















مهندسی ویژگیها
مهندسی ویژگیها (FE) بخش بزرگی از یادگیری ماشین (ML) و یادگیری عمیق است. مقاله فوق را برای آشنایی بیشتر با اینکه ویژگی مهندسی چگونه به توسعهدهنگان در کار با داده کمک میکند مطالعه کنید.
دادهها بدون توجه به اندازه و مقایس کسبوکارهای مُدرن، شرکتها و سازمانها به عنوان دارایی از نوع طبقه-اولِ آنها تبدیل شده است. هر سیستم هوشمند، صرف نظر از پیچیدگی آن، باید بر اساس داده باشد. در قلب هر سیستم هوشمند، ما یک یا چند الگوریتم بینش دادهای را بر اساس مجموعهای از دادههای یادگیری، مانند یادگیری ماشین، یادگیری عمیق و یا روشهای آماری استفاده میکنیم که این اطلاعات را برای جمع آوری دانش و ارائه بینش هوشمند بیش از یک دوره زمانی نیاز داریم. الگوریتمها خودشان کاملاً مجزا کار میکنند و نمیتوانند خارج از جعبه دادههای خام که برای آنها مشخص شده است کار کنند.
هر سیستم بینش اطلاعاتی هوشمند، اساساً شامل یک خط یا نقطهٔ سر-به-سر با استفاده از دادههای خام برای استفاده از تکنیکهای پردازش دادهها جهت گردآوری، پردازش و خواص ویژگیهای مهندسی از این دادهها است. ما معمولاً تکنیکهایی مانند مُدلهای آماری یا مدلهای یادگیری ماشین را برای مدل سازی بر روی این ویژگیها استفاده میکنیم و در صورت لزوم برای استفاده آنها در آینده بر اساس مشکلاتی که میتوان به آنها اشاره کرد به صورت دستی حل میشوند. به طور معمول یک سامانهٔ یادگیری ماشین مبتنی بر «فرایندهای استاندارد صنعت متقابل برای دادهکاوی» در زیر نشان داده شده است.
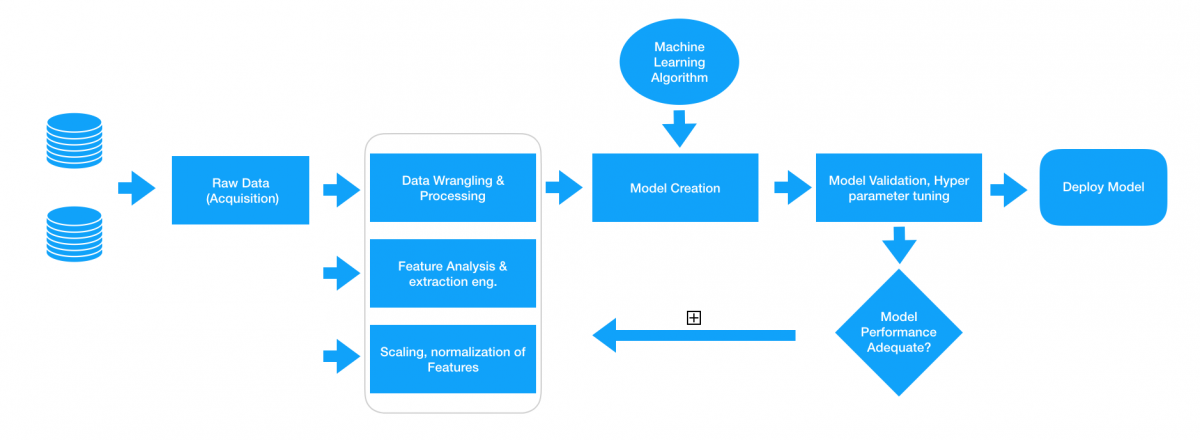
به دست آوردن دادههای خام و ساختن مُدل بر روی این دادهها به طور مستقیم میتواند به عنوان عملی بیمورد تلقی شود، زیر ما نتایج و کارایی مورد نظر را نمیگیریم و همچنین الگوریتمها خود به طور خودکار ویژگی معنی دار از دادههای خامِ ساده را به صورت خودکار نمایش نمیدهند. جنبهٔ تهیه دادها در شکل بالا ذکر شده است، جایی که ما متودولوژیهای مختلفی را برای استخراج ویژگیها یا ویژگیهای معنی دار از دادههای خامِ پس از تجزیه و تحلیل مورد نیاز از پیش رونده و پیش پردازش برخورد میکنیم. مهندسی ویژگی یک هنر و همچنین یک عِلم است و به همین دلیل دانشمندانِ دادهها اغلب ۷۰٪ از زمان خود را در مرحله آماده سازی دادهها قبل از فازِ مُدل سازی صرف میکنند.
نقل قولنقل قول از (Dr. Jason Brownlee) مهندسی ویژگی فرایند تبدیل دادههای خام به ویژگیهایی است که مشکلات پیش بینی شدهٔ مدلهای اصلی را بهتر نشان میدهد در نتیجه دقتِ مُدل را در دادههای غیر قابل مشاهده بهبود میبخشد.
این به ما درکِ (بینشِ) این را میدهد که چرا ویژگی مهندسی یک فرایند تبدیل اطلاعات (دادهها) به یک ویژگی به عنوان ورودی برای مُدلهای یادگیری ماشین عمل میکند. یعنی آن ویژگی با کیفیتِ خوب در بهبود عملکرد کلی و دقت مُدل کمک میکند.
ویژگی ها نیز به سوالات اصلی و اساسی بسیار وابسته هستند. بنابراین، حتی ممکن است کار یادگیری ماشین در سناریوهای متفاوت مانند طبقهبندی رویدادهای IoT به رفتارهای عادی و غیر طبیعی یا طبقهبندی احساسات مشتری، ویژگیهای استخراج شده در هر سناریو بسیار متفاوت از یکدیگر عمل کند.
ویژگیها چه چیزهایی هستند؟
یک ویژگی، به طور معمول، یک نمایش خاص در رأس دادههای خام است که خصوصیات قابل اندازهگیری آن به صورت منحصربفرد (خصوصی) است. که معمولاً در یک ستون از یک مجموعه داده نقش بسته اند. با توجه به یک مجموعهای از دادههای دو بعدی، هر مشاهده توسط یک ردیف و هر ویژگی توسط یک ستون نشان داده میشود که یک مقدار خاص برای مشاهده دارد.
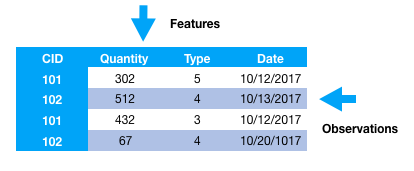
بنابراین، مانند مثال در شکل بالا، هر سطر به طور خاص یک ویژگی از بُردار را نشان میدهد و همه آنها مجموعهای از ویژگیها در همه مشاهدات به شمار میآیند، همچنین یک ماتریس ویژگی دو بُعدی است، که به عنوان یک مجموعهای از ویژگیها شناخته میشود. این شبیه به قاب دادهها یا صفحات گستردهای است که داده های دو بعدی را نشان میدهند.
به طور معمول، الگوریتمهای یادگیری ماشین با این ماتریسهای عددی یا تانسورها کار میکنند. از این رو بیشترین تکنیکهای ویژگیهای مهندسی تبدیل دادههای خام به عنوان نمایندهای از دادههایی که میتوانند توسط این الگوریتم ها قابل فهم و درک باشند را انجام میدهد. ویژگیها میتوانند از دو نوع اصلی بر اساس مجموعه دادهها باشند. ویژگیهای خام (خالص) ذاتی مستقیماً از مجموعه دادهها و بدون دستکاری اطلاعات و یا مهندسی اضافی به دست میآیند. ویژگیهای مشتق شده معمولاً از ویژگیهای مهندسی به دست میآیند، جایی که ویژگیهای دادههای موجود را از آن استخراج میکنیم.
مهندسی ویژگیها
دادههای عددی معمولاً دادهها را به شکل ارزشهای اسکالِر نشان میدهند که مشاهدات، ضبط دادهها یا اندازه گیری آنها را نشان میدهد. منظور ما در اینجا دادههای عددی به عنوان دادههای مستمر است نه گُسَسته که به طور معمول به عنوان اطلاعات طبقه بندی شده ارائه میشوند. دادههای عددی میتوانند به عنوان یک بُردار از مقادیر نشان داده شود که هر مقدار یا موجودیت بُردار میتواند خود یک ویژگی خاص را نشان دهد. عدد صحیح (Integer) و شناور (Float) رایج ترین و به طور گستردهای از انواع دادههای عددی برای دادههای عددی مُداوم استفاده میشوند. حتی داده های عددی میتوانند به طور مستقیم به مُدل های یاد گیری ماشین انتقال یابند. شما برای هر یک از سِناریوهای مربوطه نیاز به ویژگیهایِ مهندسی دارید که مربوط به مشکلات و حوزهٔ مرتبط با آنها برای ساخت یک مُدل است. از این رو، نیاز به مهندسی ویژگیها هنوز هم در جای خود باقی است.
0 دیدگاه
نظرهای پیشنهاد شده
هیچ دیدگاهی برای نمایش وجود دارد.