کردن احساسی، دادن انگیزه و بازی کردن نقش یک الگو باشد. کمک به کشف ظرفیتهای جدید در هر شغل، هدفگذاری صحیح و شناسایی منابع نیز میتواند در حوزهٔ عملکرد منتور قرار بگیرد. نقش منتور با توجه به نیاز فرد تغییر میکند. بعضی از رابطههای منتورینگ بر اساس برنامههایی ساختاریافته و منظم بنا شدهاند که انتظارات و دستورالعملهای مشخصی دارند ولی بعضی دیگر، حالتی غیررسمی دارند. نکته: همانطور که انتخاب یک منتور خوب مزایای بسیاری در رُشد فردی و موفقیت کسبوکار شما دارد؛ به همان اندازه انتخاب یک منتور نا مناسب و بد تاثیر منفی خواهد داشت. توجه: منتورینگ خود به عنوان یک شغل نیز محسوب میشود، همانگونه که مشاوره مهم است! استفاده از تجربیات یک مشاور کسبوکار و فنی ارزش بسیاری دارد و بدون شک بسیار مهم خواهد بود. بنابراین منتورینگ متناسب با نوع استارتآپ و مشارکتی که در رُشد آن دارد هزینه یا سهمی را برای آن مشخص میکند و در توسعهٔ فردی و یا استارتآپ به وظایف خود عمل میکند. منتور فنی یا منتور کسبوکار!؟ لازم به ذکر است در رابطه با این موضوع روشن سازی شود که منتور کسبوکار میتواند راه و روش توسعهٔ کسبوکار شما را بهبود داده و برای شما مشاورههای مفیدی در این زمینه ارائه دهد. در مقابل منتور فنی میتواند با در نظر گرفتن مسیری که منتور کسبوکار برای شما مشخص کرده است راه و روش صحیح توسعهٔ محصول و استارتآپ شما را از لحاظ فنی ارائه دهد. یک منتور فنی میتواند صاحب نظر در حوزهٔ کسبوکار نیز باشد (این بستگی به تجربیات استارتآپی و کسبوکار آن خواهد داشت). بهرهگیری از هر دو نوع منتور در رشد فردی و استارتآپی شما بسیار موثر خواهد بود. خلاصهای از تعریف منتور منتور کسی است که همانند یک فانوس دریایی مسیر موفقیت و شکست را در هر شرایطی برای شما روشن سازد.
-
سیستم مدیریت محتوا
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #e62f3d; color: #ffffff;" >برنامه نویسی در C و ++C</span>
آیا این واقعاً امکانپذیر است؟ پاسخ : بله! من میدانم که ممکن است این مبحث تحت سی++ بسیار پیچیده و یک کار بیهودهای باشد! اما واقعیت این است که تکنیکهای پنهان بسیاری وجود دارد که ممکن است همه از آن باخبر نباشند! من قبلاً در مورد اینکه تحت ++C وبسایت میشه طراحی کرد یا خیر تحقیقاتی انجام داده بودم، از لحاظ امکان بودنش جواب مثبت بود اما اینکه به راحتی طراحی تحت Php یا دیگر زبانهای برنامهنویسی باشه خیر! خُب طبیعیه چون شما بسیار راحت یه اسکریپت رو مینویسی و روی سرور اجراش میکنی و سایت شما به خوبی و خوشی بالا میاد! ممکن است در همین قسمت از موضوع شما به این نتیجه رسیده باشید که خُب نیازی به ادامهٔ بحث نداریم! وقتی کار سختیه پس منطقی نیست و شما احتمالاً دیوانهای!!! ? واقعیت جریان این است بر خلاف آن چیزی که تصور کردهایم طراحی وبسایت با سیپلاسپلاس نه تنها بسیار راحت است بلکه بسیار هم جذاب خواهد بود! اما در نگاه اول ممکن است یک سری محدودیتهارا داشته باشد که همهٔ این موارد با کمی تأمل و بررسی قابل حل هستند به قدری که وقتی درگیر این جریان باشید شیفتهٔ آن خواهید شد. مزایای یک وبسایت تحت سیپلاسپلاس نسبت به دیگر زبانهای رایج سرعت خارقالعاده و غیر قابل مقایسه با زبانهای رایج امنیت بهتر کدهای شما مدیریت سادهتر و انعطافپذیری بالا مصرف بسیار بهینه و غیر قابل تصور از منابع سرور دسترسی نامحدود به کتابخانهها عدم محدودیت در دسترسی به برنامهنویسی سطح پایین عدم محدودیت در استفاده از توابع سیستمعامل عدم محدودیت در مدیریت سیستم و هر ویژگی دیگری که در زبانهای اسکریپتی اگر به آن نیاز داشته باشید مجبور هستید تا به صورت اکستنشن آن را تحت سیپلاسپلاس باز نویسی کنید. سیستم راهانداز وبسرور چگونه است؟ در هر سروری CGI به شما امکان این را میدهد که بتوانید تحت پروتکلهای استاندارد برنامههای تحت وب را اجرا کنید. شما میتوانید تحت آن و یا موارد دیگری مانند FastCGI و WSGI و دیگر موارد بهینه شدهٔ آن برنامهٔ تحت وب را بر روی سرور خود اجرا کنید. طراحی قالب هماهنگی با HTML, JavaScript, Css در سیپلاسپلاس چگونه خواهد بود؟ همهٔ گزینههای مربوط به وب را شما بدون هیچ محدودیتی در اختیار خواهید داشت. شما هیچ محدودیتی در استفاده از ویژگیهای HTML5 یا CSS3 و یا JavaScript و دیگر فریمورکها و کتابخانههای کارآمدی چون Angular.JS را نخواهید داشت. بنابراین از نظر طراحی رابط یک وبسایت همانند دیگر زبانهای رایج میتوانید روی آن حساب کنید. طراحی هسته و بکاِند وبسایت چگونه خواهد بود؟ همانند زبانها و فریمورکهای رایج تحت وب شما در سیپلاسپلاس میتوانید هستهٔ وبسایت یا سیستم وبسایت خود را تحت استاندارد سیپلاسپلاس و هر کتابخانهای که میپسندید و یا به آن تسلط دارید پیاده سازی کنید! به شرطی که قابلیتهای آن کتابخانه پاسخگوی نیازهای شما باشد. با این حساب شما میتوانید حتی سیستم مدیریت محتوای (CMS) خود را طراحی کنید! ? بله سیستم مدیریت محتوا تحت سیپلاسپلاس! کاملاً جدی هستیم ? قبل از هر چیز یک مزیت بسیار بزرگ در کنار مزیتهای دیگر این است که یک CMS تحت سیپلاسپلاس میتواند داشته باشد مصرف بهینه از منابع سرور خواهد بود. برای مثال در یک مقایسهٔ ساده و آزمایشی نتیجهٔ بسیار جالبی ارائه شده است. همانطور که میدانید Wordpress به عنوان یک سیستم مدیریت محتوای (بلاگ) شناخته شده و تحت Php توسعه یافته است. نسخهٔ سریعتر و بهینهتر آن با نام Ghost تحت Node.JS توسعه یافته است که ما نسخهٔ توسعه یافتهٔ آن را با یک عمل مشابه در C++1z مورد بررسی قرار داده ایم که نتایج آن بسیار جالب است! مصرف حافظه سیستم مدیریت محتوای Tegra ۳۵۰۰ درخواست در هر ثانیه 3.6 مگابایت سیستم مدیریت محتوای Ghost 100 درخواست در ثانیه 120 مگابایت پشتیبانی از پایگاههای داده به لطف کتابخانههای عظیم سیپلاسپلاس امکان مدیریت یک وبسایت تحت پایگاههای داده مختلفی ممکن است. برای مثال تحت Qt شما میتوانید به رایجترین درایورهای بانکاطلاعاتی دسترسی داشته و سیستم خود را به آنها مجهز کنید. نکته: احتمالاً در برنامهنویسی با نود جیاس و پیاچپی شناختی با کتابخانههای OpenSSL, Libcurl و موارد این چنینی داشته اید! کتابخانههای فوق عضو لیست کتابخانههای C و ++C هستند. بنابراین شما علاوه بر دسترسی مستقیم بر آنها به هزاران و شاید میلیونها کتابخانه در دنیا سیپلاسپلاس خواهید داشت. نمونهٔ اولیه اما شوقآور برای اثبات امکان طراحی وبسایت تحت سیپلاسپلاس چندی پیش من تصمیم گرفتم تا سیستم وبسایتی را تحت Php7 برای یکی از استارتآپها طراحی و پیاده سازی کنم که در این پست به آن اشاره شده است. از آنجایی که به لطف کتابخانهٔ Qt برنامههای سمت کاربر را توسط سیپلاسپلاس پیاده سازی کرده بودم به این فکر افتادم چرا سمت سرور و بخش وبسایت هم با آن هماهنگ نشود!؟ اینگونه هماهنگی بین برنامهها و پرفرمنس همهٔ آنها بسیار افزایش خواهد یافت در اولین نگاه این تفکر بسیار ناشیانه و بسیار ناممکن بود! تنها روشی که به کار گرفته بودم ارسال اطلاعات از طرف کاربر به سمت سرور و مدیریت آنها تحت معماری Restful Api بود که در قالب JSon آنها را تجزیه و مدیریت میکردم. با کمی تحقیق در مورد ویژگیهای سمت وب تحت Fast-CGI, uWSGI, DJango, ClearSilver و موارد مرتبط با آنها سعی کردم تا صفحهٔ بسیار سادهای از HTML را توسط سیپلاسپلاس هندل کنم. این کار نتایج بسیار موفقیت آمیزی را در بر داشت تا نتیجهٔ آن تبدیل به یک پروژهٔ سیستم مدیریت محتوا تحت ++C شد. من پروژهای با نام مفهومی Tegra که نام پروژهٔ قبلی تحت Php بود را در محیط Qt Creator با C++17 و کتابخانهٔ Qt باز سازی کرده و هستهٔ اولیهٔ آن را برای اجرای چند صفحه از یک وبسایت، احراز هویت، بازخوانی و نمایش لیستی از خبرها و مدیریت متا تگها و آدرس صفحات مربوط به هر صفحه را ایجاد کردم. سعی کرده ام در کمترین زمان ممکن برای آزمایش یک سری ویژگیهای اولیه از یک وبسایت آنها را مورد بررسی قرار بدم که عبارتند از هماهنگی با فریمورکهای طراحی مانند BootStrap و یا Angular.JS که خوشبختانه همهچیز بسیار خوب در کنار همدیگه کار میکنند. هستهٔ سیستم به صورت جدا و معماری طراحی آن بر پایهٔ MVC مورد آزمایش قرار گرفته است. در زیر تصاویری از صفحات تولید شده تحت سیستم مدیریت محتوای ساخته شده با سیپلاسپلاس را مشاهده میکنید. ? همه چیز در قدمهای اول قرار دارد و با توجه به سادگی تولید وب سایت بر خلاف تصوری که داشتیم بسیار توسعه و جای پیشرفت خواهد داشت. بخشی از نمونه کدهای این سیستم به صورت زیر آورده شده است تا ذهنیتی برای توسعهدهندگان ارائه شود: تکه کُد زیر عمل ارسال اطلاعات و تمامی لینکهای مربوط به بوت استرپ را برای سمت HTML ارائه میکند که در قالب استاندارد جدید C++17 آورده شده است: auto bootstrapCss = bootStrapLib.find("css"); if(bootstrapCss != bootStrapLib.end()) { c->setStash("BootstrapCss", bootstrapCss->second.c_str()); std::cout << "Found " << bootstrapCss->first << " " << bootstrapCss->second << '\n'; } کد مربوط به سمت قالب به صورت زیر خواهد بود: <!-- Bootstrap core css --> <link href="{{BootstrapCss}}" rel="stylesheet"> نتیجهٔ فوق در صورتی که CDN بر روی لوکال تنظیم شده باشد از روی کدهای کامپایل شده و یا استاتیک فراخوانی خواهد شد. در غیر اینصورت از روی یکی از سرورهای CDN فراخوانی میشوند. نحوهٔ ارسال متغیر از سمت سیپلاسپلاس به قالب بسیار ساده است! بسیار ساده از Php و یا Node.JS میباشد. با در نظر گرفتن ارسال اطلاعات از سمت سیپلاسپلاس به سمت رابط کاربری کافی است نام متغیرها را در قالب خود اعمال کنید. {% for post in news %} <div class="blog-post"> <h2 class="blog-post-title"><a href="news/{{post.uri}}">{{post.title}}</a></h2> <p class="blog-post-meta">{{post.date}} by <a href="#">{{post.author}}</a></p> <p>{{post.announcement|safe}}</p> </div><!-- /.blog-post --> {% endfor %}</div> این ساختار بر پایهٔ ساختار Angular.JS و DJango پیاده سازی شده است که به طور کامل پشتیبانی میشود. فعال سازی فناوری Angular.JS بر روی این سیستم جهت طراحی قالب تنها با دو دستور ساده اعمال میشود: <!-- Link to AngularJS --> <script src= "{{AngularJs}}"></script> <!-- Enable AngularJS Engine --> {{AngularJsSync|safe}} این دستورات در هستهٔ سیستم مدیریت محتوا در کلاسی با نام Template پردازش و در نهایت به سمت HTML هندل میشوند. بخشی از دستورات سمت هسته در سیپلاسپلاس ۱۷ برای مثال ارسال عنوان صفحه به صورت زیر است: std::optional<std::string> LoadListTemplate::getTitle() const { if (isset(title)) { return title; } else { return std::nullopt; } } سمت HTML کافی است دستور فوق را در نظر بگیریم: <title>{{title}}</title> اینها مثالهایی از مراحل توسعهٔ این سیستم است که میدانم آنچنان گسترده نیست، اما برای ثابت کردن طراحی و توسعهٔ وبسایت تحت سیپلاسپلاس مثالهای روشنی هستند. موفق و سربلند باشید! اطلاعیههای مربوط به این پروژه احتمالاً در کانالها و گروه تلگرامی و همین مرجع بازگو و در اختیار شما قرار گیرد. -
در این ویدیو آموزش تهیه خروجی برنامه در Qt رو یاد خواهید گرفت. لینک دانلود فایل دانلود
-
با سلام و خسته نباشید. اگر امکانش باشه یه آموزش به صورت پروژه محور در مورد QThread در GUI تهیه کنید. آموزش های سطح اینترنت بسیار ساده هستش و از سیگنال و اسلات بسیار کم استفاده شده. ممنون بابت سایت خوبتون
-
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #e62f3d; color: #ffffff;" >برنامه نویسی در C و ++C</span>
مراحل ساخت برنامه در زبان سیپلاسپلاس پیش نویس ۰.۶ قبل از هر چیز به اینفوگرافی زیر توجه کنید که مراحل ساخت برنامه در سیپلاسپلاس را نشان میدهد. مقدمهای بر همگردانی (کامپایل) و اتصال (لینک کردن) این سند مرور مختصری در رابطه با مراحل را برای شما فراهم میکند تا به شما در درک دستورات مختلف برای تبدیل و اجرای برنامهٔ خودتان کمک کند. تبدیل مجموعهای از فایلهای منبع و هدر در سیپلاسپلاس به یک فایل خروجی و اجرایی در چندین گام (به طور معمول در چهار گام) پیشپردازنده (Preprocessors)، کامپایل و گردآوری (Compilation)، اسمبلر (Assmbler) و پیوند دهنده (Linker) تقسیم میشود. قبل از هر چیز اگر در محیط توسعهٔ Qt Creator داخل فایل .pro مقدار زیر را وارد کنید، تا بتوانید فایلهای ساخته شدهٔ موقت در زمان کامپایل را مشاهده کنید. QMAKE_CXXFLAGS += -save-temps این دستور اجازهٔ آن را خواهد داد تا فایلهایی با پسوند .ii و .s در شاخهٔ بیلد پروژه تولید شوند که در ادامه به آنها اشاره شده است. تعریف پیشپردازنده پیشپردازندهها (Preprocessors) درواقع دستوراتی هستند که اجازه میدهند تا کامپایلر قبل از آغاز کردن مراحل کامپایل دستوراتی را دریافت کند. پیشپردازندهها توسط هشتگ (#) مشخص میشوند این نماد در سی++ مشخص میکند که دستور فوق از نوع پیشپردازنده میباشد که نتیجهٔ آن در قالب ماکرو (Macro) در دسترس خواهد بود. برای مثال ماکروی __DATE__ توسط پیشپردازندهها از قبل تعریف شده است که مقدار تاریخ و زمان را بازگشت میدهد. بنابراین هرکجا که از آن استفاده شود کامپایلر آن را جایگزین متن خواهد کرد. در شکل زیر مرحلهای که از پیشپردازندهها استفاده میشود آمده است: پیشپردازنده، کامپایل (گردآوری کردن)، لینک (پیوند کردن) و ساخت برنامه اجرایی فرایند تبدیل مجموعهای از فایلهای متنی هِدر و سورس سی++ را «ساخت» یا همان Building میگویند. از آنجایی که ممکن است کُد پروژه در بسیاری از فایلها هدر و سورس سی++ توسعه و گسترش یابدمراحل ساخت در چند گام کوچک صورت میگیرد. یکی از رایجترین موارد در مراحل گردآوری (ترجمهٔ یک کد سیپلاسپلاس به دستورالعملهای قابل فهم ماشین) است. اما گامهای دیگری نیز وجود دارد، پیشپردازنده و لینک (پیوندها) این بخش به طور خلاصه توضیح میدهد که چه اتفاقی در هر یک از مراحل رُخ میدهد. یک کامپایلر یک برنامهٔ خاص است که پردازش اظهارات (دستورات) نوشته شده در یک زبان برنامهنویسی خاص را به یک زبان ماشین که قابل فهم برای پردازنده میباشد تبدیل کند. به طور معمول یک برنامهنویس با استفاده از یک ویرایشگر که به محیط توسعهٔ یکپارچهٔ نرمافزار (IDE) مشهور است توسط زبان برنامهنویسی مانند ++C دستورات (اظهارات) را مینویسد. فایل ایجاد شده با نام (filename.cpp در زبان برنامهنویسی سیپلاسپلاس) شامل محتوایی است که معمولاً به عنوان دستورات برنامهنویسی سطح بالا نامیده میشود. سپس برنامهنویس کامپایلرِ مناسب برای زبان برنامهنویسی مانند سی++ را اجرا میکند و نام فایلهایی که حاوی دستورات هستند را برای کامپایل مشخص میکند که این انتخاب و مشخص سازی توسط IDE به راحتی قابل مدیریت است. پس از آن، کار کامپایلر این است که فایلهای منبع .cpp را جمع آوری کرده و پیشپردازندهها را بررسی کند تا دستورات احتمالی را اجرا نماید که نتیجهٔ این مرحله در فایلی با پسوند .ii ر قالب filename.ii تولید میشود که در این فرایند نیز خط به خط کُدهای موجود در آنها را بررسی میکند تا خطاهای احتمالی نحو (سینتکس - Syntax) بررسی میشود و آنها را به طور ترتیبی به دستورالعملهای سطح ماشین تبدیل کند. توجه داشته باشید که هر نوع پردازندهٔ کامپیوتر دارای مجموعهای از دستورالعملهایِ ماشین خودش است. بنابراین کامپایلر تنها برای سی++ نیست، بلکه برای اهداف و مقاصد خاص هر پلتفرم است. پس کدهایی که توسط پیشپردازنده سیپلاسپلاس به زبان اسمبلی برای معماری مورد نظر در پلتفرم مقصدترجمه شدهاند نتایج آن در فایلی با پسوند .ss در قالب filename.ss قابل نمایش هستند که در حالت عادی قابل رویت نیست. توجه داشته باشید که باید در این مرحله باید مشخص شود برنامه قرار است توسط چه نوع پردازندهای تحتِ چه نوع معماری مونتاژ (اسمبل) شود. برای مثال پردازندهها با انواع معماریهای مختلف وجود دارند که برخی از آنها به صورت x86-x64، x64، ARMv7، aarch64 غیره ... میباشند. شکل یک (کامپایل یک فایل منبع ++C) مرحلهٔ سوم را در نظر داشته باشید که عمل کامپایل فایل سیپلاسپلاس در دو مرحله قبلی یک فایل اجرایی را تولید نمیکند. برنامهای که توصیف شده است، احتمالاً توابعی را در رابطهای برنامهنویسی (API) و یا توابع ریاضی یا توابع مرتبط با I/O را فراخوانی کند که ممکن است شامل فایلهای هدر مانند iostream یا fstream و حتی ماژولهای دیگری که در زبان تعبیه شدهاند را داشته باشد که فایل تولید شده توسط کامپایلر در این مرحله یک فایل شیء نامیده میشود که با پسوند .o به صورت filename.o تولید خواهد شد که علاوه بر دستورالعملهای تبدیل شده به کد ماشین، شامل توابع و دستورالعملهای خارجی نیز میباشد. هرچند در این مرحله دستورات تبدیل به دستورالعملهای قابل فهم توسط پردازنده شدهاند اما فعلاً قابل اجرا نیستند چرا که باید این توابع خارجی افزوده شده را به آن لینک کرد که در مرحلهٔ بعد یعنی مرحلهٔ چهارم اتفاق میافتد. در نهایت مرحلهٔ چهارم فایل با پسوند .o که شامل کدهای تولید شده توسط کامپایلر به زبان ماشین است که پردازندهها میتوانند این دستورات را درک کنند که همراه با کدهای تولید شدهٔ هر کتابخانهٔ دیگری که مورد نیاز است توسط لینکر (لینک شده) و در نهایت جهت تولید یک فایل اجرایی مورد استفاده قرار میگیرند که نوع آن فایل از نوع اجرایی یا در واقع Executable File خواهد بود. شرح کامل فرایند ساخت فایل اجرایی اکثر پروژهها دارای مجموعهای از فایلهای هدر سی++ هستند، که امکان ماژولار شدن در آن را فراهم میکند و مجموعهای از آن میتواند به عنوان بخشهای کوچکی از برنامه محسوب شوند. برای ساخت چنین پروژههایی هر فایل سیپلاسپلاس باید کامپایل شود و سپس فایلهای ساخته شده در قالب شیء (آبجکت) باید همراه توابع و کتابخانههای دیگر لینک (پیوند) شوند. البته هر گام از مراحل کامپایل شامل یک مرحله پیشپردازنده است که دستورالعمل # عمل تغییرات و اصلاحیهها را در فایل متن اعمال میکند. شکل زیر فرایند ساخت چند فایل به صورت همزمان را نشان میدهد: در ادامهٔ این مقاله، مطلبی مرتبط با تنظیمات بیشتر از کامپایلر آمده است که میتوانید آن را مورد مطالعه قرار دهید. -
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #2cdb89; color: #000000;" >کتابخانه کیوت (Qt)</span>
در این پست قصد داریم در رابطه با نحوهی نصب و راهاندازی محیط کیوت جهت توسعهی نرمافزار توضیح دهیم. بنابراین مراحل آن به ترتیب به صورت زیر خواهد بود. انتخاب پلتفرم توسعه (ویندوز، مک یا لینوکس) انتخاب و دانلود نسخهی مورد نظر برای محیط توسعه نصب و راه اندازی محیط توسعه پیکربندی و اجرای اولین برنامه ساخت و استقرار برنامه طبق توضیحات بالا، ابتدا وارد بخش مرکز دریافت در مرجع شده و نسخهی Qt مربوط به پلتفرم مورد نظر خود را دریافت کنید. برای این منظور از این بخش وارد شوید (دقت کنید که حتما وارد حساب کاربری خود شده باشید). نکته : نسخهی موجود در این مرجع بهروزترین نسخهی ممکن خواهد بود. نکته ۲ : در محیط ویندوز حتماً توجه داشته باشید که باید Visual Studio نصب باشد. اگر به خاطر حجم آن قادر به نصب نیستید سعی کنید نسخهی Build Tools را نصب نمایید. این بسته شامل کامپایلرها و SDK های ویندوز است که برای کار با سی++ به آنها نیاز خواهید داشت. در صورتی که یکی از این دو پیشنهاد را نصب نکنید ممکن نیست که بتوانید برنامهای را کامپایل کنید. نکته ۲ : در محیط لینوکس مطمئن باشید که GCC نصب است. همچنین دستورات زیر را قبل از نصب کیوت اعمال کنید تا پکیجهای مورد نیاز نصب شود. sudo apt-get install build-essential libgl1-mesa-dev نکته ۳ : در محیط macOS حتماً باید Xcode نصب باشد. جهت نصب کیوت فایل نصبی آن را در محیطی که هستید اجرا کنید تا برنامه نصبی اطلاعات مربوطه را بررسی نماید. در ادامه گزینهی Next را بزنید، در صورتی که مایل هستید اطلاعات ثبتنام (جهت ثبت اطلاعات در سرور Qt) را وارد کنید. در غیر این صورت گزینهی Skip را بزنید و ادامه دهید. در مرحلهی بعد گزینه Next را زده و مسیر نصبی خود را انتخاب کنید، سعی کنید همان مسیر پیشفرض را تایید کنید. مهمترین بخشی که بسیاری از کاربران در مورد آن سوال میکنند این مرحله است که چه گزینههایی را باید برای نصب انتخاب کنیم. در این بخش تمامی گزینهها را انتخاب کنید به جز گزینههایی که منسوخ شده اند و با واژهی (Deprecated) مشخص شده اند و قرار است در نسخههای بعدی حذف شوند. همچنین گزینههایی که مقابل آنها TP نوشته شده است مخفف Technology Preview است به معنی اینکه این ماژول یا پلاگین به صورت آزمایشی فعلاً در این پکیج قرار گرفته اما نهایی نشده است. در بخش Tools تمامی گزینهها را انتخاب کنید همهی آنها نیاز است. همچنین برای اینکه بتوانید از دیتابیس و پلاگینهایی مانند QMySQL استفاده کنید باید گزینهی Source را انتخاب کنید تا بعداً امکان ساخت این ماژول فراهم شود. توجه کنید که در این مثال گزینههای MSVC 2015 انتخاب نشده است. دلیل آن است که ما روی سیستم از نسخهی ۲۰۱۷ ویژوال استودیو استفاده میکنیم و ابزارهای ساخت ویرایش ۲۰۱۷ تعبیه شده اند. بنابراین با توجه به نسخهی VS آنها را انتخاب کنید. مواردی که شامل گزینههای UWP هستند به خاطر آن است که شما بتوانید تحت کیوت برنامههای Universal Windows Platform را استقرار و اجرا کنید. همچنین جهت امکان تولید برنامههای اندروید و ویندوز فون گزینههای Android ARMv7 و UWP ARMv7 نیاز هستند. دقت کنید که گزینهی x86 برای اندروید معمولاً برای نسخهی مجازی دسکتاپ مورد استفاده قرار میگیرد. در پلتفرمهای لینوکس و مکاواس گزینههای مرتبط با MSVC وجود ندارد. تنها با این تفاوت که در پلتفرم مک گزینهی Android و iOS نیز موجود هستند و شما میتوانید با انتخاب گزینهی iOS آن را به محیط توسعه خود اضافه کنید. در نهایت شرایط و مجوزهای کیوت را تایید کنید که در ادامه آمده است: توجه داشته باشید که بر اساس انتخابهایی که کردهاید فضای لازم برای نصب Qt به صورت زیر به اطلاع شما رسانده میشود که در این بخش چیزی حدود ۱۰ گیگابایت است. بر روی Install کلیک کنید و مراحل نصب را نهایی سازی نمایید. بعد از نصب سیستم توسعهی شما آمادهی استفاده است. یک پروژه جدید ساخته در صورتی که مراحل توضیح داده شده را به درستی انجام داده باشید انتخاب کامپایلر برای شما به درستی اعمال خواهد شد. در ادامه برای ساخت و اجرای برنامه نوع کامپایلر را انتخاب و کامپایل کنید. در نهایت برنامه بدون مشکلی اجرا خواهد شد. همچنین مرحلهی آخر، جهت بررسی نحوهی استقرار و اجرای برنامه این بخش را مطالعه کنید. -
با سلام، با توجه به سوالات مکرر برخی از کاربران و خصوصاً دانشجویان جدید، تصمیم گرفته شد تا توضیحاتی دربارهٔ نحوهٔ یادگیری برنامهنویسی با سیپلاسپلاس بیان شود. قبل از هر چیز لازم است بدانید، سیپلاسپلاس یک زبان برنامهنویسی کاملاً تخصصی مهندسی است. بنابراین یادگیری آن طبیعتاً نیاز به تلاش، تحمل و پشتکار کافی در مقابل چالشهای آن خواهد داشت. مقدمه در حال حاضر بیش از سه دهه است که از ساخت و معرفی زبان برنامهنویسی ++C میگذرد. در رابطه با آن که هدف از ایجاد این زبان چه چیزی بوده و مزایای آن نسبت به زبانهای دیگر چه چیزی است (چرا موتور مخفی جهان مدرن امروزی است) را میتوانید در این مقاله مطالعه کنید. اما بسیاری از افراد علاقهمند به زبانهای برنامهنویسی تمایل بسیاری دارند تا در برنامهنویسی با این زبان به درجه مطلوب و درواقع (حرفهای) برسند. قبل از هر چیز باید مواردی را در نظر داشته باشیم که یاد گیری زبانهای برنامهنویسی به خودی خود کافی نیست! مخصوصاً زبانهای C و ++C مستلزم پیشنیازهای تخصصی بسیاری هستند که در روند تولید، توسعه، تجزیه و تحلیل لایههای مختلف مهم است. آیا زبان سیپلاسپلاس در حال توسعه است؟ به جرأت میتوانم بگویم که سیپلاسپلاس به عنوان پیشتاز زبانهای برنامهنویسی با سرعت بسیار زیادی در حال گسترش و توسعهٔ خود است. بهتر است بدانید این زبان از شیوهٔ نسخهنگاری معمولی بهره نمیبرند، بلکه از «استاندارد» (ISO/IEC) که کمیتهٔ استانداردسازی آن را تأیید و نهایی میکند بهره میبرد. بنابراین، بر اساس استانداردی پیش میرود که پیشنویسهها و بهبودهای آن تماماً با حفظ (پشتیبانی از عقبگرد) قابل توجه است. همانطور که در تصویر مربوطه میبینید، سیپلاسپلاس در آخرین بهروز رسانی، به نقشهٔ توسعهٔ خود در سالهای بعد نیز اشاره کرده است که در قالب استانداردهای ۲۳، ۲۶ و ۲۹ از الآن یاد شدهاند. چیزی که در هیچ زبانی در وضعیت فعلی به صورت نقشهٔ راه از توسعه آنها نمیتوان دید! این خود یک نکتهٔ بسیار مثبت است که تیم (کمیته) استانداردسازی این زبان کاملاً این اطمینان را میدهد که این زبان نسبت به نیاز و آینده در حال به روز بوده، است و خواهد بود. لازم است بدانید، استانداردهای فعلی، ۱۷ و ۲۰ و بعد ۲۳ به عنوان یک نسل انقلابی و جهش یافته از سیپلاسپلاس یاد میشوند، اگر شما تجربهٔ نوینی از برنامهنویسی را میطلبید، بهتر است به استاندارد ۲۰ خوشآمدگویی کنید که در کنار کارآیی بسیار عالی، یک نحو و سبک بسیار ساده و روان در اختیار توسعهدهنده قرار میدهد. در ادامه ما به سوالاتی که معمولاً توسط تازهکاران پرسیده شده است پاسخ دادهایم: ابعاد علمی و اقتصادی کار با ++C در ایران متاسفانه اکثر ما ملتی هستیم، تَنبَل و حاضر برای لُقمهٔ آماده! بنابراین بازار کار در ایران به گونهای است که بیشتر شرکتها و افراد توسعه دهنده به سراغ زبانهای سادهتر و در دسترستر (بی دردسر) میروند. غافل از آن که یک برنامهٔ تولید شده توسط سی++ بسیار سریع، جذاب، قدرتمند و انعطافپذیرتر است. همهٔ بحث در اینجا تمام نمیشود، چرا که شاید در سالهای اخیر وضعیت تقریباً فرق کرده و به کمک اطلاع رسانیهای اساتید و دوستان حرفهای، ما در این زمینه این اطلاعرسانی به خوبی صورت گرفته و توسعه دهندهها از قابلیتها پنهان این زبان آگاه شدهاند و میدانند که سیپلاسپلاس به عنوان یک زبان بسیار کاربردی در زمینههای مختلف جایگاه ویژهای دارد. شرکتها و گروههای برنامهنویسی بسیاری به دنبال برنامهنویسهای سی++ هستند که این امر نشان دهندهٔ این است که نسبت به سالهای گذشته پیشرفت و آگاهی جامعهٔ برنامهنویسی در این حوزه منطقیتر و بهتر شده است. من بارها در مورد بحث محدودیتهای سختافزاری، مشکلات و محدودیتهای پیش و روی قانون مور، مسائل مربوط به انرژی سبز و غیره صحبت کردهام. و اکنون زمان آن رسیده است که بیشتر در این باره فکر کنید که واقعاً چه ابزارهایی آیندهٔ بهتر و موثرتری در پیشرفت صنایع خواهند داشت. بنابراین، بهتر است قبل از هرچیز در نظر داشته باشید که هدف از این تاپیک، این نیست که اثبات کنیم یک زبان نسبت به زبان دیگر برتری دارد. هدف اصلی من این است به واقعیتهایی اشاره کنم که غیر منطقی نیستند. چرا که واقعاً کارفرمایانی وجود دارند که نیازمند به برنامهنویسانی هستند که تخصص خوبی در زبانهای برنامهنویسی دیگری مانند ++C دارند. همه چیز در زبانهای سطحبالاتر خلاصه نشده است! توجه داشته باشید که هدف از این توضیحات چنین نیست که بعد از خواندن این مطالب زبان برنامهنویسی مورد علاقهٔ خود را کنار گذاشته و به سمت سی++ بروید، خیر! یا مقصود آن نیست که با دیدن و شنیدن پیچ و خمهای آن از یادگیری آن منصرف شوید. من بارها گفتهام، تمامی زبانها به عنوان ابزارهای کاری شما در یک جعبهٔ ابزار هستند و هر زبانی حوزهٔ کاربردی خودش را دارد. بنابراین قبل از اینکه شما تصمیم بگیرید که چه زبانی را یاد خواهید گرفت باید حوزهٔ کاری وعلاقهٔ خودتان را مشخص کنید سپس وارد تحقیق و بحث و نظر خواهی راجع به آن زبان نمایید. مقایسهٔ زبان طبق این قانون کاملاً کار اشتباه و بچهگانه است و به هیچ عنوان در مورد یک زبان برنامهنویسی گاردِ تعصبی نگیرید. متاسفانه به خاطر تفکرات اشتباه و معرفیهای غیر منطقی و غیرعلمی برنامهنویسان کشور ما که ممکن است حتی خودِ شما هم چنین تصور کنید، در رابطه با سایر زبانها مانند سی++ بسیاری از کارفرمایان نیازمند چنین برنامهنویسانی هستند که در کشور ما واقعاً نیاز است. توجه داشته باشید که انتخاب درست این نیست که چون همه سراغ زبانهای پر مخاطبتری میروند و چون تمامی آگهیها استخدامی مرتبط با آنها است پس فقط باید آنها را یاد گرفت! خیر چنین تفکری اشتباه است و ضربهٔ بسیار بزرگی در صنعت و دانش آیندهٔ جامعهٔ تخصصی هر کشوری که به این شکل پیش میرود خواهد زد، چرا که ما باید طبق مسیر و سرعتی که دنیا در حال جهش است، خود را هماهنگ و بهروز کنیم. نکاتی در این میان وجود دارد که باید به آنها اشاره کرد: متاسفانه در کشور ما بسیاری از برنامهنویسان چه مبتدی چه حرفهای اینطور تصور میکنند که تولید محصول نرمافزاری یعنی برنامهنویسی یک نرمافزار که قرار است به بانک اطلاعاتی متصل شده و کارهایی مانند ثبت و ویرایش اطلاعات و در نهایت گزارش گیری و دیگر عملیات ممکن را انجام دهد! این تفکر به شدت اشتباه است! الآن دیگر سیستم نرمافزاری، معماریها و سبک و سیاقهای ساختوساز فرق کرده است. مبتنی بودن بر خدمات متمرکز، غیرمتمرکز و دیگر فناوریها بسیار مهم است. توجه کنید که بزرگترین و معروفترین فناوریها مطرح جهانی معمولاً به واسطهٔ این زبان طراحی میشوند، مانند، سیستمعاملها، نرمافزارها، زیرساختها و حتی بلاکچین و بیتکوین که خالی از لطف نیستند. بسیاری از بانکها و شرکتهای صنعتی و اقتصادی مهم کشور نیازمند برنامهنویسان سی++ هستند تا بتوانند در بحث بانکی برای توسعه دستگاههای پرداخت مانند Pos و ATM از این زبان و برنامهنویسان بهره ببرند. در صنایع بزرگ خودرو سازی و دیگر موارد نرمافزارهای مورد نیاز است تا با سرعت بسیار و بدون محدودی پلتفرمی پاسخگوی یک چرخهٔ تولید باشند تا بتواند زیرساختها و رابطهای یک شرکت بزرگ را مدیریت و آن را بهینه کند. در بسیاری از حوزههای صنعتی کشور شرکتهای غولپیکر در زمینهٔ تولیدات انبوه و سنگین که توسط ماشینآلات صورت میگیرد به دنبال برنامهنویسان سی و سی++ هستند که ممکن است به صورت معرف یا آشنا با آنها مواجه و استخدام شوید. شرکتهای سختافزاری و استارتآپهایی که در حوزهٔ الکترونیک و سختافزار فعالیت میکنند به دنبال برنامهنویسیان سی++ هستند تا بتوانند در حوزهٔ کاری خود اهداف خود را توسعه و شما را به عنوان مهرهای مفید پیش ببرند. شرکتهای توسعهدهندهٔ موبایل و خطوط تولیدی تلفنهای همراه داخلی گسترش یافته و به شدت نیازمند برنامهنویسان سی++ هستند که برخی از آنها مبادلات بینالمللی نیز دارند. در بخش حوزهٔ شهر سازی، مدیرت شهر و همچنین راهداری شرکتهایی هستند که برای تولید سیستمهای مدیریتی مانند مدیریت راهها و ترددهای خودرو و یا مدیریت ترافیک و موارد این چنینی به دنبال برنامهنویسان سی++ هستند. بسیاری از شرکتها و حتی تیمهای توسعه بر روی پلتفرمهای iOS و Android به صورت تخصصی سفارشی سازی و حتی ساخت و توسعهٔ اپلیکیشنهای ایرانی تمرکز دارند که جدیداً به لطف آگاهی از فریموُرکهایی مانند Qt به سمت این حوزه آمده و نیازمند سی++ کاران هستند. شرکتهای بازیسازی کشور ما که این سالها با پیشرفتهای خوبی مواجه شدهاند به دنبال برنامهنویسان سی++ هستند که بتوانند در این صنعت برای فرهنگسازی و توسعه صنعت بازی سازی جلو بروند. بسیاری از شرکتهای پنهان وجود دارد که به صورت بسیار مخفیانه در صنایع سهبعدی و پیشرفته در حال فعالیت هستند که محصولات خود را نه در ایران بلکه در خارج از آن آمریکا و دیگر کشورهای اروپایی به فروش میرسانند که به سفارش آنها بوده است. با دید سطحی به این مسائل نباید نگاه کنید، اگر آگهیهای استخدامی نمیبینید به خاطر این است که این زبان کار کُن می خواهد نه تَنبل! بنابراین شما باید به سراغ آن بروید چرا که بسیاری از شرکتهای بینالمللی فعالیتهای بزرگی انجام میدهند که هیچوقت از آنها خبر ندارید و به صورت کاملاً سفارشی و حساسیت کامل به دنبال برنامهنویسان این زبان هستند (چون میدانند یک سی++ کار هدفمند و با دید بازتری به توسعه نگاه میکند). چنین شرکتها معمولاً استخدام را به صورت رابطهای انجام میدهند و تعداشان هم کم نیست. ما میدانیم که شاید شما با دیدگاه اینکه حتماً باید نرمافزارهای کاربردی تولید کنید به قضیه نگاه میکنید، خوشبختانه فریمورک کیوت به قدری قدرتمند و پُخته شده است که میتوان هر محصول کاربردی در هر زمینهای را تولید کرد که از کارایی بسیار بهتری نسبت به دات نت بهرهمند است. در حوزهٔ امنیت، شبکه و موارد این چنینی شرکتهای بزرگ و Ispها نیازمند این زبان هستند. البته دلایل بسیاری وجود دارد که موجب میشود شرکتها از روی ناچاری به سراغ برنامهنویسان دیگر بروند، که من شخصاً آن را تجربه کرده ام ! در بسیاری از پروژهها که به عنوان مشاور فنی در آنها شرکت کرده بودیم متوجه آن شدیم شرکتها به خاطر عدم وجود برنامهنویس سی++ برای ادامهٔ چرخهٔ تولید خود مجبوراً سراغ برنامهنویسهای دیگر زبانها میروند. این امر به خاطر این است که واقعاً درصد تعداد برنامهنویسان این زبان نسبت به زبانهای دیگر به خاطر (راحت طلبی) و شاید عدم آگاهی از این زبان دور هستند. یکی از نکتههایی که اخیراً جالب بوده است، آن است که شما به واسطهٔ سیپلاسپلاس میتوانید حتی وبسایتهای مورد نیاز خود را بسازید! یک سیستم چند-منظوره طراحی کنید که در حوزههای قابل استفاده باشد. برخی از هماهنگیهایی که این زبان خود را به بهروز رسانیهای بسیار سریع در فناوری وفق داده است، پشتیبانی از ساختارهای چند-سکویی و کاملاً بومی با کارآیی بالا است که در حوزههای موبایل، دسکتاپ و وب میتوانید آن را مورد استفاده قرار دهید. از فناوریهای مربوط به فریمورکهای طراحی گرفته، تا امکان ساختوساز در قالب وباسمبلی، بلاکچین و دیگر موارد. یک نکتهٔ بسیار مهم که طی این سالها تجربه کردهام، این است که خیلی از شرکتها و خدمات دهندهها با این که در جریان مزایای این زبان هستند، مجبوراً به خاطر عدم وجود متخصص کافی از ابزارهای دیگر برای توسعهٔ کار خود استفاده میکنند. هرچند مشکلات این زبان تا به الآن شفاف شده است، اما بهروز رسانیها و توسعههای پی در پی آن موجب بهبودهای بسیار چشمگیری در آن نیز شدهاست. برخی از سوالاتی که علاقهمندان به این حوزه میپرسند در ادامه آمده است: من یک دانشجو هستم و رشتهٔ تحصیلی من کامپیوتر است، به برنامهنویسی با ++C علاقه دارم از کجا باید شروع کنم؟ اگر شما به قصدِ حرفهای شدن دنبال یادگیری این زبان هستید، همانطور که اشارهای شد مباحث پیش نیاز برای یادگیری این زبان مهم هستند و برای درک هرچه بیشتر این زبان بهتر است دانش خوبی در زمینهٔ تجزیه و تحلیل رفتار کامپایلر داشته باشید. علاوه بر این برای آشنایی با کامپایلر رفتار سیستمعامل و واکنشهای کامپایلری در سیستمعاملهای متفاوت بسیار مهم است. به عنوان مثال کامپایلر GCC بر روی ایستگاههای یونیکس تعبیه شده و برای خود قوانین و استانداردهایی را دارد. در کنار آن کامپایلر MSVC نوعی کامپایلر اختصاصی تحت ویندوز است که متناسب با ساختار و معماری ویندوز رفتار میکند. در نگاه اول آشنایی با آنها شاید الزامی به نظر نرسد، چرا که شما صرفاً به سمت یادگیری زبان، نحو (سینتکس)، ویژگیها، کتابخانهٔ پیشفرض و هستهٔ آن میپردازید. اما در بُعد ساخت و ساز یک محصول عالی اطلاعات شما در زمینههای مختلف لازم است کافی باشد. من یک دانشجو هستم اما متاسفانه رشتهٔ تحصیلی من کامپیوتر نیست، به برنامهنویسی با ++C علاقه دارم از کجا باید شروع کنم؟ این کار کمی دشوار است، در مرحلهٔ اول پیشنهاد ما این است که سراغ زبانهای برنامهنویسی دیگری بروید که نیازی نداشته باشد شما درگیر درک کامپایلر یا رفتارهای سیستمعاملی شوید. اما به هر حال اگر شما به هر نحوی میخواهید این زبان را یاد بگیرید چارهٔ کار تلاش مستمر و حوصله است. متاسفانه سیپلاسپلاس ذاتی مرموز دارد و آن این است که اگر بتوانید به آن مسلط شوید یک زبان با وفا و قدرتمندی خواهد بود که در هر زمینهای به نیازهای شما پاسخگو خواهد شد. اما اگر به هر دلیلی نتوانید با این زبان دوست شوید به طور بسیار مرموزی اعصابتان را به هم خواهد ریخت ? که البته طبیعی است چون سی++ تحت کامپایلرهای خود دستِ برنامهنویس را آزاد گذاشته و شما هستید که انتخاب میکنید کُد شما به چه شیوهای با توجه به هدف چگونه عمل کند. چقدر زمان لازم است تا من این زبان برنامهنویسی را یاد بگیرم؟ با توجه به ساختار زبان و رفتارهای کامپایلر میتوان گفت به قدری دامنهٔ سی++ گسترده است که تنها راه حل ممکن برای رسیدن به یک وضعیت مطلوب از دانش مرتبط با آن باید زمان مشخصی در نظر گرفته شود. ممکن است شما بتوانید در بازهٔ ۱ الی ۳ ماه مباحث مقدماتی این زبان را درک کنید. اما توجه داشته باشید پیشنیازات آن نیز نیازمند تحقیق، تجربه عملی و نتیجهگیری تئوری و علمی هستند. با توجه به اینکه شما (سریع، هوشمند با گیرایی بالا باشید) میتوانید در کمتر از ۶ ماه به یک پایداری تقریباً قابل قبول در حد مقدماتی این زبان برسید. استاندارد زبان را درک کنید و نحوهٔ برقراری ارتباط با کتابخانههای پیشفرض STL و غیره را تجربه کنید. برای کسب دانش و افزایش آن به میزان متوسط و به بالا نیازمند تلاش بسیار بیشتری خواهید بود که باید در قالب پروژههای عملی و واقعی صورت گیرد. متاسفانه سی++ به دلیل گسترده بودن چنان پیچیدگیهایی را دارد که تنها میتوان در موقع برنامهنویسی به صورت عملی (بر روی پروژههای واقعی) آن را تجربه کرد. آیا ارزش دارد من این زبان را یاد بگیرم؟ فرصت من کم است و میخواهم سریعاً به درآمدزایی برسم در همین ابتدا به شما میگویم که اگر صرفاً به درآمدزایی سریع فکر میکنید، سیپلاسپلاس گزینهٔ مناسبی برای این رویا نیست! اگر شما به عنوان یک برنامهنویس متوسط و به بالا به این زبان تسلط دارید، و حداقل میتوانید با یکی از کتابخانههای خوب آن ارتباط برقرار کنید، وقت آن است که با کتابخانههای قدرتمند این زبان وارد عمل شوید. کتابخانههایی مانند Boost، Poco، Qt و غیره از سری کتابخانههایی میباشد که امکانات بسیاری را در اختیار شما علاقهمندان این زبان قرار میدهند تا بتوانید در کمترین زمان ممکن به نیازهای خود دسترسی داشته و آن را پیاده سازی کنید. همهٔ آنها در ساخت و توسعهٔ محصول به شما کمک میکنند. فراموش نکنید که بارها گفتهام به زبانها، کتابخانهها و فناوریها به عنوان ابزار در داخل جعبهابزار خود بنگرید. توجه داشته باشید که لازمهٔ طراحی و توسعه یک محصول مفید (قابل قبول) در قالب MVP (کمینه محصول پذیرفتنی) مستلزم داشتن دانش طراحی محصول نیز میباشد. اما همه چیز اینگونه خلاصه نشده است و شما برای اینکه بتوانید یک محصول واقعاً قابل قبول را پیاده سازی کنید مسلماً باید آن را مجهز به قابلیتهای دیگری مانند منابع ذخیره داده و یا سرویسها و ماژولهایی کنید که بتواند به عنوان یک محصول کاربردی روی آن حساب کرد. آیا صرفاً با دانستن زبانهای برنامهنویسی و تسلط بر آن میتواند یک محصول استاندارد و سطح جهانی را به طور کامل تولید کرد؟ نظر من قطعاً خیر است! اگر شما واقعاً با دیدگاه یک سازنده، یک تولید کننده و مهندس تمام عیار در ذهن خود رویا پروری میکنید، در این صورت باید بدانید همه چیز در زبان خلاصه نمیشود! از نظر من حداقل مواردی که (به طور خیلی خیلی خلاصه و محدود) نیاز است تا یک متخصص بتواند پاسخگوی تصمیمگیری نقشهٔ توسعهٔ یک محصول برای مشتری در ابعاد مختلف و سطوح متفاوت از حوزههای موجود در قالب اصولی باشد به صورت زیر است که فرد یا یک تیم باید به آنها اشراف کافی داشته باشد: ۱- آشنا مبانی کامپیوتر که امر طبیعی (شامل درک و فهم مسائل و نحوهٔ حلشون متناسب با پلتفرم اجرایی محصول) ۲- آشنا به ساختار نوع محصول استاندارد در یک حوزه مثل: وب، آیاواس، اندروید یا دسکتاپهای مختلف مثل لینوکس، مک و ویندوز، اینترنت اشیاء و دیگر موارد. ۳- آشنا به فلسفهٔ بکاند و فرانتاند یا ترکیبی از این دو به همراه ابزارهای مناسب. ۴- آشنا به اصول طراحی UI/UX به عنوان یک نیاز و یک فاکتور مهم در ساخت محصولی که وابسته به عملکرد کاربر دارد و در حوزهٔ فرانتاند مهم و کاربردی هست. ۵- آشنا به اصول SOLID و امثالش مهم هستند. ۶- آشنا اصول برنامهریزی ساخت بانک اطلاعاتی، اینکه از چه بانک اطلاعاتیای استفاده کنی و چرا؟ ۷- آشنا به ارتباطات دادهای، جداول و ارتباط بین فیلدها، جداول و روشهای درست تبادل اطلاعات مابینی دادهها. ۸- آشنا و تسلط کافی به یک محیط توسعه و ادغام ابزارها و محیط طراحی برای هدف. ۹- آشنا به معماری ساختار و رابطهای برنامهنویسی (Api) ۱۰- آشنا به استانداردهای Http، درک و مدیریت درخواست، پاسخها و ... ۱۱- آشنا به الگوهای طراحی برنامهنویسی (DP) ۱۲- آشنا به روشهای نگهداری و آزمایش نرمافزار و کدها به خصوص درک مبحث Fault tolerance. ۱۳- آشنا به روشهای اطمینانسازی و ایمنسازی پردازشهای داخلی نرمافزار برای جلوگیری یا دشوار سازی نفوز و خرابکاری. ۱۴- آشنا به روشها و معماریهای احراز هویت و نحوهٔ ادغامش با نرمافزار مثل:JWT, OAuth, AWS و غیره... ۱۵- آشنا به نوع پارادایمهای زبان برنامهنویسی، در قالبهای (دستوری) Imperative و (اعلانی) Declarative مثل OOP، functional و دیگر موارد. ۱۶- آشنا به سبک معماری نرمافزاری (Microservice یا مثلاً Monolith) مزایا و معایب آنها. ۱۷- آشنا به سبک معماری طراحی مانند MVC در طراحی بدنهٔ محصول. ۱۸- آشنا به سبک و الگوهای طراحی ساختاری در بکاند مانند Builder، Abstract، Factory و غیره. ۱۹- آشنا به ساختار یک زبان (در صورتی که میخواهید جوابگوی مسائلِ پیش آمده باشید) کالبدشکافی زیرپوستی و عمیق یک زبان مهم است. ۲۰- آشنا و درک کامپایلرها و مفسرها، تفاوتها و شیوههای عملکردیشون نسبت به کدهای بهینه شده و عادی. ۲۱- آشنا و درک مدلهای مختلفی از سیستمهای توزیع شده مثل IaaS، PaaS، SaaS یا FaaS. ۲۲- آشنا به ابزارهای ساخت و فرآیند کاری اونها مثل CMake، NMake، QMake و غیره. ۲۳- آشنا به روشهای مدیریت وابستگیهای نرمافزار و ابزارهای لازم برای بستهبندی بهتر خروجی. ۲۴- آشنا به روشهای کدنویسی قابل آزمایش (Unit Test) و استفاده از ابزارهایی مثل CTest, GTest, Catch2 و غیره. ۲۵- آشنا به توسعهٔ آزمون محور (Test Driven- Development) ۲۶- آشنا به گامها و شرایط نسخهنگاری و مراحل توسعهٔ نرمافزار (SDP) ۲۷- آشنا به روشهای امنیت در کد و توسعه به شیوههای بررسی از طریق Fuzz-Test، Sanitizer، آنالیزرهای پویا و ایستا و غیره... ۲۸-آشنا به قوائد طراحی بر پایهٔ خدمات مبتدی بر معماری ابری برای خدمات پیامی، وبسرویسها، پردازش و غیره. ۲۹- در سطوح وب آشنا به مکانیزم شاخص بندی، فاکتورهای SEO و شیوههای درست بهبود صفحات وب. ۳۰- آشنا به روشهای به کار گیری و پیادهسازی ثبت کنندهٔ وقایع در دل محصول و روشهای بازخورد برای توسعهٔ بهتر به همراه مانیتورینگ، نظارت و تریسینگ. ۳۱- در شرایط لزوم آشنا به نحوهٔ به کار گیری و دلیل استفاده از فناوریهایی مثل Redis، Memcached و غیره. ۳۲- آشنا و درک صحیح از مفاهیم همزمانی (Concurrency) و روشهای به کار گیری آن نسبت به زبان برنامهنویسی و شرایط مناسب استفاده. ۳۳- آشنا به سبک و قوائد و ساختار زبانهای برنامهنویسی و فرآیند ساخت و ترجمه. ۳۴- و تا صدها گزینهٔ دیگر که میتوان در این بخش لیست کرد که اگر انتخاب شما زبانهای نزدیک به سیستم باشد این داستان در ادامهٔ این توضیحات سر به فلک خواهد کشید. با توجه به این موارد اگر بخواهید محصولی را بسازید که طبق استاندارد آن را توسعه و تولید کنید که در بستر سیپلاسپلاس شکل میگیرد، باید ابزارها و موارد پیشنهادی زیر را در اختیار داشته باشید و کار با آنها را تا حد نیاز بدانید: یک محیط توسعه یکپارچهٔ نرمافزار مانند Qt Creator، Xcode یا Visual Studio (پیشنهاد ما Qt Creator است) این محیط به عنوان IDE نیز یاد میشود. پلتفرم توسعه (سیستمعاملی) که قرار است محیط توسعهٔ یکپارچه خود را بر روی آن نصب و شروع به برنامهنویسی کنید را مشخص نمایید. اگر شما کاربر ویندوز هستید باید محیط توسعهٔ یکپارچهٔ شما مجهز به کامپایلر MSVC و یا نسخهٔ پورت شدهٔ GCC یعنی MinGW باشد. اگر شما کاربر مکاواِس هستید به صورت پیشفرض با نصب محیط توسعه کامپایلر Clang بر روی آن تعبیه خواهد شد. البته میتوانید به صورت سفارشی از کامپایلر GCC نیز استفاده کنید. در صورتی که کاربر لینوکس هستید کامپایلر GCC به صورت پیشفرض بر روی محیط توسعهی شما تعبیه خواهد شد. آشنا به دستورات ترمینال و یا کنسول در سیستمعاملهای لینوکس، مک و ویندوز در ساخت و سازهای دستوری مفید هستند و نیاز است آنها را بدانید. آشنا به Git و دستورات مربوط به آن در نگهداری و به اشتراکگذاری مخازن پروژه میتواند برای شما سودمند باشد. بر اساس پیشنها جهت محیط توسعه کتابخانهٔ Qt نیز پیشنهاد میشود (دلیل آن این است که این کتابخانه به شما کمک میکند تا بتوانید رابط کاربری نرمافزار (محصول) خود را پیاده سازی کنید). اگر هدف شما طراحی یک محصول استانداردی است که از شکل و ظاهر آنچنانی برخوردارد نیست بهتر است از ماژولهای پیشفرض Qt مانند Qt Widget برای طراحی آن استفاده کنید. این کار بسیار ساده است و نیازی برای داشتن دانش در رابطه با حوزههای JavaScript و QML ندارد. البته میتوانید با ترکیب CSS طراحی رابط کاربری برنامهٔ خود را بهبود ببخشید. بعد از این موارد نیاز است که شما هدف توسعهٔ خود را مشخص کنید، اینکه میخواهید توسعه دهندهٔ چه پلتفرمی باشید؟ تولید کننده برنامههای دسکتاپ بر روی ویندوز؟ یا لینوکس و مک؟ یا همهٔ آنها؟ خوشبختانه با توجه به قابلیتهای ذاتی سی++ و کیوت شما میتوانید برنامهٔ خود را تنها با داشتن محیط توسعهٔ خود بر روی پلتفرم مورد نظر خود کامپایل و خروجی بگیرید (البته به شرط اینکه از سرویسهای اختصاصی سیستمعاملی) استفاده نکرده باشید. البته دقت کنید اگر شما توسعهدهندهٔ اختصاصی برای فقط یک سیستمعامل خواهید بود، در این صورت نیازی به یادگیری مفاهیم یا رابطهای اختصاصی برنامهنویسی یک پلتفرم دیگر نخواهید بود. اگر مشتاق آن هستید که برای پلتفرمهای موبایل مانند آیاواس یا اندروید برنامه تولید کنید، موضوع کمی گستردهتر خواهد شد و حتماً باید ملزوماتی که در ابتدای مقاله به آن اشاره شده است را در نظر داشته باشید. برای مثال تولید یک نرمافزار iOS مستلزم آن است که شما علاوه بر داشتن دانش سی++ در رابطه با معماری و ساختار و همچنین قوانین، قوائد و ساختار نرمافزارهای مرتبط با اپل راداشته باشید. در Android نیز این چنین است. اگر شما تازه کار هستید پیشنهاد میکنیم هدف خود را فعلاً محدود بر یک پلتفرم خاص کنید، حتماً نیاز نیست اطلاعات خود را کامل و سپس اقدام کنید. برای مثال توسعه محصول بر روی ویندوز برای آغاز کار بسیار مناسب است و شما صرفاً بر روی این پلتفرم متمرکز خواهید بود. در نهایت شما محصول خود را با آزمایش وخطاهای بسیاری میتوانید تولید و با توجه به مستنداتی که در همین مرجع ارائه شده اس مستقر و برای کاربر نهایی ارائه کنید. برای اینکه بدانید مزایای این زبان در چیست و چه کتابخانههایی میتوانند مفید باشد و برخی از سوالات احتمالی که ممکن است به ذهن شما برسد این بخش را مطالعه کنید. برای نحوهٔ شروع کار با Qt این بخش را مطالعه کنید. جهت نحوهٔ نصب و راه اندازی محیط توسعه این بخش را مطالعه کنید. منابع فارسی یا زبان اصلی؟ پاسخ این سوأل بدون شک راحت است! زبان انگلیسی، زبان علم است، بنابراین هر آنچه که شما در زبانهای بومی و غیر انگلیسی مطالبه میکنید، ممکن است با محدودیتهای شدیدی مواجه شوید. بنابراین برای یادگیری محتوای علمی به شدت توصیه میشود به کمک مراجع انگلیسی آن را بیاموزید! من زبانم ضعیف هست، آیا باید به زبان انگلیسی تسلط کافی داشه باشم تا بتوانم زبانهای برنامهنویسی را یاد بگیرم؟ این یکی از سوألهای بسیار پر تکرار است که بارها با آن مواجه میشویم! در پاسخ باید صادقانه بگویم، شما به حداقلهای زبان انگلیسی واقعاً نیاز دارید! در حد این که متنهای عادی را بخوانید، آنها را متوجه باشید و بر اساس نگارش معنای صحیح جمله و واژهها را درک کنید. رفته رفته به آن عادت خواهید کرد و در آن نیز حرفهای خواهید شد. اما فراموش نکنید که زبانآموزی در کنار برنامهنویسی از لزومات است. در مورد واژههای تخصصی هم نگران نباشید، معمولاً واژههایی که معنای آنها را مابین جملات و کتابها نمیدانید، در مراجع و یا پانویسهای آنها تعریف میکنند. بسیاری از واژهها در قالب یک روش، مفهوم یا اصطلاح عنوان میشوند و شما باید به دنبال تعریف کامل آن باشید. به عنوان مثل، اصطلاح RAII در سیپلاسپلاس که به برخی از آنها در این بخش اشاره کردهام. من سن پایینی ندارم، آیا برای شروع کردن برای یادگیری سیپلاسپلاس دیر است؟ شاید من تجربهٔ سنیِ کافی، نسبت به کسانی که این سوأل را میپرسند نداشته باشم، اما نسبت به تجربهای که در مهندسی کامپیوتر و به خصوص ساختوساز و توسعهٔ محصولات نرمافزاری دارم، میتوانم به جرأت بگویم که این یک دغدغهٔ ذهنیای به حساب میآید که شاید در قالب و جنسِ ترسِ بیهوده از دست دادن زمان را به خود بگیرید. اما واقعیت آن است، تا زمانی که شما شروع نکنید، بله نمیتوانید! اما نکتهای که مد نظرم است بدانید، این است که در انتخاب زبانها، به خصوصی یادگیری سیپلاسپلاس، بهتر است بخشی از هدف و استعدادی که به آن دارید را هدف قرار دهید، (هدف مشخص و شفافی داشته باشید) چون خاصیت این زبان در چند-منظوره بودن آن است، و ممکن است شما را وسوسهٔ خود در همهٔ جوانب کند! که این باعث میشود شما هرگز به یک نقطهٔ شروع نرسید. به عنوان مثال، برای شروع بهتر است یک حوزه را انتخاب کنید و پیشبرورید، مانند: برنامهنویسی و طراحی اپلیکیشن در سیستمعامل ویندوز. یا برنامهنویسی در حوزهٔ موبایل، وب، بازیسازی، امبدها (سیستمهای درونسازی شده) و غیره... این بستگی به سلیقهٔ شما و نوع نیازی که در بازار میبینید خواهد داشت. در زیر منابعی را معرفی میکنم که به رایگان یا با کمترین هزینه میتوانید به آنها دسترسی داشته باشید: منابع استاندارد و رسمی زبان سیپلاسپلاس: https://en.cppreference.com https://isocpp.org برای یادگیری در سطوح مقدماتی وبسایتهای زیر پیشنهادات مناسبی هستند: https://www.geeksforgeeks.org/references-in-c http://www.cplusplus.com/reference https://www.tutorialspoint.com/cplusplus/cpp_references.htm https://www.learncpp.com در صورتی که میخواهید در حالت بسیار ساده، تصویری و در قالب برگههای تقلب به ویژگیهای زبان و کتابخانههای آن بپردازید، وبسایت زیر یک نمونه بسیار مناسب است: https://hackingcpp.com توجه کنید که خیلی از مباحث در وبسایتها ذکر نمیشود، نیاز است بعضی از کتابها را در نظر بگیرید و آنها را عمیقاً مطالعه کنید، بنابراین برای مطالعه به ترتیب سطح مقدماتی و پیشرفته را در زیر عنوان میکنم: Beginning C++ Programming Beginning C++20 A Tour of C++ The C++ Programming Language C++ Primer Programming: Principles and Practice Using C++ کتابهای معرفی شده به استانداردهای ۱۱، ۱۴، ۱۷ و ۲۰ اشاره میکنند. کتابهای پیشنهادی برای سطح پیشرفته: Effective C++ Professional C++ C++ Templates: The Complete Guide – Second Edition Modern C++ Programming Cookbook Hands-On System Programming with C++۱۷ C++ High Performance Optimized C++ در صورتی که نیاز به کسب دانش بیشتر در حوزهٔ سطح پایین، سختافزار، معماری و ساختارهای نرمافزاری دارید کتابهای زیر بسیار مفید هستند: Computer Organization & Design RISC-V / ARM / MIPS / x86 Software Architecture with C++ در صورتی که تجربیات و نوشتههای خودم رو در این باره نیاز دارید به صورت زیر دستهبندی کردم که به ترتیب پیشنهاد میکنم مطالعشون کنید: اگر به دنبال مشاورهها، منابع یا مقالات و توصیههای فارسی یا انگلیسی من هستید، پیشنهاد میکنم در همین وبسایت، یوتیوب، گیتهاب و یا کانال تلگرامی من ملحق بشید. من هر جا که باشم، با شناسهٔ KambizAsadzadeh اگر در حد توانم باشد شما را راهنمایی خواهم کرد.
-
روش دریافت لینک کوتاهِ پُستها جهت بازنشر در شبکههای اجتماعی
کامبیز اسدزاده یک صفحه را ارسال کرد در عمومی
معمولاً برای بازنشر مطالب، سوال و پرسشهای خود در شبکههای اجتماعی یا گروهها و کانالهای پیامرسان نیاز است تا لینک آن را قرار دهیم.اما به صورت پیشفرض لینک مطالب کوتاه نیستند و برای حل این مشکل بهتر است از سیستم کوتاه کنندهی لینک استفاده شود که مثالی برای دریافت آن آمده است: فرض کنید سوالی پرسیدهاید، برای دریافت لینک کوتاه و مفید آن بر روی دکمهی بازنشر در بالای پُست کلیک کنید: برای دریافت لینک کوتاه و مناسب بر روی آن کلیک کرده و آدرس کوتاه شده را جهت بازنشر کپی کنید: * نکته، ممکن است شما نیاز داشته باشید تا آدرس پاسخ به سوالی را بازنشر کنید، در این صورت به پایینترین قسمت پاسخ خود رفته و بر روی گزینهها کلیک کنید و سپس گزینهی بازنشر را انتخاب و لینک مورد نظر خود را دریافت کنید. -
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #2cdb89; color: #000000;" >کتابخانه کیوت (Qt)</span>
در این پُست قصد دارم در رابطه با نحوهٔ نصب و اجرای برنامههای تحت کیوت تحت موارد زیر را توضیح دهم. راهنمای فرایند نصب و استقرار برنامه بر روی پلتفرم Windows راهنمای فرایند نصب و استقرار برنامه بر روی پلتفرم macOS راهنمای فرایند نصب و استقرار برنامه بر روی پلتفرم Linux راهنمای فرایند نصب و استقرار برنامه بر روی پلتفرم Android راهنمای فرایند نصب و استقرار برنامه بر روی پلتفرم iOS قبل از هر چیز لازم است بدانید که برای نصب و راه اندازیِ برنامههای نوشته شده تحتِ سیپلاسپلاس و کتابخانههایِ آن باید پیشنیازات آنها درقالب فایلهایی از کتابخانه در کنار برنامه قرار بگیرد. راهنمای فرایند نصب و استقرار برنامه بر روی پلتفرم Windows در این محیط نسبت به نوع و نسخهٔ Qt و کامپایلری که مورد استفاده قرار گرفته است باید توجه داشته باشیم که هنگام کامپایلر و خروجی گرفتن متناسب با سیستم مقصد آن را تهیه کنیم، برای مثال نوع معماری یعنی x64 یا x86 بودن یک سیستم بسیار مهم است. مواردی که باید به آنها هنگام کامپایل توجه کنیم: مشخص سازی نوع کامپایل برنامه حالت یا همان Mode ای که برنامه روی آن ساخته میشود، اگر برنامه بر روی Debug ساخته میشود تمامی موارد بعدی بر اساس دیباگ تعیین و در غیر اینصورت بر اساس نوع Release مشخص خواهند شد. نوع معماری خروجی در برنامه، باید توجه داشته باشید برنامههای 32 بیتی توسط کامپایلرهای x86 یا 32 بیتی تهیه میشوند و برنامههای 64 بیتی توسط کامپایلر های x64 که خود نیازمند سیستم و بستر برنامهنویسی میباشند که 64 بیتی هستند، یعنی اگر نیاز باشد برنامه شما 64 بیتی کامپایل شود ابتدا باید سیستم عامل و نسخه کامپایلر محیط توسعه از آن پشتیبانی کند. انواع ماژولهای استفاده شده در کتابخانه Qt مهم است، به عنوان مثال در حالت عادی ماژول Qt5Core نیاز است ولی اگر در پروژه شما از ماژولهای دیگری مانند Network استفاده شده باشد در این حالت نیاز خواهید داشت فایل یا ماژول مربوط به آن را وارد برنامه کنید که شامل Qt5Network میباشد که لیست کاملی از ماژولها را بر اساس نیاز در ادامه مشخص خواهیم کرد که بر چه اساسی چه نوع ماژول و چه فایلی باید همراه برنامه موجود باشد. شروع کامپایل و گسترش برنامه: معمولاً نسخه های آزمایشی یک محصول در حالت Debug جهت بررسی و آنالیز خطاهای موجود در آن میباشد که توسط تیم توسعهدهنده یا افرادی که میتوانند در باگ گیری آن همیاری نمایند استفاده خواهند کرد، بنابراین بر فرض اینکه ما قرار است یک نسخه استاندارد و نهایی از محصول را در اختیار کاربر قرار دهیم از حالت Release استفاده خواهیم کرد. در بخش Projects میتوان نوع کامپایلر و مسیر خروجی از آن را مشخص کرد، دقت کنید که در این بخش قسمت Build بر روی حالت Release باشد، در این مثال ما از کامپایلر MSVC2017 و نسخه ۶۴ بیتی آن استفاده کردهایم که مسیر خروجی آن مشخص است. همانند مک و لینوکس در ویندوز نیز ابزاری با نام windeployqt وجود دارد که در مسیر QTDIR/bin/windeployqt میباشد. توسط این ابزار میتوان برنامه را در قالب یک پکیج جمع آوری و مستقر ساخت. برای مثال ما برنامه ای ساخته ایم که در مسیر مورد نظر MyAppRoot//C:/Users/Compez/Desktop میباشد. با دستور cd به مسیر فوق خواهیم رفت: cd C:/Qt/Qt5.11.0/5.11/msvc2017_64/MyAppRoot البته قرار است در این مسیر خروجی فایل بعد از کامپایل ایجاد شود که با غیر فعال سازی امکان Shadow Build این ممکن خواهد شد که فایل مربوطه در مسیر ریشه برنامه ایجاد شود. با فرض اینکه بعد از کامپایل فایل MyApplication.app در مسیر ذکر شده موجود باشد دستور زیر را در ترمینال وارد خواهیم کرد: C:/Qt/Qt5.11.0/5.11/msvc2017_64/bin/windeployqt MyApplication.exe دقت کنید که اگر نیاز باشد با استفاده از گزینههای موجود در ابزار برنامه خود را مستقر سازید کافی است دستور ایجاد را به صورت زیر وارد کنید: C:/Qt/Qt5.11.0/5.11/msvc2017_64/bin/windeployqt MyApplication.app –verbose=3 –no-plugins در ویندوز بر خلاف ایستگاههای یونیکس فراهم آوردن تمامی فایلها در کنار برنامه صورت خواهد گرفت. اما بعد از اجرای دستور فوق برنامه به تنهایی قابل اجرا نخواهد٬ لذا فایلهای msvcp140.dll و vcruntime140.dl نیاز هستند تا در کنار برنامه قرار گیرند. این فایلها در تمامی نرمافزار های بزرگ در کنار برنامه موجود هستند مگر اینکه به صورت جدا پکیج مربوط به آن را نصب کنید که توصیه نمیشود. توجه داشته باشید که فایلهایی که قبل از پسوند .dll آخر حرف آنها به d ختم میشود نشانگر آن است که مربوط به نسخه دیباگ هستند. در صورتی که در حالت Release برنامه خود را کامپایل میکنید فایلهایی را در کنار برنامه خود قرار دهید که حرف آخر آنها به d ختم نشده باشد. برای مثال فایل QtCored.dll مخصوص نسخه دیباگ بوده و فایل QtCore.dll مخصوص نسخه ریلیز. بعد از کامپایل برنامه و اجرای خروجی آن در ویندوزی که بر روی آن Qt و سیپلاسپلاس نصب نیست مسلما با خطاهای زیر مواجه خواهیم شد: خطاهای فوق بیانگر این است که فایلهای فوق در کنار پروژه یا در هسته سیستم عامل پوشه windows/system32 و یا windows/SysWow64 نصب نشده است که در ادامه برای حل این خطا راهکار ارائه داده شده است. بنابراین به مسیر زیر بروید : C:/Program Files (x86)/Microsoft Visual Studio 2017/Enterprise/VC/Redist/14.x.x/onecore/x64/Microsoft.VC150.CRT سپس فایلهای موجود در پوشه را کپی و در کنار برنامه قرار دهید در این صورت برنامه بدون هیچ خطایی اجرا خواهد شد. مگر اینکه به جز کتابخانه Qt و STL از کتابخانههای دیگری استفاده کرده باشید که در این صورت هم باید فایلهای مربوط به آنها را در کنار برنامه قرار دهید. -
کتابخانه VTK یک کتابخانه مجسم سازی سه بعدی اطلاعات و پردازش تصویر است. این شامل یک کتابخانه کلاس C++ و چندین لایه رابط تفسیری از جمله Tcl / Tk، Java و Python است. VTK یک کتابخانه کراس پلتفرم است که از سیستمعاملهای لینوکس ، یونیکس ، مک و ویندوز پشتیبانی میکند. این ابزار پشتیبانی از پردازش موازی و ادغام با پایگاه های داده های مختلف در ابزارهای GUI مانند Qt و Tk را داراست. در سایت رسمی این کتابخانه به آدرس VTK - The Visualization Toolkit میتوانید منابع آموزشی متعددی برای یادگیری این کتابخانه پیدا کنید. برای استفاده از این کتابخانه نیاز به کامپایل سورس این کتابخانه داریم . برای دریافت سورس میتوانید از صفحه دانلود سایت رسمی VTK استفاده کنید. بعد از دریافت این کتابخانه میتوانید با توجه به سیستمعامل خود از صفحه wiki سایت رسمی VTK برای تنظیم و کامپایل این کتابخانه استفاده کنید. دقت نمایید اگر نیاز دارید که از فریمورک Qt در برنامه خود استفاده کنید و صفحات گرافیکی VTK را در پنجرههای Qt نمایش دهید باید به این مرحله پیکربندی با Cmake که مرتبط به کیوت 5 میباشد دقت کنید. بعد از کامپال و نصب کتابخانه میتوانید پروژه مثال استفاده از VTK و Qt در گیتهاب را اجرا کرده و صحیح بودن پیکربندی و ساخت کتابخانه را آزمایش کنید. برای یادگیری این کتابخانه میتوانید از کتاب یا ویدئو های موجود استفاده کنید ولی روش شخصی بنده برای یادگیری و استفاده از این کتابخانه در پروژه مشاهده و تحلیل مثالهای کتابخانه VTK بود. این مثال ها جزء به جزء برای هر قابلیت پیاده سازی شدهاند. در قسمت بعد روند کلی کارکرد این کتابخانه از روی سورس مثال معرفی شده از گیتهاب را برای شما عزیزان شرح میدهم.
-
ساخت یک کامپوننت آپلود در انگولار(Uploader Component) میتواند کار سختی باشد. به این دلیل که با فایل ها در جاوا اسکریپت سر و کار داریم. در این آموزش یک روش خوب را برای آپلود فایلها آموزش میدهم. به علاوه این که چطور از روند آپلود در لحظه خبر داشته باشیم و با نمایش درصد دادههای آپلود شده تجربهی خوبی را برای کاربران فراهم کنیم. نکته: در این آموزش من به مباحث سمت سرور و دریافت فایل توسط آن نمیپردازم و به این شکل در نظر میگیرم که شما سروری آمادهی دریافت فایل دارید. حالا در سمت کلاینت که انگولار 6 یا بالاتر است، میخواهیم این فایل را با یک درخواست از نوع POST به سمت سرور بفرستیم و در حین آپلود گزارشی از روند آپلود در انگولار را نمایش دهیم. در این مورد من از کامپوننتی (Component) از انگولار متریال به نام نوار پیشرفت (Progress Bar) استفاده میکنم. میتوانید نمونه نهایی این پروژه که برای آموزش ساخته شده را در مخزن گیتهاب مشاهده کنید. ساخت پروژه انگولار برای شروع، در دایرکتوری (Directory) مد نظر، پروژهی انگولار خود را با استفاده از رابط خط فرمان انگولار (Angular CLI) به نام آپلودر میسازیم. پس دستور زیر را وارد میکنیم: ng new uploader وابستگیهای خارجی از آنجایی که ما نیاز به عناصر پیچیدهی رابط کاربری (UI)، مثل نوار پیشرفت داریم؛ تصمیم گرفتم تا از کتابخانهی انگولار متریال استفاده کنیم. برای نصب این کتابخانه همچنین انیمیشنها از دو دستور زیر استفاده کنید: npm install --save @angular/material @angular/cdk npm install --save @angular/animations برای این که بتوانیم از سیاساس (CSS) این ماژول استفاده کنیم، لازم است که آن را در فایل استایل سراسری خود وارد (Import) کنیم: @import '~@angular/material/prebuilt-themes/deeppurple-amber.css'; ساخت ماژول (Module) امکانات برای این که کامپوننت خوب ما تا حد ممکن قابلیت استفادهی دوباره را داشته باشد، تصمیم گرفتم آن را در یک ماژول جدا بستهبندی کنم. برای ساخت این ماژول دستور زیر را استفاده کنید: ng generate module upload ساخت کامپوننت آپلود در انگولار برای ساخت کامپوننت آپلود کافی است از دستور زیر استفاده کنید. همانطور که از نام این کامپوننت مشخص است، برای آپلود فایلهای (File) خود از یک دیالوگ استفاده خواهیم کرد. ng generate component upload/dialog افزودن ماژولهای خارجی بعد، نیاز خواهیم داشت که تعداد زیادی ماژول خارجی را در ماژول جدید خود یعنی upload.module.ts وارد کنیم. برای مثال، نیاز داریم تا تمام عناصر رابط کاربریای که استفاده خواهیم کرد را به این شکل وارد کنیم: import { NgModule } from '@angular/core'; import { CommonModule } from '@angular/common'; import { HttpClientModule } from '@angular/common/http'; import { DialogComponent } from './dialog/dialog.component'; import { BrowserAnimationsModule } from '@angular/platform-browser/animations'; import { MatButtonModule, MatDialogModule, MatListModule, MatProgressBarModule } from '@angular/material'; @NgModule({ imports: [ CommonModule, HttpClientModule, BrowserAnimationsModule, MatButtonModule, MatDialogModule, MatListModule, MatProgressBarModule ], declarations: [DialogComponent], exports: [DialogComponent], entryComponents: [DialogComponent] }) export class UploadModule { } توجه کنید در صورتی که دقیقاً دستورهای گفته شده را وارد کردید، کامپوننت شما توسط CLI در ماژول upload تعریف خواهد شد. درصورتی که شما از ماژولی استفاده نمیکنید، کامپوننت جدید شما در فایل app.module.ts تعریف میشود. همچنین برای این که کامپوننت دیالوگ ما به خوبی کار کند لازم است تا آن را به عنوان EntryComponent در ماژول خود اضافه کنیم. این کار در ماژول نمونه بالا انجام شده است. حالا برای این که بتوانیم از کامپوننت جدید خود استفاده کنیم باید ماژول تعریف شده را در app.module.ts وارد کنیم تا به AppComponent اضافه شود. سرویس آپلود در انگولار قبل از ساخت محتوای نمایشی کامپوننت آپلودر، لازم است ابتدا منطق آپلود را پیادهسازی کنیم. این منطق در سرویس آپلود قرار خواهد گرفت. آن سرویس را با استفاده از دستور زیر ایجاد میکنیم: ng generate service upload/upload داخل این سرویس نیاز داریم تا از HttpClient استفاده کنیم. این سرویس تنها دارای یک تابع به نام upload خواهد بود و برای هر فایل یک Observable برمیگرداند. این Observable ها حاوی روند آپلود و درصد آن خواهد بود. /** * @description A Http request to upload files * @param file */ upload(file: File): Observable<any> { const formData: FormData = new FormData(); let url = ''; formData.append('video', file, file.name); url = 'http://localhost:1500/api/upload/videos'; const req = new HttpRequest('POST', url, formData, { reportProgress: true, responseType: 'text' }); const progress = new Subject<any>(); this.http.request(req).subscribe(event => { if (event.type === HttpEventType.UploadProgress) { const percentDone = Math.round(100 * event.loaded / event.total); progress.next({ percent: percentDone, loaded: event.loaded }); } else if (event instanceof HttpResponse) { progress.complete(); } }); return progress.asObservable(); } توجه داشته باشید که برای استفاده از این تابع باید موارد زیر را وارد کنید: import { HttpClient, HttpEventType, HttpResponse, HttpRequest } from '@angular/common/http'; import { Observable, Subject } from 'rxjs'; همچنین نمونهای از HttpClient را در سازنده (Constructor) کلاس تعریف میکنیم تا بتوانیم درخواست http ارسال کنیم: constructor(private http: HttpClient) { } در تابع آپلود، فایل دریافتی را در یک فرم بسته بندی کرده، یک درخواست http از نوع POST ساخته و آن درخواست را همراه با فرم به عنوان دادهی همراه درخواست ارسال میکنیم. سپس به روند آپلود فایل گوش میدهیم، درصد آپلود را محاسبه میکنیم و مقدار آن را به جریان داده پاس میدهیم. حالا برای فایل مورد نظر observable ای از روند آپلود را در اختیار داریم. سرانجام نیاز داریم تا آن سرویس را به عنوان provider در ماژول خود اضافه کنیم. برای این کار کافی است سرویس خود را در فایل ماژول وارد (Import) کنیم (اگر توسط CLI وارد نشده بود) و آن را به این صورت در قسمت providers ماژول معرفی کنیم: @NgModule({ imports: [ CommonModule, HttpClientModule, BrowserAnimationsModule, MatButtonModule, MatDialogModule, MatListModule, MatProgressBarModule ], declarations: [DialogComponent], exports: [DialogComponent], entryComponents: [DialogComponent], providers: [UploadService] }) export class UploadModule { } نکته: در پروژه نمونه برای این که در App Component از دکمههای متریال استفاده میشود، MatButtonModule را در قسمت exports هم قرار دادم. باز کردن دیالوگ آپلودر برای باز کردن دیالوگ در فایل .ts کامپوننت اصلی یعنی App ماژول دیالوگ و کامپوننت دیالوگ خود را وارد ( import) میکنیم: import { MatDialog } from '@angular/material'; import { DialogComponent } from './upload/dialog/dialog.component'; حالا در سازنده کلاس (constructor) نمونهٰای از MatDialog تعریف میکنیم: constructor(public dialog: MatDialog) { } با استفاده از تابع زیر میتوانید دیالوگ ساخته شده توسط خود را باز کنید. این تابع را در کلاس کامپوننت App قرار میدهیم: openDialog() { this.dialog.open(DialogComponent, { width: '720px' }); } برای استفاده از این تابع تنها کافی است آن را به رویداد (event) کلیک روی دکمه بایند (Bind) کنیم. پس عبارت زیر را روی تگ دکمهای که برای باز کردن دیالوگ در نظر گرفتهایم قرار میدهیم: (click)="openDialog()" اضافه کردن فایلها اولین کاری که باید در این قسمت انجام دهیم اضافه کردن یک عنصر input از نوع فایل به دیالوگ است. این عنصر input تنها راه تحریک منوی انتخاب فایل سیستم عامل برای باز شدن است. <input type="file" #file style="display: none" (change)="onFilesAdded()" multiple /> اما برای این که ظاهر زشتی دارد قرار است که آن را با استفاده از CSS مخفی کنیم. سپس آن را با استفاده از رویداد کلیک، از طریق منطق کامپوننت باز میکنیم. برای این کار در فایل ts کامپوننت یک ارجاع به آن عنصر نیاز داریم. برای این کار از دایرکتیوی (directive) به نام ViewChild استفاده میکنیم. همچنین متغیری نیاز داریم تا فایل را در آن ذخیره کنیم. همانطور که میبینید برای استفاده از سرویس آپلود نمونهای از آن را در سازنده کلاس تعریف کردهام. import { Component, OnInit, ViewChild } from '@angular/core'; import { UploadService } from '../upload.service'; @Component({ selector: 'app-dialog', templateUrl: './dialog.component.html', styleUrls: ['./dialog.component.scss'] }) export class DialogComponent implements OnInit { @ViewChild('file') file; addedFile; constructor(private uploadService: UploadService) { } ngOnInit() { } } حالا با شبیهسازی یک کلیک منوی انتخاب فایل سیستم عامل را باز میکنیم. addFiles() { this.file.nativeElement.click(); } طبق عنصر input که بالاتر نوشتهام، هنگامی که انتخاب فایل توسط کاربر انجام شد تابعی به نام onFilesAdded صدا زده میشود که شکل زیر را دارد: onFilesAdded() { this.addedFile = this.file.nativeElement.files[0]; console.log('Added File:', this.addedFile); } حالا فایل ذخیره شده را داریم که آمادهی آپلود است برای آپلود تابعی را تعریف کرده و از سرویسی که قبلا تهیه کردیم استفاده میکنیم. برای آن که درصد فایل آپلود شده و مقدار دادهی آپلود شده را داشته باشیم دو متغیر جدید تعریف میکنیم و به شکل زیر درصد آپلود و مقدار داده آپلود شده را بدست میآوریم: upload() { const progress = this.uploadService.upload(this.addedFile); progress.subscribe((result) => { this.percent = result.percent; this.loaded = result.loaded; }); } حالا برای مثال میتوانیم روند پیشرفت آپلود را به شکل زیر به نمایش بگذاریم: <mat-progress-bar mode="determinate" [value]="percent"></mat-progress-bar> نمونهی پروژهی آماده شده برای این آموزش را میتوانید از اینجا دریافت کنید. امیدوارم آموزش مفیدی بوده باشه. خوشحال میشوم نظرات شما را درباره این آموزش بدانم.
-
کامبیز اسدزاده یک موضوع را ارسال کرد در <span class="ipsBadge ipsBadge_pill" style="background-color: #e62f3d; color: #ffffff;" >برنامه نویسی در C و ++C</span>
با توجه به وجود کتابخانههای متعدد در سیپلاسپلاس در این پُست قصد داریم آموزشهایی در رابطه با نحوهٔ راه اندازی انواع کتابخانهها را در سیپلاسپلاس توضیح دهیم. محیطهای توسعه جهت نصب Visual Studio و Qt Creator خواهند بود. در صورتی که نیاز است کتابخانهای را به صورت سفارشی کامپایل کنید نکاتی را باید مورد توجه قرار دهید که در ادامه آمدهاند. قبل از هر چیز نیاز است توضیحاتی در رابطه با انواع کتابخانهها داده شود. کتابخانهها برای اینکه در پروژه مورد استفاده قرار بگیرند نیاز است آنها از سمت منبع خود کامپایل و ساخته شوند. البته در این فرآیند باید توجه داشته باشید که نوع معماری در پیکربندی یک کتابخانه بسیار مهم است. برای مثال اگر قرار است کتابخانهای را بر روی یک پروژهای که تحت معماری x64 پیکربندی شده است و در وضعیت release منتشر شود، در این صورت حتماً باید کتابخانه مورد نظر تحت همین پیکربندی کامپایل شود. کتابخانهها ممکن است خودشان وابستهٔ کتابخانههای دیگری باشند. برای مثال بخشی از ماژول کتابخانه Boost و Poco وابستهٔ کتابخانهٔ OpenSSL میباشد. و یا بخشی از کتابخانهٔ MySQL وابستهٔ کتابخانهٔ Boost میباشد. بنابراین قبل از پیکربندی پروژه تحت هر کتابخانهای مطمئن شوید که پیش نیازات آن را در اختیار داشته باشید. توجه داشته باشید که حتماً راهنمای کتابخانهٔ مورد نظر خود را جهت نحوهٔ پیکربندی مطالعه نمایید، زیرا هیچ روش عامیانهای وجود ندارد که بر روی تمامی کتابخانهها صادق باشد. با توجه به نکات بالا آموزش لازم جهت پیکربندی و راه اندازی کتابخانهها را تحت دو گزینهٔ Boost و MFSL ادامه میدهیم: نسخهٔ مورد نظر کتابخانهٔ مورد نظر را از این بخش دریافت کنید. فایل دریافت شده را استخراج و در یک مسیر مشخصی مانند C://کتابخانهٔ شماکپی کنید. محیط کنسول در سیستم عامل را باز کنید، پیشنهاد میشود از Visual Studio Cross Tools Command Prompt استفاده کنید. به مسیر کتابخانه تحت دستور cd رفته و وارد آن شوید. در این مرحله نیاز است تا قبل از ساخت کتابخانه آن را پیکربندی کنید، بنابراین دستور زیر را اجرا خواهیم کرد: ./configure دقت کنید که این مرحله معمولاً در کتابخانهها متفاوت میباشد، برای مثال در کتابخانهٔ Boost فایلی به نام bootstrap.bat متخص ویندوز و فایل bootstrap.sh برای محیطهای یونیکس موجود است که وظیفهٔ پیکربندی و تولید فایل ساخت را بر عهده دارد. البته در نظر داشته باشید که این چنین پیکربندی در کتابخانههای خاص ممکن است و در بیشتر آنها باید با دستورات configure و فلگهای موجود در هر یک از آنها اقدام به پیکربندی کنید. بنابراین با توجه این مورد میتوانید آموزش لازم را در این بخش پیگیری نمایید. بعد از پیکربندی دستور make، nmake، cmake و یا qmake متناسب با نوع ابزار سازنده باید اجرا شود تا کتابخانه بر اساس پیکربندی تنظیم شده شروع به کامپایل و ساخت کند. این مرحله معمولاً بر اساس قدرت پردازشی سیستم شما زمان متغیری خواهد داشت. بعد از به اتمام رسیدن زمان کامپایل کتابخانهٔ مورد نظر فایلهای lib را تحت پسوندهای .dll در ویندوز و .lib و .so در لینوکس و یونیکس تولید خواهد کرد که بهتر است مسیر include برای هدرهای کتابخانه و lib برای فایلهای کامپایل شده مشخص شود. طبق شرایط ذکر شده برای مثال ما از کتابخانهٔ SDL در این بخش استفاده خواهیم کرد. نسخهٔ از پیش کامپایل شده مربوط به آن را از این بخش دریافت و استخراج نمایید. قست اول (نصب و راه اندازی تحت محیط Visual Studio) وارد محیط ویژوال استودیو شده و بعد از ایجاد پروژه بر روی پروژه راست کلیک و گزینهٔ Properties را انتخاب کنید، به زبانه C/C++ رفته و زبانه General گزینهٔ Additional Include Directories را انتخاب کنید. در ادامه مسیر include را از کتابخانهٔ SDL به پروژه معرفی کنید. مرحله کنونی را تایید کنید، و به زبانهٔ Linker و سپس General بروید، در این بخش گزینهٔ Additional Linker Library را انتخاب و مسیر Lib را از کتابخانهٔ SDL معرفی کنید. در این مرحله فایلهای کتابخانه معرفی شدهاند. به زبانهٔ General و Input برگشته و در بخش Additional Dependences فایلهای SDL2.lib و SDL2_image.lib و SDL2main.lib و SDL2_ttf.lib را معرفی کنید. در نهایت فایلهای dll موجود در پوشهٔ lib کتابخانه را در کنار فایل اجرایی کپی کنید. قست دوم (نصب و راه اندازی تحت محیط Qt Creator) پروژه خود را ایجاد و بر روی نام پروژه راست کلیک کنید. گزینهٔ Add Library و سپس External Library را بزنید. طبق شرایط قبل گزینههای lib را همراه با include به پروژهٔ خود اضافه نمایید. کد مربوط به فایل .pro به صورت زیر خواهد بود win32: LIBS += -L$$PWD/../../../../SDL2-2.0.8/lib/x86/ -lSDL2 -lSDL2main -lSDL2_ttf INCLUDEPATH += $$PWD/../../../../SDL2-2.0.8/lib/x86 DEPENDPATH += $$PWD/../../../../SDL2-2.0.8/lib/x86 طبق روش کامپایل برنامه را کامپایل کنید و قبل از اجرا فایلهای dll یا lib را نسبت به پلتفرم خود در کنار فایل اجرایی پروژه قرار دهید. https://iostream.ir/forums/topic/33-روش-افزودن-کتابخانههای-دیگر-به-محیط-qt-creator/ روش فوق در بیشتر کتابخانهها قابل انجام است. -
با درود و خسته نباشید خدمت اساتید. به عنوان یه برنامه نویس مشتاق به c++ خیلی علاقه دارم اگر امکانش باشه اساتید یه دوره حرفه ای آموزش ارتباط c++ با qml در زمینه های مختلف رو استارت بزنند. آموزش هایی که واقعا درک ما کسانی که مشتاق به برنامه نویسی c++ در qml هست رو بالا ببره. qml توانایی خاصی در خلق رابط کاربری داره ولی این c++ هست که به این مساله قابلیت - انعطاف پذیری و سرعت میبخشه. اگر ملاک ما اسناد خود qt باشه میتونیم این مساله رو پیش ببریم اما با سرعت بسیار کم. پس اگر اساتید علاقه ای در این زمینه داشته باشند چه بهتر با زبان فارسی بشه حرکتی کرد تا فصل جدیدی از برنامه نویسی مدرن رقم بخوره. ممنون





